



 本文介绍了不同版本的Visual Studio及其对应的VC版本,并详细展示了如何通过命令行查询GPU的计算能力,包括CUDACapabilityMajor/Minor版本号等关键信息。
本文介绍了不同版本的Visual Studio及其对应的VC版本,并详细展示了如何通过命令行查询GPU的计算能力,包括CUDACapabilityMajor/Minor版本号等关键信息。
(1)VisualStudio 版本
visual studio version(eg2022), release version(eg17.4.2), build version(eg17.4.33122.133)
visual studio version(eg2019), release version(eg16.11.21), build version(eg16.11.33027.164)
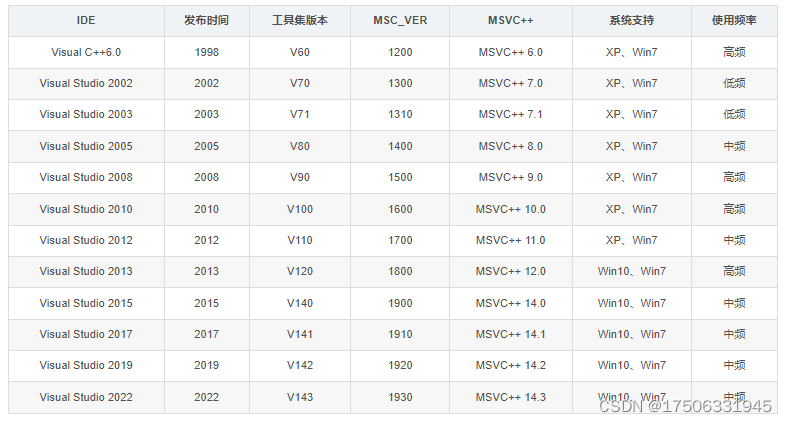
VC版本号 VS对应版本
vc6 VC6.0
vc7 VS2002
vc7.1 VS2003
vc8 VS2005
vc9 VS2008
vc10 VS2010
vc11 VS2012
vc12 VS2013
vc13 VS2014
vc14 VS2015
vc15 VS2017
vc16 VS2019
vc17 VS2022
Visual Studio 2022 build numbers and release dates
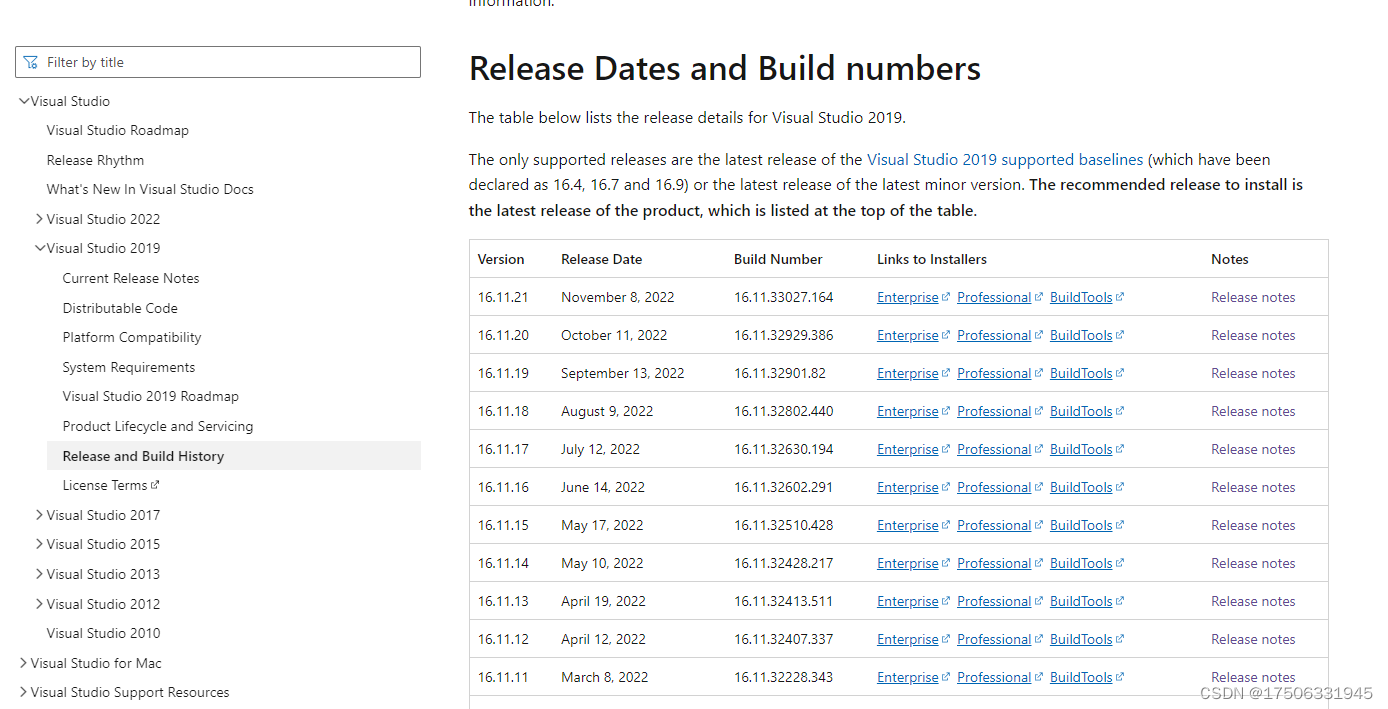
Visual Studio 2019 Release Dates and Build numbers

