







 偏好学习是机器学习的一个子领域,专注于通过已知偏好信息建立预测模型。主要任务包括偏好表达(如效用函数、部分/整体排名)、用户/物品描述等。排名误差的衡量方式有斯皮尔曼简捷法、Kendall's距离等。此外,文章还探讨了加权排名误差、二分排名问题以及多种偏好学习技术,如学习效用函数、构建偏好关系等。
偏好学习是机器学习的一个子领域,专注于通过已知偏好信息建立预测模型。主要任务包括偏好表达(如效用函数、部分/整体排名)、用户/物品描述等。排名误差的衡量方式有斯皮尔曼简捷法、Kendall's距离等。此外,文章还探讨了加权排名误差、二分排名问题以及多种偏好学习技术,如学习效用函数、构建偏好关系等。
Introduction
在维基百科中对Preference Learning的解释是这样的:通过已知的可观测的偏好信息构建一个偏好预测模型。偏好学习是机器学习的一个子领域,并且它的主要任务是学会进行排名(”learning to rank”)。
- 这张图显示了人工智能和偏好学习的关系以及偏好学习的应用领域

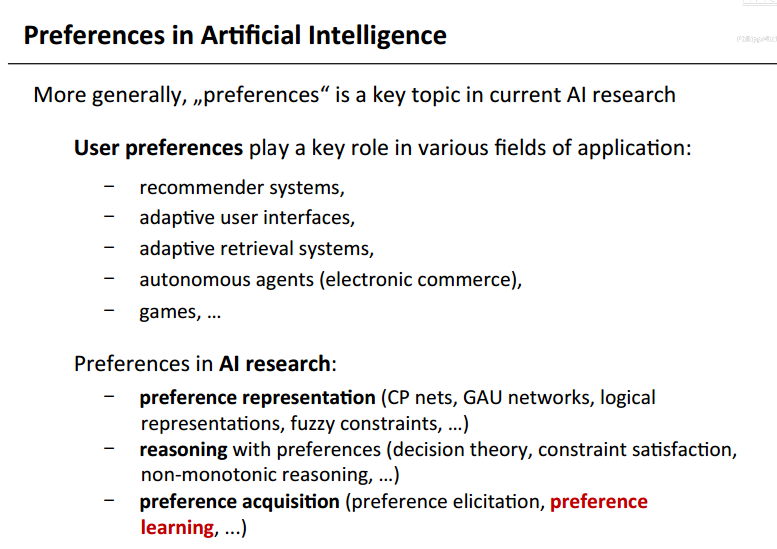
- 这张图显示了Preference 在人工智能中的应用
Preference Learning Task
偏好学习问题可以从好几个维度去学习:
- 偏好表达:
- 效用函数(utility function):数值型表达,或者按顺序表达
- 偏好关系:部分/整体排名(Ranking)
- 逻辑表示法…
- 用户/物品的描述:
- 标识符,特征向量,结构化对象…
- 训练数据集的类型:
- 直接/间接的信息反馈
- 完整/不完整的关系
- 公用程式(utilities)
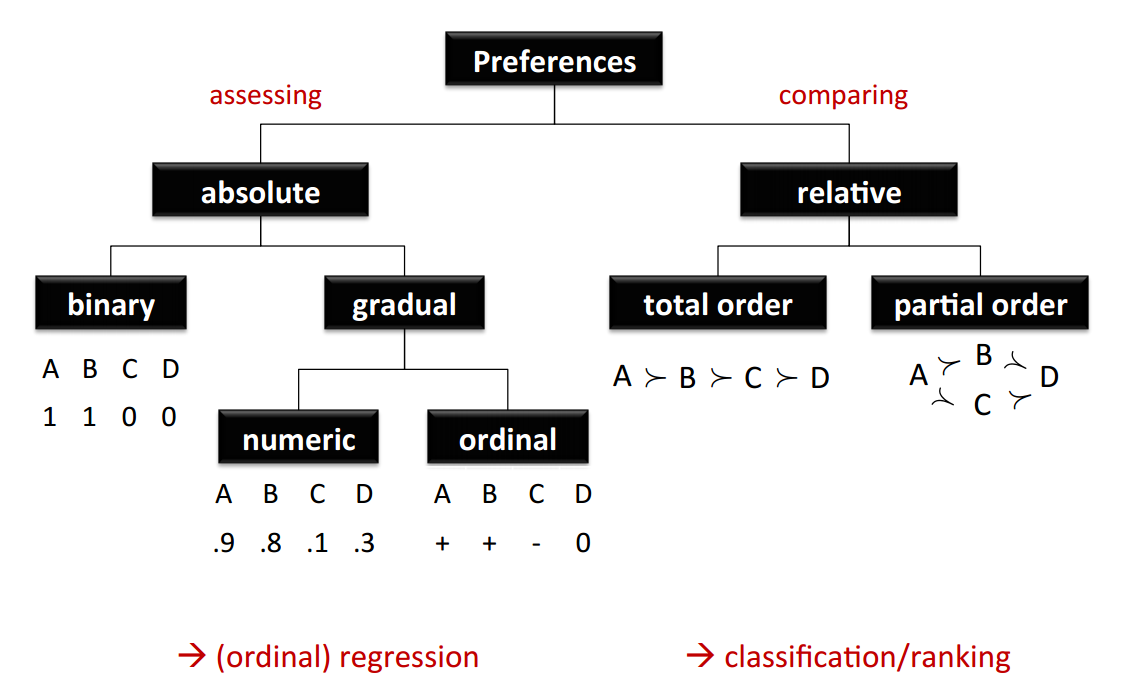
1)偏好表达
- 偏好的评估是绝对的,可以是二值型也可以是数值型或者枚举型的效用函数表达法。
- 偏好的比较是相对的,采用的是部分排名或者整体排名,是偏好关系表达法。
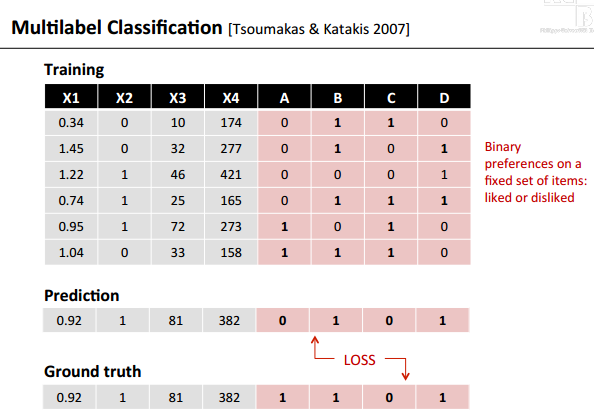
2)用户/物品的描述
