







xgboost梳理复习总结,及常见面试题
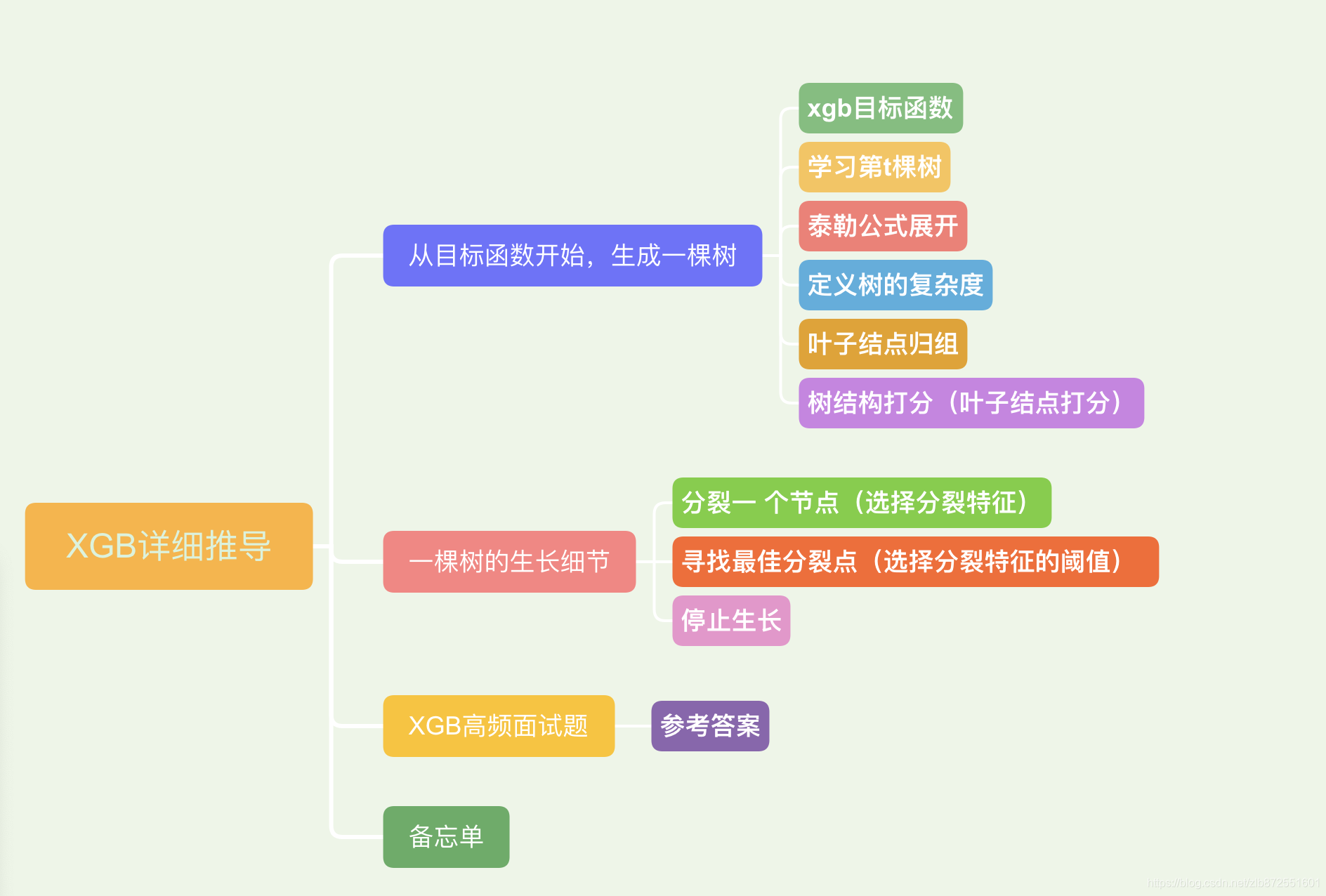
以上是xgb回忆的思维导图
首先要明确的是,xgb一定是boosting的算法,所以第t+1棵树一定是在第t棵树上的基础上生成的,第t+1棵树还在拟合第t棵树未拟合好的残差,这点在上面的思维导图中没有体现到,上面的导图着重于一棵树内部的生成过程。
这里重点介绍或者说温习XGBoost的推导过程,文末会抛出10道面试题考验一下自己和各位,最后准备了一份“XGB推导攻略图”,帮助更好的掌握整个推导过程。
01从“目标函数”生成一棵树
1.xgb的目标函数
xgb的目标函数由训练损失和正则化项两部分组成,(这算是xgb的特点之一,因为rf和原始gbdt的目标函数都是没正则化项的,相当于在模型训练的树生成过程中就考虑到了过拟合)
目标函数定义如下:
o
b
j
=
∑
i
=
1
n
l
(
y
i
,
y
i
^
)
+
∑
k
=
1
K
Ω
(
f
k
)
obj=\sum_{i=1}^{n}l(y_{i},\hat{y_{i}})+\sum_{k=1}^{K}\Omega(f_k)
obj=∑i=1nl(yi,yi^)+∑k=1KΩ(fk)
其中分别用红色箭头表明训练损失和正则化项两部分的组成

变量解释:
1.l代表损失函数,这里会用到:
平方损失:
l
(
y
i
,
y
i
^
)
=
(
y
i
−
y
i
^
)
2
l(y_i,\hat{y_i})=(y_i-\hat{y_i})^{2}
l(yi,yi^)=(yi−yi^)2
逻辑回归损失:
l
(
y
i
,
y
i
^
)
=
y
i
l
n
(
1
+
e
−
y
i
^
)
+
(
1
−
y
i
)
l
n
(
1
+
e
y
i
^
)
l(y_i,\hat{y_i})=y_i ln(1+e^{-\hat{y_i}})+(1-y_i)ln(1+e^{\hat{y_i}})
l(yi,yi^)=yiln(1+e−yi^)+(1−yi)ln(1+eyi^)(这行不知道对不对,可以不看,很少用)
2.