========================================================
=======================================================
(2)cuda下载
Table 1. CUDA Toolkit and Compatible Driver Versions
Table 2. Windows Compiler Support in CUDA 10.2
========================================================
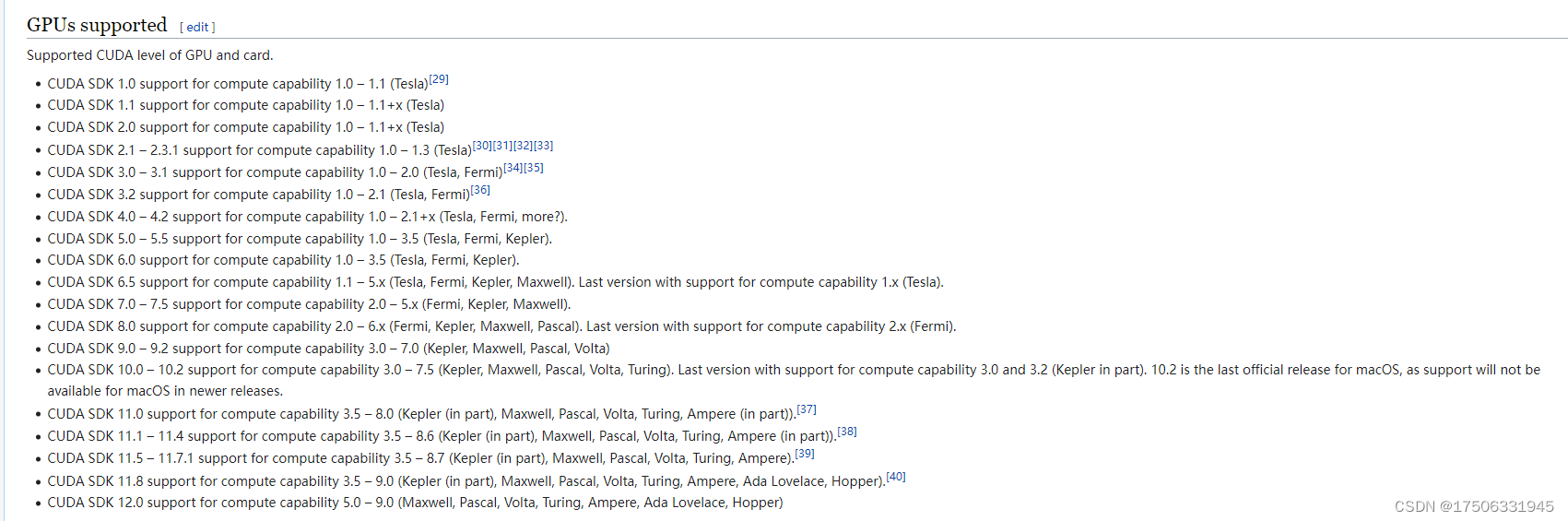
(3)GPU Compute Capability
官网查询
命令行
Microsoft Windows [版本 10.0.19044.2251]
(c) Microsoft Corporation。保留所有权利。
C:\Users\Administrator>cd C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\demo_suite
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\demo_suite>deviceQuery
deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Quadro RTX 3000"
CUDA Driver Version / Runtime Version 11.7 / 10.1
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 6144 MBytes (6442123264 bytes)
(30) Multiprocessors, ( 64) CUDA Cores/MP: 1920 CUDA Cores
GPU Max Clock rate: 1305 MHz (1.30 GHz)
Memory Clock rate: 6001 Mhz
Memory Bus Width: 192-bit
L2 Cache Size: 3145728 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: zu bytes
Total amount of shared memory per block: zu bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: zu bytes
Texture alignment: zu bytes
Concurrent copy and kernel execution: Yes with 6 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.7, CUDA Runtime Version = 10.1, NumDevs = 1, Device0 = Quadro RTX 3000
Result = PASS
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\demo_suite>

















 1079
1079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









