




SGD方法的好处和失效的场景,以及解决办法
SGD方法的好处是,不必计算所有样本的梯度,
这样做的效果是快,快在两方面,一方面计算快,一方面是收敛快,
计算快好理解,只计算了一个样本的梯度,
收敛快是指,如果不是特别差的损失函数,(这里差是指难优化的意思),
假设数据量100w,那么全局梯度下降更新一次梯度的计算时间,sgd已经更新了100w次,所以到达收敛状态所需的时间更短了。
失效的场景:
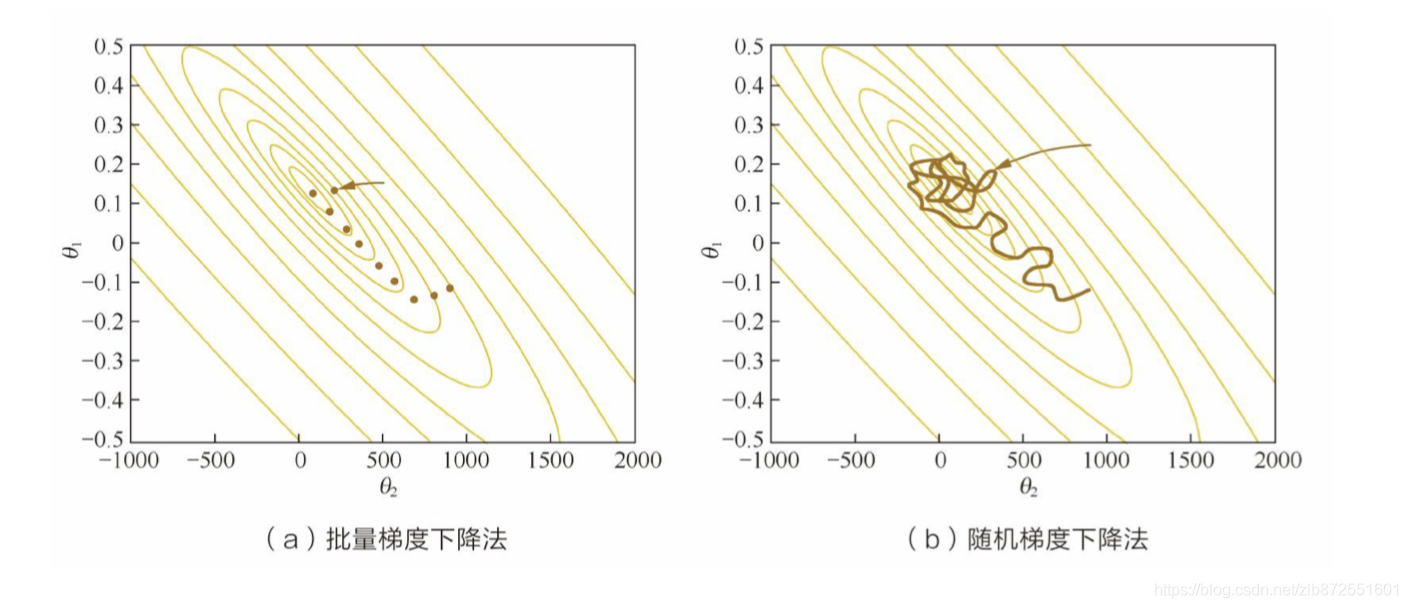
因为SGD在每一步放弃了对梯度准确性的追求,每步仅仅随机采样少量样本来计算梯度,计算速度快,内存开销小,但是由于每步接受的信息量有限,对梯度的估计出现偏差也在所难免,造成目标函数曲线收敛轨迹显得很不稳定,伴有剧烈波动,甚至有时出现不收敛的情况。图1展示了GD与SGD在优化过程中的参数轨迹,可以看到GD稳定地逼近最低点,而SGD曲曲折折简直是“黄河十八弯”。
 对SGD来说,可怕的不是局部最优点,而是两类地形——山谷和鞍点。
对SGD来说,可怕的不是局部最优点,而是两类地形——山谷和鞍点。
山谷指的是狭长的山间小道,左右两边是峭壁;
鞍点的形状像是一个马鞍,一个方向上两头翘,另一个方向上两头垂,而中心区域是一片近乎水平的平地。
在山谷的地形下,一般的SGD由于上面所说的缘故,会在小道两边的山壁上来回撞击,
(这时我们需要有惯性保持的能力,想有一股直接垂直下山的动力,从而减小左右来回撞这个方向上的动力)
在鞍点的地形下,SGD走入一片平坦之地(此时离最低点还很远),想象一下蒙着双眼只凭借脚底感觉坡度,如果坡度不明显那么很可能走错方向。SGD本来就对微小变化的梯度不敏感,所以在几近零的梯度区域,容易停滞下来,不再更新。
(这时我们需要有环境感知的能力 ,即使蒙上双眼,依靠前几次迈步的感觉,我们也应该能判断出一些信息,比如这个方向总是坑坑洼洼的,那个方向可能很平坦。这里如何获取前几步的感觉,数学上的形式就是考虑对最近的梯度综合利用,累加或者求平均,累加到一定程度,sgd就自然对周边边境有了更多的认识,容易找个一个正确的方向。SGD中,对环境的感知是指在参数空间中,对不同参数方向上的经验性判断,确定这个参数的自适应学习速率,即更新不同参数的步子大小应是不同的。)
所以,对sgd失效场景的分析,引出了梯度更新优化算法,都是基于惯性保持和环境感知这两个idea来的,
基本的sgd:
θ
t
+
1
=
θ
t
−
η
g
t
\theta_{t+1}=\theta_{t}-\eta g_{t}
θt+1=θt−ηgt
Momentum:
v
t
=
γ
v
t
−
1
+
η
g
t
v_{t}=\gamma v_{t-1}+\eta g_{t}
vt=γvt−1+ηgt
θ
t
+
1
=
θ
t
−
v
t
\theta_{t+1}=\theta_{t}-v_{t}
θt+1=θt−vt
看成Momentum:中每次前进的步子是
−
v
t
-v_{t}
−vt,前进步子
−
v
t
-v_{t}
−vt由两部分组成:(1) 学习速率
η
\eta
η和当前估计梯度
g
t
g_{t}
gt,(2) 衰减下的前一次步子
v
t
−
1
v_{t-1}
vt−1,系数
γ
\gamma
γ控制衰减前一次的步子。
可类比物理学中,速度与加速度,当前步子就是当前时刻速度,上一步的步子就是上一时刻的速度,而当前梯度就好比当前时刻受力产生的加速度,所以当前速度不仅与加速度(
g
t
g_{t}
gt)有关而且与上一时刻的速度(
v
t
−
1
v_{t-1}
vt−1)有关,系数
γ