y
i
^
\hat{y_i}
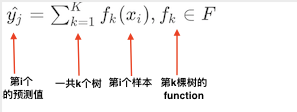
yi^是第i个样本的预测值,由于xgb是一个boosting的加法模型,因此,预测打分是每棵树打分的累加之和。
y
j
^
=
∑
k
=
1
K
f
k
(
x
i
)
,
f
k
∈
F
\hat{y_{j}}=\sum_{k=1}^{K}f_k(x_i),f_k \in F
yj^=∑k=1Kfk(xi),fk∈F
其中用红色箭头表示了各部分含义
3.将全部k棵树的复杂度进行求和,添加到目标函数中作为正则化项,防止模型过拟合。
∑
k
=
1
K
Ω
(
f
k
)
\sum_{k=1}^{K}\Omega(f_k)
∑k=1KΩ(fk)
2.学习第t棵树
在上面【1】的部分提到,xgb是个加法模型,假设我们第t次迭代要训练的树模型是
f
t
(
)
f_t()
ft(),则有:
y
i
^
(
t
)
=
∑
k
=
1
K
f
k
(
x
i
)
=
y
i
^
(
t
−
1
)
+
f
t
(
x
i
)
\hat{y_{i}}^{(t)}=\sum_{k=1}^{K}f_k(x_i)=\hat{y_{i}}^{(t-1)}+f_t(x_i)
yi^(t)=∑k=1Kfk(xi)=yi^(t−1)+ft(xi)

将上式带入【1】的目标函数obj中,得到:
o
b
j
(
t
)
=
∑
i
=
1
n
l
(
y
i
,
y
i
^
(
t
)
)
+
∑
i
=
1
t
Ω
(
f
i
)
x
=
∑
i
=
1
n
l
(
y
i
,
y
i
^
(
t
−
1
)
+
f
t
(
x
i
)
)
+
Ω
(
f
t
)
+
c
o
n
s
t
a
n
t
obj^{(t)}=\sum_{i=1}^{n}l(y_i,\hat{y_i}^{(t)})+\sum_{i=1}^{t}\Omega(f_i)x\\ =\sum_{i=1}^{n}l(y_i,\hat{y_i}^{(t-1)}+f_t(x_i))+\Omega(f_t)+constant
obj(t)=i=1∑nl(yi,yi^(t))+i=1∑tΩ(fi)x=i=1∑nl(yi,yi^(t−1)+ft(xi))+Ω(ft)+constant

注意上式中,只有一个变量,那就是第t棵树,
f
t
(
)
f_t()
ft()。
其他变量都是已知量,或者可以通过已知量可以求出来的(这里注意理解哦)。
所以,细心的我们可以发现,这里我们将正则化项也进行了拆分,由于前t-1棵树的结构是已确定的,所以前t-1棵树的复杂度之和就能用一个常量代替表示:
3.泰勒公式展开
简单回忆一下,泰勒公式:
泰勒公式是将一个在 x = x 0 x=x_0 x=x0处具有n阶导数的函数f(x),利用关于 ( x − x 0 ) (x-x_0) (x−x0)的n次多项式来逼近函数的方法。
泰勒公式的二阶展开形式如下:
f
(
x
+
Δ
x
)
≈
f
(
x
)
+
f
′
(
x
)
Δ
x
+
1
/
2
!
