







Dataset
数据存储在csv文件中,每一行数据包含两个对象A,B的特征向量以及类标签
- 数据的第0列是类标签:类标签为1,表示A比B更有影响力,为0表示B比A更有影响力
- 特征向量是11个从twitter中获取的已预处理好的非负的数值型数据,1~11列是A的特征,12~22列是B的特征。

这是训练集中的一个特例,意味着每行的节点不是只出现一次,例如,A跟B比较,A还跟C比较,要充分理解数据。

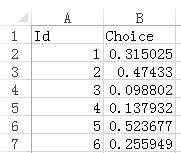
这是预测结果的示例,Id表示的是测试数据集中的比较的节点对的行号,Choice表示这个A的影响力占比,>0.5表示A比B更有影响力,反之B更有影响力。
Goal
- 目标是训练处一个机器学习模型,使得输入两个用户的特征数据,并可知道谁更有影响力。
Evaluation
- 评估的方法是ROC曲线ROC曲线下的面积,也就是AUC值。
In python (using the metrics module of scikit-learn):
fpr, tpr, thresholds = metrics.roc_curve(true_labels, predictions, pos_label=1)
auc = metrics.auc(fpr,tpr)First Submission
首先分析数据的组成,每一行是两个用户的特征向量以及其比较结果,因此,我将两个用户的特征向量的差值重新组成一个数据集,而标签就是这个差值向量的标签。再利用随机森林进行实验。具体代码如下:
# 创建训练数据集
import pandas as pd
import numpy as np
data = pd.read_csv('train.csv')
data_matrix = data.as_matrix()
train = np.zeros((len(data),12))
for i in range(len(data)):
if data_matrix[i][0] == 1.:
train[i][0] = 1
else:
train[i][0] = 0
train[i][1:] = data_matrix[i][1:12]-data_matrix[i][12:23]
train = pd.DataFrame(data=train, index=range(len(data)), columns=data.axes[1][0:12])# 特征筛选
import matplotlib.pyplot as plt
import numpy as np
from sklearn.feature_selection import SelectKBest, f_classif
features = train.axes[1][1:12]
# Perform feature selection
selector = SelectKBest(f_classif, k=5)
selector.fit(train[features], train["Choice"])
# Get the raw p-values for each feature, and transform from p-values into scores
scores = -np.log10(selector.pvalues_)
# Plot the scores.
plt.bar(range(len(features)), scores)
plt.xticks(range(len(features)), features, rotation='vertical')
plt.show()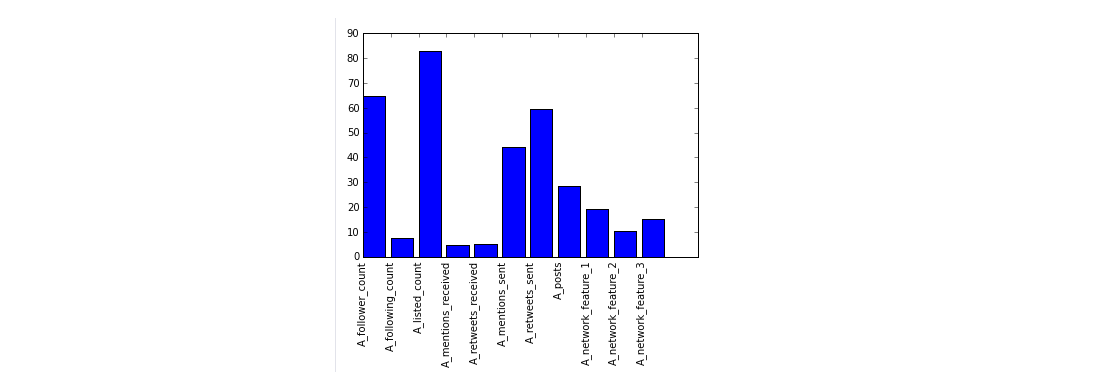
- 选择的特征如下:
features = ["A_follower_count","A_listed_count","A_mentions_sent","A_retweets_sent","A_posts","A_network_feature_1","A_network_feature_3"] - 首先对训练数据集进行分析
from sklearn import cross_validation
from sklearn.ensemble import RandomForestClassifier
alg = RandomForestClassifier(random_state=1, n_estimators=150, min_samples_split=4, min_samples_leaf=2)
scores = cross_validation.cross_val_score(alg, train[features], train["Choice"], cv=3)
print(scores.mean())
'''
output:
0.771818331994
'''- 然后对测试数据进行预测并保存结果到submission 中
# 对测试数据进行预测,采用的是随机森林算法
from sklearn import cross_validation
from sklearn.ensemble import RandomForestClassifier
data = pd.read_csv('test.csv')
data_matrix = data.as_matrix()
test = np.zeros((len(data),11))
for i in range(len(data)):
test[i] = data_matrix[i][0:11]-data_matrix[i][11:22]
test = pd.DataFrame(data=test, index=range(len(data)), columns=data.axes[1][0:11])
alg = RandomForestClassifier(random_state=1, n_estimators=150, min_samples_split=4, min_samples_leaf=2)
# Fit the algorithm using the full training data.
alg.fit(train[features], train["Choice"])
predictions = alg.predict_proba(test[features].astype(float))[:,1]
# Take the mean of the scores (because we have one for each fold)
submission = pd.DataFrame({
"Choice": predictions,
"Id": range(1,len(data)+1)
})
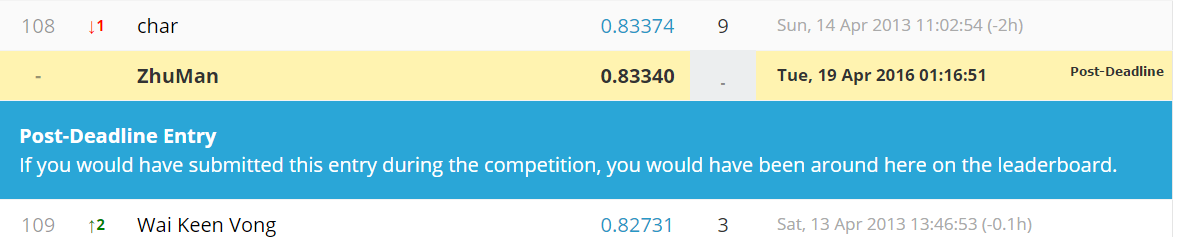
submission.to_csv("kaggle.csv", index=False)- 提交的结果如下(因为该比赛已结束,因此没有名次)















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