- 在多标签分类问题中用户的描述是二值型数据,0表示不喜欢,1表示喜欢等。
- 它的预测结果也是二分类的数值。
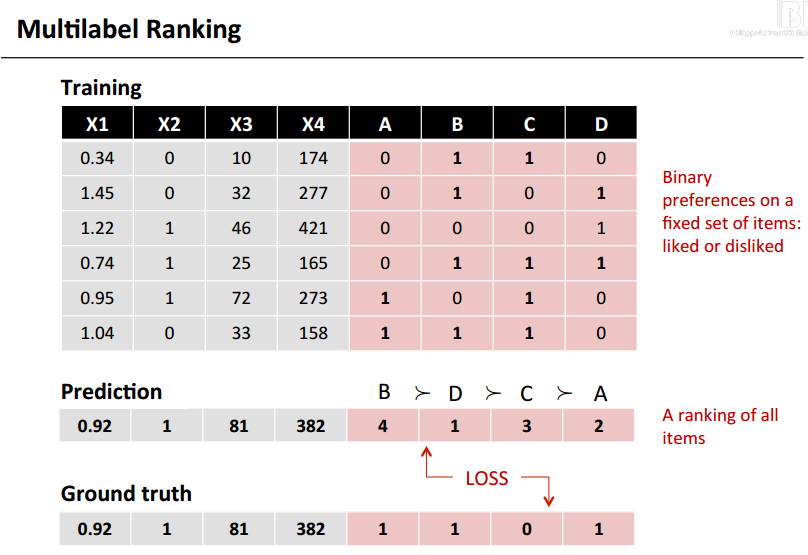
- 在多标签排名问题中用户的描述是二值型数据
- 它的预测结果数值型的按顺序表达的偏好,1表示最喜欢。
- 在标签排名问题中用户的描述是一个排名
- 它的预测结果数值型的按顺序表达的偏好,1表示最喜欢。
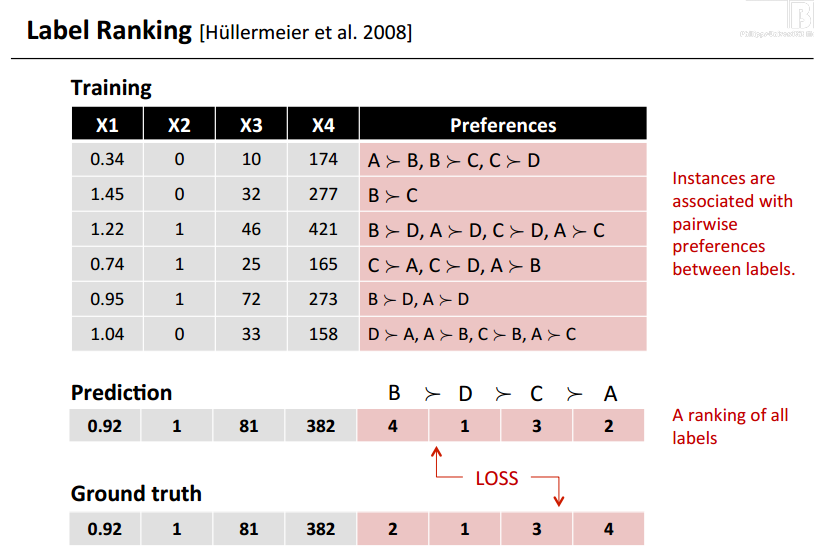
- 下面这个是标准的标签排名问题。
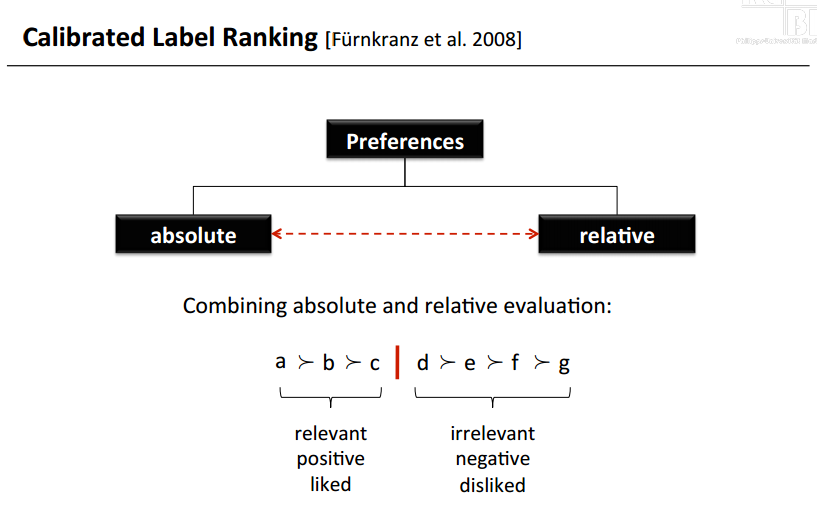
- 结合了相对的和绝对的排名。
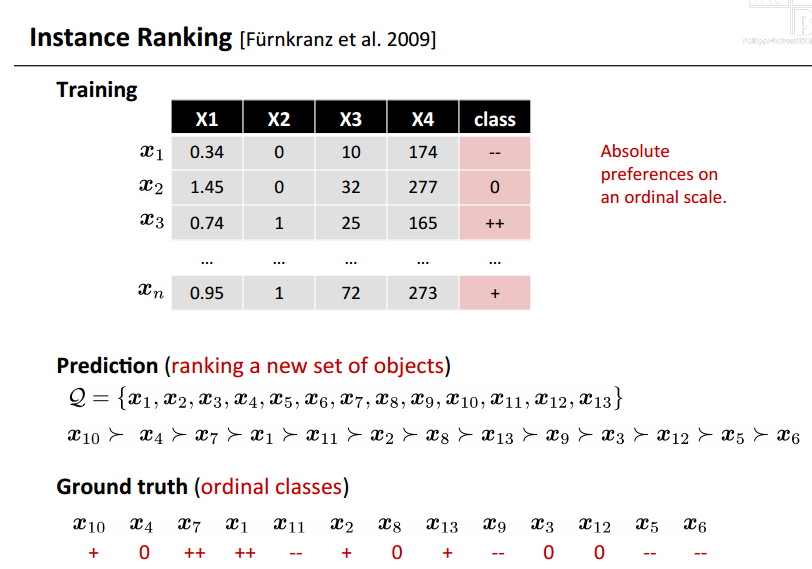
- 实例(用户)排名,根据用户的特征对用户进行排名。
- 这是一个协同过滤问题,每一行代表一个用户(user),每
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