∗
f
′
′
(
x
)
Δ
x
2
f(x+\Delta{x}) \approx f(x)+f^{\prime}(x)\Delta{x}+1/2! *f^{\prime\prime}(x)\Delta{x}^{2}
f(x+Δx)≈f(x)+f′(x)Δx+1/2!∗f′′(x)Δx2
回到我们的问题上来,
l
(
y
i
,
y
i
^
(
t
−
1
)
+
f
t
(
x
i
)
)
l(y_i,\hat{y_i}^{(t-1)}+f_t(x_i))
l(yi,yi^(t−1)+ft(xi)) ,
y
i
,
y
i
^
(
t
−
1
)
y_i,\hat{y_i}^{(t-1)}
yi,yi^(t−1) 是已知的x.
f
t
(
x
i
)
f_t(x_i)
ft(xi)是一级附加的
Δ
x
\Delta{x}
Δx
f(x)对应我们的损失函数l(),x对应我们的t-1棵树的预测值,
Δ
x
\Delta{x}
Δx对应我们正在训练的第t棵树。
首先我们定义损失函数l()关于
y
^
(
t
−
1
)
\hat{y}^{(t-1)}
y^(t−1)的一阶偏导数和二阶偏导数:
g
i
=
∂
y
^
(
t
−
1
)
l
(
y
i
,
y
^
(
t
−
1
)
)
,
h
i
=
∂
y
^
(
t
−
1
)
2
l
(
y
i
,
y
^
(
t
−
1
)
)
g_i=\partial_{\hat{y}^{(t-1)}}l(y_i,\hat{y}^{(t-1)}),h_i=\partial^{2}_{\hat{y}^{(t-1)}}l(y_i,\hat{y}^{(t-1)})
gi=∂y^(t−1)l(yi,y^(t−1)),hi=∂y^(t−1)2l(yi,y^(t−1))
这里插一句,如果就是平方损失(比较常用),
l
(
y
i
,
y
i
^
)
=
(
y
i
−
y
i
^
)
2
l(y_i,\hat{y_i})=(y_i-\hat{y_i})^{2}
l(yi,yi^)=(yi−yi^)2
那么,
g
i
=
∂
y
^
(
t
−
1
)
l
(
y
i
,
y
^
(
t
−
1
)
)
=
2
(
y
i
−
y
i
^
(
t
−
1
)
)
,
h
i
=
∂
y
^
(
t
−
1
)
2
l
(
y
i
,
y
^
(
t
−
1
)
)
=
−
2
g_i=\partial_{\hat{y}^{(t-1)}}l(y_i,\hat{y}^{(t-1)})=2(y_i-\hat{y_i}^{(t-1)}),\\ h_i=\partial^{2}_{\hat{y}^{(t-1)}}l(y_i,\hat{y}^{(t-1)})=-2
gi=∂y^(t−1)l(yi,y^(t−1))=2(yi−yi^(t−1)),hi=∂y^(t−1)2l(yi,y^(t−1))=−2
这样对吗?
(注意xgb梯度计算中用到的是上一次的预测值,
这里就有一个问题,那么对于第一次计算梯度时,根本没有上一次的预测值怎么办?所以才有了一个全局偏置的超参,base_score:初始化预测分数,全局偏置。用于提供第一次梯度的计算。
xgb梯度计算中用到的不是本轮的预测值,所以对于分裂点计算前,各样本的一阶导和二阶导都是计算好的)
那么,我们的损失函数就由此转化为了下式(标出了与泰勒公式中x和
Δ
x
\Delta{x}
Δx的对应关系)。
l
(
y
i
,
y
i
^
(
t
−
1
)
+
f
t
(
x
i
)
)
=
l
(
y
i
,
y
i
^
(
t
−
1
)
)
+
g
i
f
t
(
x
i
)
+
1
2
h
i
f
t
2
(
x
i
)
l(y_i,\hat{y_i}^{(t-1)}+f_t(x_i))=l(y_i,\hat{y_i}^{(t-1)})+g_if_t(x_i)+\dfrac{1}{2}h_if_{t}^{2}(x_i)