\gamma
γ扮演来阻力的作用。
因此,与SGD相比,Momentum的收敛速度快,收敛曲线稳定。
AdaGrad:
名字中的Ada 注意体现在各维度的学习率不同,
历史上(累加的)梯度大的维度,学习率应该低一点,学慢一点(以免错误最佳点)
历史上(累加的)梯度小的维度,学习率应该大一点,学快一点(加快该维度上的收敛)
从而得到学习率应该与历史上(累加的)梯度成反比的想法,
数学形式是:
θ
t
+
1
,
i
=
θ
t
,
i
−
η
∑
k
=
0
t
g
k
,
i
2
+
ϵ
g
t
,
i
\theta_{t+1,i}=\theta_{t,i}-\dfrac{\eta}{\sqrt{\sum_{k=0}^{t}g_{k,i}^{2}+\epsilon}} g_{t,i}
θt+1,i=θt,i−∑k=0tgk,i2+ϵηgt,i
之所以用过往梯度平方和累加,而不是过往梯度平方和累加,主要考虑到,
退火的思想,即学习率只能是越来越小的单调减小的,而不可能变大,如果不加平方项,而采用
θ
t
+
1
,
i
=
θ
t
,
i
−
η
∑
k
=
0
t
g
k
,
i
+
ϵ
g
t
,
i
\theta_{t+1,i}=\theta_{t,i}-\dfrac{\eta}{\sum_{k=0}^{t}g_{k,i}+\epsilon} g_{t,i}
θt+1,i=θt,i−∑k=0tgk,i+ϵηgt,i这个式子,就会因为梯度有正有负,而不排除这个式子出现先小后大,后者先大后小的错误趋势。
Adam:
从名字一看就知道,Adam是个二合一的算法,结合AdaGrad的Ada和Momentum的m
机器学习中很多算法都是二合一或者三合一
Adam将惯性保持和环境感知两个有点都集于一身,一方面,Adam记录梯度的first moment一阶矩,即历史梯度和当前梯度的平均,这体现 来惯性保持,另一方面,Adam记录梯度的second moment二阶矩,即历史梯度平方和当前梯度平方的平均,这类似AdaGrad,体现了环境感知,提供二阶矩主要是为了为不同维度提供不同的学习率。
First moment和second moment求平均并不是直接累加,而是采用了类似滑动窗口内求平均的思想,把梯度分为,当前梯度和近一段时间内的梯度两类,并对两类梯度赋予不同权重,
m
t
=
β
1
m
t
−
1
+
(
1
−
β
1
)
g
t
m_t=\beta_{1} m_{t-1}+(1-\beta_{1}) g_{t}
mt=β1mt−1+(1−β1)gt
v
t
=
β
2
v
t
−
1
+
(
1
−
β
2
)
g
t
2
v_t=\beta_{2} v_{t-1}+(1-\beta_{2}) g_{t}^{2}
vt=β2vt−1+(1−β2)gt2
v
t
v_t
vt其实是区别各维度的
v
t
,
i
=
β
2
v
t
−
1
,
i
+
(
1
−
β
1
)
g
t
,
i
2
v_{t,i}=\beta_{2} v_{t-1,i}+(1-\beta_{1}) g_{t,i}^{2}
vt,i=β2vt−1,i+(1−β1)gt,i2
其中β1, β2为衰减系数。
如何理解Adam记录梯度的first moment一阶矩和second moment二阶矩,
其实也挺好理解的,
First moment相当于估计
E
[
g
t
]
E[g_{t}]
E[gt],由于当下梯度
g
t
g_t
gt是随机采样估计的结果(我们只拿了一个当前样本),比起
g
t
g_t
gt是我们更关心它在统计意义上的期望,也就是First moment一阶矩
