







历史发展
计算机视觉是通过分析、研究让计算机的智能化达到类似人类的双眼“看”的一门科学。更直接地说,计算机视觉就是让摄像机、电脑这些科技设备成为计算机的“眼睛”,让其可以拥有人类的双眼所具有的分割、分类、识别、跟踪、判别决策等功能。
1982年,马尔的《视觉》一书问世,标志着计算机视觉成为了一门独立学科。在40多年发展中,主要经历了三大历程:马尔计算视觉、多视几何与分层三维重建和基于学习的视觉。
马尔计算视觉马尔计算视觉分为三个层次,计算理论、表达和算法以及算法实现。马尔认为算法实现并不影响算法的功能和效果,所以马尔计算视觉主要讨论“计算理论”和“表达与算法”两部分内容。他认为,大脑的神经计算和计算机的数值计算没有本质区别,所以,马尔没有对“算法实现”进行任何探讨。
多视几何与分层三维重建该方面的工作主要集中在如何提高“大数据下鲁棒性重建的计算效率”。大数据需要全自动重建,而全自动重建需要反复优化,反复优化又需要花费大量计算资源。所以,如何保证鲁棒性的前提下快速进行大场景的三维重建是该领域研究的重点。
基于学习的视觉主要是指以机器学习为主要技术手段的计算机视觉研究。主要分为以svm、滤波、神经网络为代表的基本机器学习方法进行对图像的去噪、锐化、边缘检测、匹配等操作和以深度学习为代表的视觉方法。
近年里程碑
卷积神经网络
卷积神经网络(CNN)最早的正式面世应该是CNN之父Lecun在1998年提出,用于解决手写数字识别任务,这是一种从猫的视觉神经结构中得到灵感,进而模拟其结构设计出来的一种人工神经网络结构。通过卷积核来获取“感受野”范围内数据之间的关系特征。一张图片里,相邻的像素显然是有更强的相关性,相比于全连接神经网络,CNN突出了这种相邻的关系特征,因而更加准确的获取了图片内的有用信息。
ImageNet数据集
2009年,李飞飞教授等在CVPR2009上发布了ImageNet数据集[4],这是为了检测计算机视觉能否识别自然万物,克服过拟合问题,经过三年多在筹划组建完成的一个大的数据集。从10年-17年,基于ImageNet数据集共进行了7届ImageNet挑战赛,ImageNet是计算机视觉发展的重要推动者,和深度学习热潮的关键推动者,将计算机视觉领域的研究推向了新的高度。
残差网络ResNet
随着网络结构逐渐向越来越深的方向发展,大家直观地认为随着网络深度的增加,网络的特征拟合能力会越来越强,但是随即人们发现,随着网络深度的增加,模型的精度不是一直提升的,而且训练的误差和测试的误差都变高了,这显然不是过拟合的问题。何凯明团队认为这应该是一个优化问题,即随着网络的加深,网络优化会变得更加困难。提出了残差模块(ResNet),2015年ResNet在ImageNet上取得了非常惊艳的效果,作为神经网络发展史上具有里程碑意义的网络结构,一直到今天,残差结构都是各种模型中不可缺少的部分。
研究热点
据笔者了解,视觉Transformer、视觉大模型、基于深度学习的目标检测是计算机视觉目前的热点领域。
视觉Transformer
视觉Transformer的先驱工作是谷歌在 ICLR 2021 上发表的 ViT(Vision Transformer)[1],该工作把图像分成多个图像块(例如16x16像素大小),并把这些图像块比作NLP中的token。然后直接将标准Transformer编码器应用于这些 “token”,并据此进行图像分类。该工作结合了海量的预训练数据(如谷歌内部3亿图片分类训练库 JFT-300M),在 ImageNet-1K 的 validation 评测集上取得了88.55%的准确率,刷新了该榜单上的纪录。其结构为:
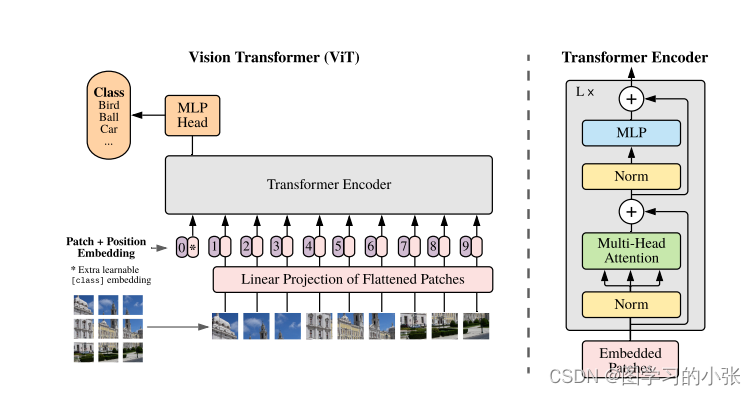
ViT 应用 Transformer比较简单直接,因为其没有仔细考虑视觉信号本身的特点,所以它主要适应于图像分类任务,但对于区域级别和像素级别的任务并不是很友好,例如物体检测和语义分割等。为此,学术界展开了大量的改进工作。其中,Swin Transformer [2] 的工作在物体检测和语义分割任务中大幅刷新了此前的纪录,让学术界更加确信 Transformer 结构将会成为视觉建模的新主流。