l(yi,yi^(t−1)+ft(xi))=l(yi,yi^(t−1))+gift(xi)+21hift2(xi)

将上述的二阶展开式,带入到【2】中到目标函数obj中去,可以看到目标函数到近似值:
o
b
j
(
t
)
≈
∑
i
=
1
n
[
l
(
y
i
,
y
i
^
(
t
−
1
)
)
+
g
i
f
t
(
x
i
)
+
1
2
h
i
f
t
2
(
x
i
)
]
+
Ω
(
f
t
)
+
c
o
n
s
t
a
n
t
obj^{(t)} \approx \sum_{i=1}^{n}[l(y_i,\hat{y_i}^{(t-1)})+g_if_t(x_i)+\dfrac{1}{2}h_if_t^{2}(x_i)]+\Omega(f_t)+constant
obj(t)≈∑i=1n[l(yi,yi^(t−1))+gift(xi)+21hift2(xi)]+Ω(ft)+constant
去掉全部常数项,得到 最终用于训练和优化的目标函数:
o
b
j
(
t
)
≈
∑
i
=
1
n
[
g
i
f
t
(
x
i
)
+
1
2
h
i
f
t
2
(
x
i
)
]
+
Ω
(
f
t
)
obj^{(t)} \approx \sum_{i=1}^{n}[g_if_t(x_i)+\dfrac{1}{2}h_if_t^{2}(x_i)]+\Omega(f_t)
obj(t)≈∑i=1n[gift(xi)+21hift2(xi)]+Ω(ft)
其中,
g
i
=
∂
y
^
(
t
−
1
)
l
(
y
i
,
y
^
(
t
−
1
)
)
,
h
i
=
∂
y
^
(
t
−
1
)
2
l
(
y
i
,
y
^
(
t
−
1
)
)
g_i=\partial_{\hat{y}^{(t-1)}}l(y_i,\hat{y}^{(t-1)}),h_i=\partial^{2}_{\hat{y}^{(t-1)}}l(y_i,\hat{y}^{(t-1)})
gi=∂y^(t−1)l(yi,y^(t−1)),hi=∂y^(t−1)2l(yi,y^(t−1))
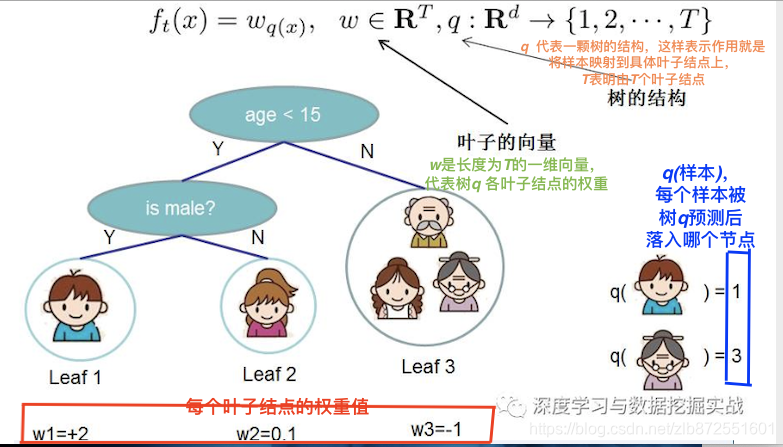
4.定义一颗树,即定义 f t ( ) f_t() ft()
我们定义一棵树,包括两部分:
1.叶子结点的权重w,(这个相当于就我们的预测值的一部分,所以很重要)
2.实例->叶子结点的映射关系q(这个相当于是树的分支结构,让我们确定每个样本走到哪个叶子节点上去,从而再拿该叶子节点的权重w)
一棵树的表达形式定义如下:
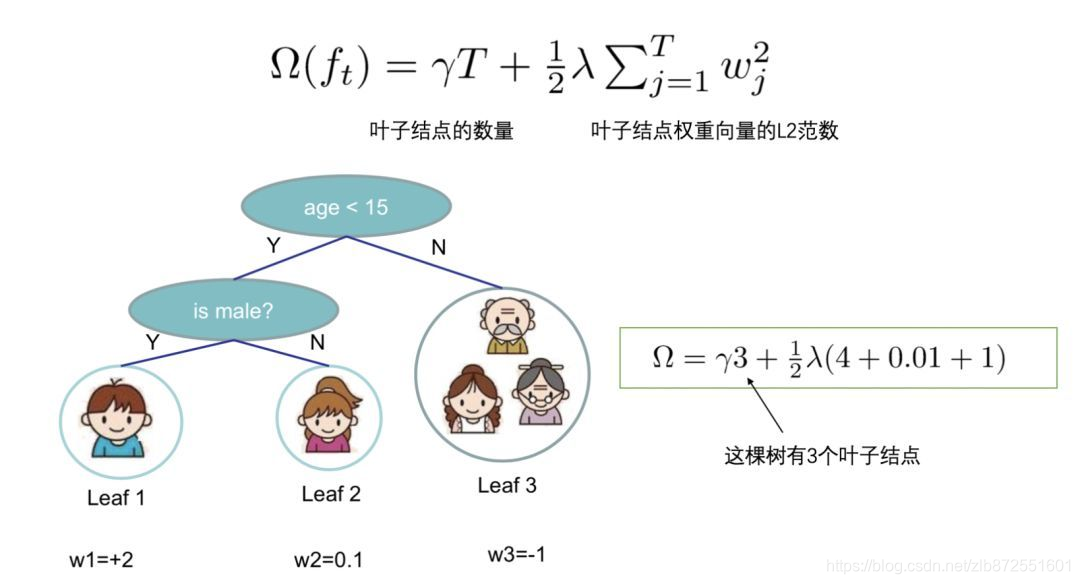
5定义树的复杂度
我们定义一棵树的复杂度
Ω
\Omega
Ω由两部分组成:
1.叶子结点的数量
2.叶子结点权重向量的L2范数
6叶子结点归组
我们将属于第j个叶子结点的所有样本
x
i
x_i
xi都划入到一个叶子结点的样本集中,数学表示如下:
I
j
=
{
i
∣
q
(
x
i
)
=
j
}
I_{j}=\{i|q(x_i)=j\}
Ij={i∣q(xi)=j}
然后,我们将【4】和【5】中一棵树及树的复杂度的定义,带入到【3】中泰勒展开后的目标函数obj中,具体推导如下:
o
b
j
(
t
)
≈
∑
i
=
1
n
−
1
[
g
i
f
t
(
x
i
)
+
1
2
h
i
f
t
2
(
x
i
)
]
+
Ω
(
f
t
)
=
∑
i
=
1
n
−
1
[
g
i
f
t
(
x
i
)
+
1
2
h
i
f
t
2
(
x
i
)
]
+
γ
T
+
λ
1
2
∑
j
=
1
T
w
j
2
=
∑