E
[
g
t
]
E[g_{t}]
E[gt];
second moment相当于估计
E
[
g
t
2
]
E[g_{t}^{2}]
E[gt2],这点与AdaGrad不同,这里不是从开始到现在的累计和而是它的期望。
它们的物理意义是:
当一阶矩
m
t
m_t
mt的绝对值大且二阶矩
v
t
v_t
vt大时,梯度大且稳定,表明遇到一个明显的大坡,前进方向明确;
当一阶矩
m
t
m_t
mt的绝对值趋向0且二阶矩
v
t
v_t
vt大时,梯度不稳定,可能遇到一个峡谷,容易引起反弹震荡;
当一阶矩
m
t
m_t
mt的绝对值大且二阶矩
v
t
v_t
vt趋向0时,这种情况不存在;
当一阶矩
m
t
m_t
mt的趋向0且二阶矩
v
t
v_t
vt趋向0时,梯度趋零,可能到达局部最低点,也可能走到一片坡度极缓的平地,此时要避免陷入plateau高原上。
Adam还考虑
m
t
,
v
t
m_t, v_t
mt,vt在零初始值情况下的偏置矫正,所以加上了hat。Adam的更新公式为:
θ
t
+
1
,
i
=
θ
t
,
i
−
η
v
t
,
i
^
+
ϵ
m
t
,
i
^
\theta_{t+1,i}=\theta_{t,i}-\dfrac{\eta}{\sqrt{\hat{v_{t,i}}+\epsilon}} \hat{m_{t,i}}
θt+1,i=θt,i−vt,i^+ϵηmt,i^.
实际使用过程中,参数的经验值是
β1=0.9, β2=0.999
初始化:
m
0
=
0
m_0=0
m0=0、
v
0
=
0
v_0=0
v0=0
这个时候我们看到,在初期,
m
t
m_t
mt,
v
t
v_t
vt都会接近于0,这个估计是有问题的。因此我们常常根据下式进行误差修正:
m
t
^
=
m
t
1
−
β
1
2
\hat{m_t}=\dfrac{m_t}{1-\beta_{1}^{2}}
mt^=1−β12mt
v
t
^
=
v
t
1
−
β
2
2
\hat{v_t}=\dfrac{v_t}{1-\beta_{2}^{2}}
vt^=1−β22vt
这样很容易记住sgd, momentum, adagrad, adam各自算法的初衷和公式。
https://zhuanlan.zhihu.com/p/32262540
Adam那么棒,为什么还对SGD念念不忘 (2)—— Adam的两宗罪
提到,1,AdaGrad: 学习率一定是下降的,而Adam 的学习率不一定是下降的,
2,错过最优解,后期Adam的学习率太低,影响了有效的收敛,所以后期改sgd
另外一篇是 Improving Generalization Performance by Switching from Adam to SGD,进行了实验验证。他们CIFAR-10数据集上进行测试,Adam的收敛速度比SGD要快,但最终收敛的结果并没有SGD好。他们进一步实验发现,主要是后期Adam的学习率太低,影响了有效的收敛。他们试着对Adam的学习率的下界进行控制,发现效果好了很多。
于是他们提出了一个用来改进Adam的方法:前期用Adam,享受Adam快速收敛的优势;后期切换到SGD,慢慢寻找最优解。这一方法以前也被研究者们用到,不过主要是根据经验来选择切换的时机和切换后的学习率。这篇文章把这一切换过程傻瓜化,给出了切换SGD的时机选择方法,以及学习率的计算方法,效果看起来也不错。


















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