视觉大模型
近年来,随着通过大型语言模型(LLMs)的成功,在许多领域展现了先进的能力,包括语言理解、生成、推理和与代码相关的任务。视觉大模型的研究也非常火热,笔者接触比较多的主要是多模态领域的视觉大模型,CLIP[3]是其中的一个代表,其网络结构如图:
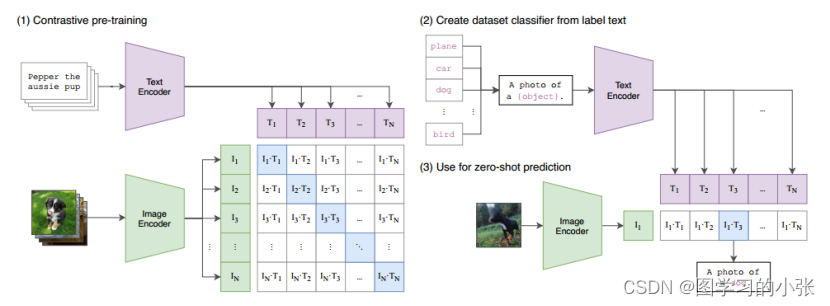
通过使用从网络收集的数百上千万图像-文本对进行预训练,这样的多模态模型具有两个巨大的优势:一个是图片和文本会被映射到一个相同的语义空间,一个是具有“zero-shot”学习的能力。因此,只需通过简单的自然语言描述和提示,这些预训练的基础模型完全被应用到下游任务,例如使用精心设计的提示进行零样本分类。
目标检测
目标检测是计算机视觉众多应用中的一个重要组成部分,横跨自主车辆、机器人、视频监控和增强现实等各个领域,从人尽皆知的YOLO模型就能看出该领域的火热程度。在深度学习出现之前,传统目标检测算法都是以手工设计特征为主,如 Sobel边缘检测特征、Haar特征等,这些特征的泛化能力较弱,在复杂场景中性能表现较差。基于深度学习的目标检测算法使用卷积神经网络学习特征,这种特征学习方式能自动发现检测及分类目标所需要的特征,同时通过卷积神经网络将原始输入信息转化成更抽象、更高维的特征,具有强大的特征表达能力和泛化性,所以其在复杂场景下的性能表现较好。
计算机视觉的未来
计算机视觉是人工智能的“眼睛”,是感知客观世界的核心技术。进入 21世纪以来,计算机视觉领域蓬勃发展,各种理论与方法大量涌现,并在多个核心问题上取得了令人瞩目的成果。
笔者认为,计算机领域的未来趋势是和基础算力的发展息息相关的,更深层、更大的神经网络无疑具有更强大的拟合能力,随着算力的不断提高,残差结构、Transformer等结构的提出,多模态中的图生文,文生图等预训练模型已经展示出了其无与伦比的性能,这些模型的应用已经给很多下游任务带来了巨大的提升。因此,大模型无疑是未来发展中的一个重中之重的领域。
但是,深度学习是一种需要大规模训练样本的技术,也只有这样才能发挥其最佳性能。对于大模型更是如此,可是在计算机视觉的现实应用中,很多问题并没有那么多标注数据,并且获取标注数据的成本也非常大。例如在医疗领域,需要有专业知识的医生来标注病灶位置;在工业领域,需要人工在不同光照强度下识别产品的瑕疵等。因此,如何在小样本情况下更加有效地训练深度学习模型,进而使得模型在目标识别地基础上具备一定的理解能力,这也是一个重要的研究课题和方向。
此外,基于与上文描述相同的原因,在未来的计算机视觉领域,也会出现更多的类似ImageNet这样的优秀数据集,供研究者们进一步验证和提高模型的泛化能力。
参考文献
[1].Dosovitskiy et al. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR 2021.
[2].Ze Liu,Yutong Lin,Yue Cao. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. ICCV 2021.
[3].Alec Radford,Jong Wook Kim,Chris Hallacy. Learning Transferable Visual Models From Natural Language Supervision.ICML 2021.
[4].Ji aDeng;Wei Dong;Richard Socher;ImageNet:A Large-Scale Hierarchical Image Database.CVPR 2009.
















 3503
3503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