j
=
1
T
[
(
∑
i
∈
I
j
g
i
)
w
j
+
1
2
(
∑
i
∈
I
j
h
i
+
λ
)
w
j
2
]
+
γ
T
obj^{(t)} \approx \sum_{i=1}^{n-1}[g_if_t(x_i)+\dfrac{1}{2}h_if_t^{2}(x_i)]+\Omega(f_t)\\ = \sum_{i=1}^{n-1}[g_if_t(x_i)+\dfrac{1}{2}h_if_t^{2}(x_i)]+\gamma T+\lambda \dfrac{1}{2} \sum_{j=1}^{T}w_{j}^{2}\\ =\sum_{j=1}^{T}[(\sum_{i \in I_{j}} g_i)w_j + \dfrac{1}{2}(\sum_{i \in I_{j}} h_i+\lambda)w_j^{2} ]+\gamma T
obj(t)≈i=1∑n−1[gift(xi)+21hift2(xi)]+Ω(ft)=i=1∑n−1[gift(xi)+21hift2(xi)]+γT+λ21j=1∑Twj2=j=1∑T[(i∈Ij∑gi)wj+21(i∈Ij∑hi+λ)wj2]+γT

T的含义是有多少个分组,即有多少个叶子节点。
为了进一步简化该式,我们进行了如下的定义:
G
j
=
∑
i
∈
I
j
g
i
,
H
j
=
∑
i
∈
I
j
h
i
G_j=\sum_{i \in I_{j}} g_i,H_j=\sum_{i \in I_{j}} h_i
Gj=∑i∈Ijgi,Hj=∑i∈Ijhi
含义如下:
1.
G
j
G_j
Gj:叶子结点j 所包含所有样本的一阶偏导数的累加之和,是个常量
2.
H
j
H_j
Hj:叶子结点j 所包含所有样本的二阶偏导数的累加之和,是个常量
将
G
j
,
H
j
G_j,H_j
Gj,Hj带入到目标式子obj,得到我们那的最终目标函数,也就是论文中的目标函数,
(注意,这时该式子中的变量之剩下了第t棵树的权重向量W了):
能到这里真的好开心:
o
b
j
(
t
)
=
∑
j
=
1
T
[
(
∑
i
∈
I
j
g
i
)
w
j
+
1
2
(
∑
i
∈
I
j
h
i
+
λ
)
w
j
2
]
+
γ
T
=
∑
j
=
1
T
[
G
i
w
j
+
1
2
(
H
i
+
λ
)
w
j
2
]
+
γ
T
obj^{(t)} =\sum_{j=1}^{T}[(\sum_{i \in I_{j}} g_i)w_j + \dfrac{1}{2}(\sum_{i \in I_{j}} h_i+\lambda)w_j^{2} ]+\gamma T \\ =\sum_{j=1}^{T}[G_iw_j + \dfrac{1}{2}(H_i+\lambda)w_j^{2} ]+\gamma T
obj(t)=j=1∑T[(i∈Ij∑gi)wj+21(i∈Ij∑hi+λ)wj2]+γT=j=1∑T[Giwj+21(Hi+λ)wj2]+γT
7.树结构打分
回忆一下高中数学知识,假设有一个一元二次函数,形式如下:
G
x
+
1
2
H
x
2
,
H
>
0
Gx+ \dfrac{1}{2}Hx^{2},H>0
Gx+21Hx2,H>0
我们可以套用一元二次函数的最值公式轻易的求出,最佳点和最值:
x
∗
=
−
b
2
a
=
G
H
,
y
∗
=
4
a
c
−
b
2
4
a
=
−
1
2
G
2
H
x^{*}=-\dfrac{b}{2a}=\dfrac{G}{H},y^{*}=\dfrac{4ac-b^{2}}{4a}=-\dfrac{1}{2}\dfrac{G^2}{H}
x∗=−2ab=HG,y∗=4a4ac−b2=−21HG2
那么回到我们的最终的目标函数obj,该如何求出它的最值呢?
o
b
j
(
t
)
=
∑
j
=
1
T
[
G
i
w
j
+
1
2
(
H
i
+
λ
)
w
j
2
]
+
γ
T
obj^{(t)} =\sum_{j=1}^{T}[G_iw_j + \dfrac{1}{2}(H_i+\lambda)w_j^{2} ]+\gamma T
obj(t)=j=1∑T[Giwj+21(Hi+λ)wj2]+γT
简单分析一下上面的式子:
对于每个结点,我们都可以将其从目标式子obj中拆解出来:
G
i
w
j
+
1
2
(
H
i
+
λ
)
w
j
2
G_iw_j + \dfrac{1}{2}(H_i+\lambda)w_j^{2}
Giwj+21(Hi+λ)wj2
在【6】中我们提到,
G
i
,
H
i
G_i,H_i
Gi,Hi相对于第t棵树来说是可以计算出来的,那么,这个式子就是一个只包含一个变量 叶子结点权重
w
j
w_j
wj的一元二次函数,上面也提到了,我们可以通过最值公式求出最值点和最值。
再次分析一下目标函数,可以发现,各叶子结点的目标子式都是相互独立的,也就是说,只有当每个叶子结点的子式子都达到最值点,整个目标函数式子obj才会达到最佳点。
那么,假设目前树的结构已经固定,套用一元二次函数的最值公式,我们可以轻易求出,每个叶子结点的权重
w
j
∗
w_j^{*}
wj∗及此时,达到的最优的obj的目标值:
w
j
∗
=
−
G
j
H
j
+
λ
,
o
b
j
∗
=
−
1
2
∑
j
=
1
T
G
j
2
H
j
+
λ
+
γ
T
w_j^{*}=-\dfrac{G_{j}}{H_{j}+\lambda},obj^{*}=-\dfrac{1}{2}\sum_{j=1}^{T}\dfrac{G_j^{2}}{H_j+\lambda}+\gamma T
wj∗=−Hj+λGj,obj∗=−21j=1∑THj+λGj2+γT
实例演示:
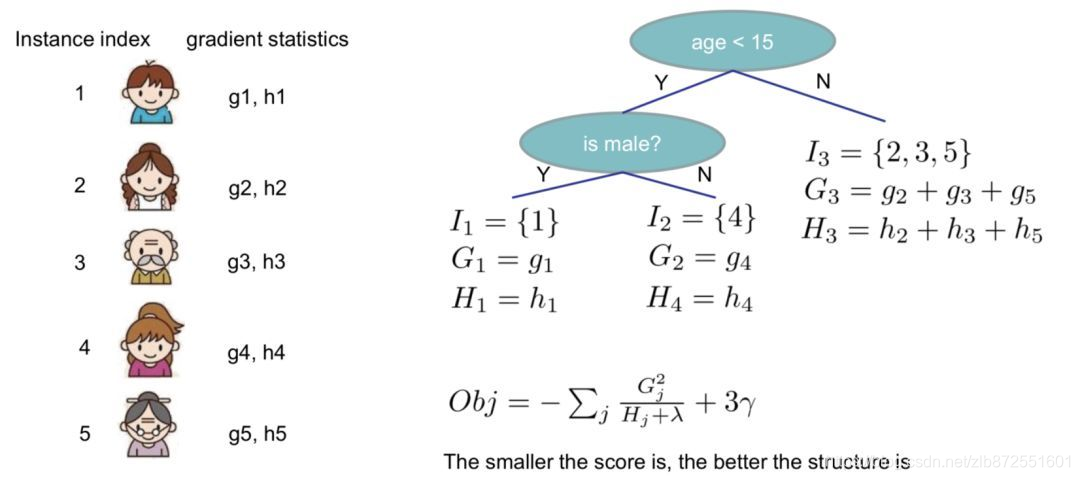
02 一棵树的生长细节
1分裂一个结点
在实际训练过程中,当建立第t颗树时,XGB采用贪心进行树节点的分裂:
从树深为0开始,:
1.对树种的每个节点开始尝试分裂;
2.每次分裂后,原来的一个叶子节点继续分裂为左右两个子叶子节点,原叶子节点中的样本集根据该节点的判断规则分散到左右两个叶子节点中;
3.新分裂一个节点后,我们需要检测这次分裂时候会给损失函数带来增益,(注意xgb梯度计算中用到的是上一次的预测值,而不是本轮的计算值,所以对于分裂点计算前,各样本的一阶导和二阶导都是计算好的)
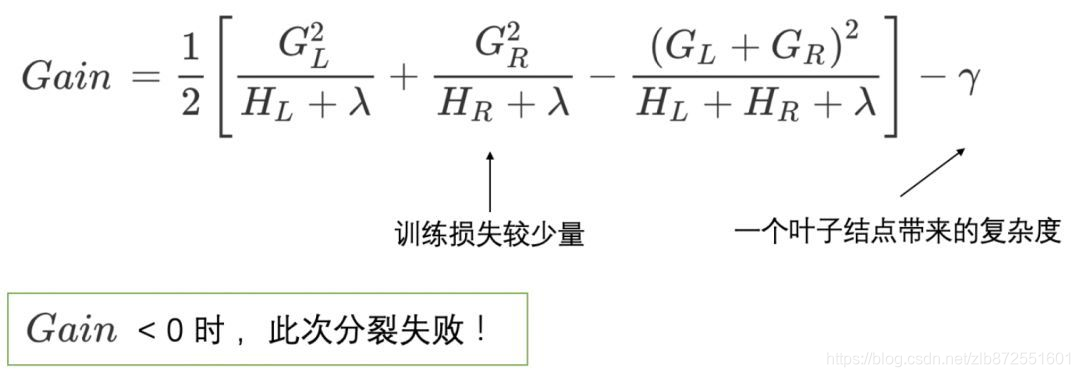
增益大小的定义如下,
G
a
i
n
=
o
b
j
L
+
R
−
(
o
b
j
L
+
o
b
j
R
)
=
[
−
1
2
(
G
L
+
G
R
)
2
H
L
+
H
R
+
λ
+
λ
]
−
[
−
1
2
(
G
L
2
H
L
+
λ
+
G
R
2
H
R
+
λ
)
+
2
λ
]
=
1
2
[
G
L
2
H
L
+
λ
+
G
R
2
H
R
+
λ
−
(
G
L
+
G
R
)
2
H
L
+
H
R
+
λ
]
−
λ
Gain=obj_{L+R}-(obj_{L}+obj_{R})\\ =[-\dfrac{1}{2}\dfrac{(G_{L}+G_{R})^{2}}{H_L+H_R+\lambda}+\lambda]-[-\dfrac{1}{2}(\dfrac{G_{L}^2}{H_L+\lambda}+\dfrac{G_{R}^2}{H_R+\lambda})+2\lambda]\\ =\dfrac{1}{2}[\dfrac{G_{L}^2}{H_L+\lambda}+\dfrac{G_{R}^2}{H_R+\lambda}-\dfrac{(G_{L}+G_{R})^{2}}{H_L+H_R+\lambda}]-\lambda
Gain=objL+R−(objL+objR)=[−21HL+HR+λ(GL+GR)2+λ]−[−21(HL+λGL2+HR+λGR2)+2λ]=21[HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2]−λ
如果增益Gain大于0,>0,我们会考虑此次分裂的结果。
但是,在一个节点分裂点时,可能有多个分裂点,每个分裂点都会产生一个增益,如何才能找到最优的分裂点呢,接下来会讲到。
2寻找最优分裂点
在分裂一个节点时,我们会有许多的候选分割点,寻找最佳分割点的大致过程是:
1.遍历每个节点的每个特征,
2.对每个特征,按特征值大小将特征值排序
3.线性扫描,找出每个特征的最佳分裂特征值
4.在所有特征中找出最后的分裂点(分裂后增益最大的特征及特征值)
上面是一种贪心的方法,每次分裂尝试都要遍历一遍所有的候选分割点,这也叫全局扫描,但是当数据量过大而导致内存无法一次载入或者在分布式的情况下,贪心算法的效率就会变得很低,全局扫描法不再适用。
基于此,xgb提出了一系列加快寻找最佳分裂点的方案:
1.特征预排序+缓存: xgb在训练之前,就预先对每个特征按照特征值大小进行了排序,然后保存了block结构,后面的迭代中会重复使用这个结构,使得计算量大大减小。
2.分位点近似法, 对每个特征按照特征值排序后,采用类似分位点选取的方式,仅仅选出常数个特征值作为该特征的候选分割点,在寻找该特征的最佳分割点时,只从候选分割点中选出最优的一个
3.并行查找, 由于各个特征已经预先存储为block结构,xgb支持利用多个线程来并行计算每个特征的最佳分割点,这不仅大大加快了节点的分裂计算,也利于大规模训练集的适应性扩展。
3停止生长
一棵树不能也不会一直生长下去,下面是一些常见的限制条件。
1.当新引入的一次分裂带来的增益gain<0,放弃当前的分裂,这是训练损失和模型结构复杂度的博弈过程。
G
a
i
n
=
1
2
[
G
L
2
H
L
+
λ
+
G
R
2
H
R
+
λ
−
(
G
L
+
G
R
)
2
H
L
+
H
R
+
λ
]
−
λ
Gain=\dfrac{1}{2}[\dfrac{G_{L}^2}{H_L+\lambda}+\dfrac{G_{R}^2}{H_R+\lambda}-\dfrac{(G_{L}+G_{R})^{2}}{H_L+H_R+\lambda}]-\lambda
Gain=21[HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2]−λ
Gain<0,此次分裂失败!
当训练损失的减小量小于<一个叶子节点带来的复杂度,此次分裂失败!
2.当树达到最大深度时,停止建树,因为树的深度太深太容易拟合所有样本,从而出现过拟合,这里需要设置一个超参,max_depth
3.当引入一次新分裂后,重新计算新生成的左右两个叶子的样本权重和,如果任一个叶子节点的y样本权重低于某一个阈值,也会放弃此次的分裂,这涉及到一个超参数,:最小样本权重,是指如果一个叶子节点包含的样本数量太少也会放弃分裂,防止树分的过细,这也是防止过拟合的常规操作
每个节点的样本权值和计算方式就是之前提到的:
w
j
∗
=
−
G
j
H
j
+
λ
w_j^{*}=-\dfrac{G_{j}}{H_{j}+\lambda}
wj∗=−Hj+λGj
还要讲什么?
3高频面试题
-
XGB与GBDT、随机森林等模型相比,有什么优缺点?
-
XGB为什么可以并行训练?
-
XGB用二阶泰勒展开的优势在哪?
-
XGB为了防止过拟合,进行了哪些设计?
-
XGB如何处理缺失值?
-
XGB如何分裂一个结点?如何选择特征?
-
XGB中一颗树停止生长的条件有哪些?
-
XGB叶子结点的权重有什么含义?如何计算?
-
训练一个XGB模型,经历了哪些过程?调参步骤是什么?
-
XGB如何给特征评分?
答案放下一篇
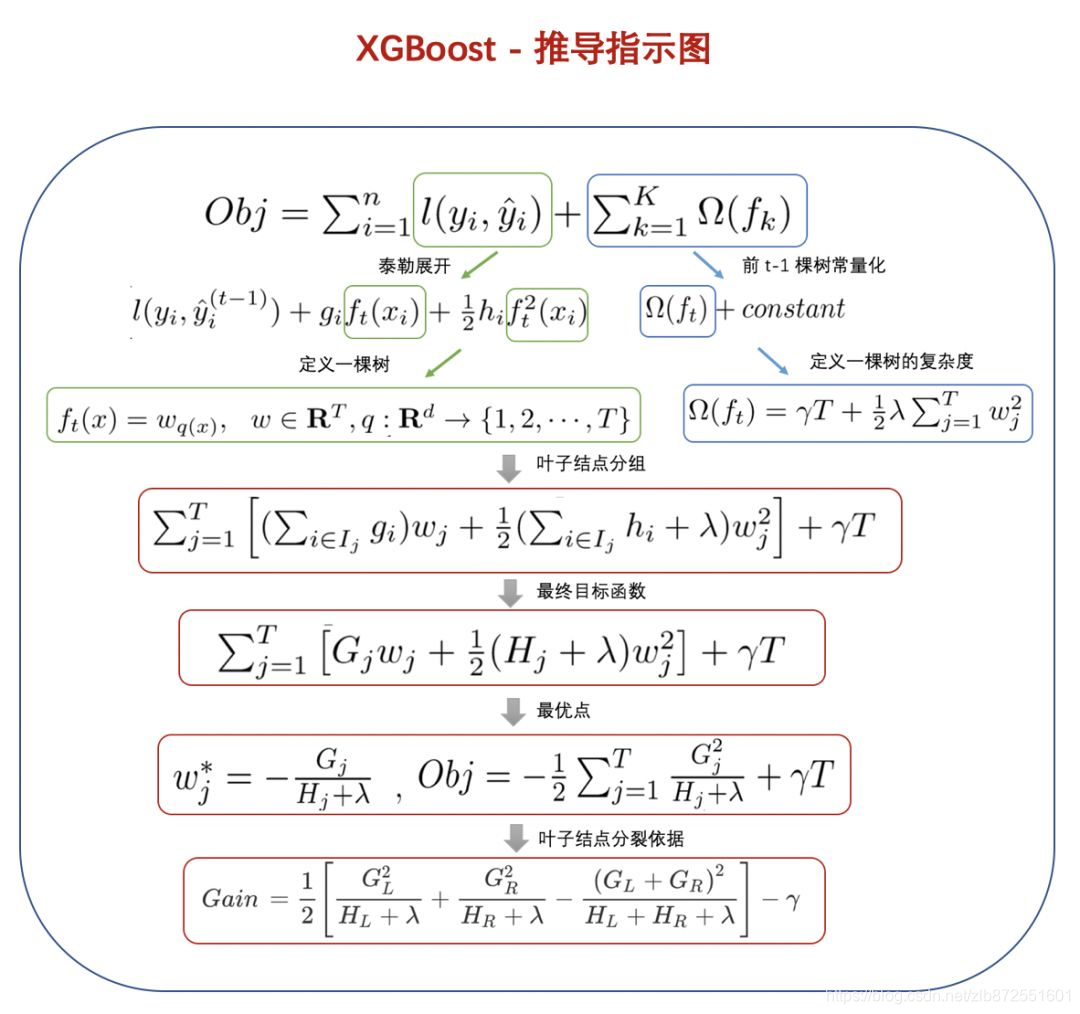
04备忘单
经过前面几个部分的细心讲解,相信大家对XGBoost底层原理已经很了解了,下面特意又准备了一份备忘单,希望能够帮助大家系统化的掌握XGB原理的整个推导过程,同时又能够起到快速回忆的作用。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









