






目录
Curriculum Pseudo Labeling(课程伪标签)
Non-linear mapping function(非线性映射)
Conclusion and Future Work(结论和未来工作)
Assessing the prognostic accuracy of SCNN(SCNN预测准确性的评估)
Improving prognostic accuracy by integrating genomic biomarkers(整合基因组生物标志物提高预后准确性)
论文阅读1
FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling(FlexMatch:用课程伪标签促进半监督学习)
Abstract(摘要)
最近提出的FixMatch在大多数半监督学习(SSL)基准上获得了最先进的结果。然而,与其他现代SSL算法一样,FixMatch算法对所有类使用预定义的恒定阈值来选择对训练有贡献的未标记数据,从而没有考虑不同类的不同学习状态和学习难度。为了解决这个问题,我们提出了课程伪标注(CPL),这是一种根据模型的学习状态来利用未标注数据的课程学习方法。CPL的核心是在每个时间步灵活地调整不同类别的阈值,让信息丰富的未标记数据及其伪标签通过。
CPL不引入额外的参数或计算(正向或反向传播)。我们将CPL应用于FixMatch,并将我们的改进算法称为FlexMatch。FlexMatch在各种SSL基准测试上实现了最先进的性能,在标签数据极其有限或任务具有挑战性时,性能尤为强劲。CPL还显著提高了收敛速度。此外,我们还表明CPL可以很容易地适用于其他SSL算法,并显著提高它们的性能。
Introduction(介绍)
半监督学习(SSL)由于其在利用大量未标记数据方面的优势,近年来受到越来越多的关注。当标记的数据数量有限或难以获得时,这是特别有利的。一致性正则化和伪标注是利用未标注数据的两种强有力的技术,在现代SSL算法中得到了广泛的应用。
然而,FixMatch和其他流行的SSL算法(如伪标记和非监督数据增强(UDA)的一个缺点是它们依赖固定的阈值来计算非监督损失,仅使用预测置信度高于阈值的未标记数据。虽然该策略可以确保只有高质量的未标记数据对模型训练有贡献,但它忽略了大量的其他未标记数据,特别是在训练过程的早期阶段,只有少数未标记数据的预测置信度高于阈值。此外,现代SSL算法平等地处理所有类,而不考虑它们不同的学习困难。
为了解决这些问题,我们提出了课程伪标记(CPL),这是一种课程学习策略,以考虑每个class(类别)的学习状态进行半监督学习。我们将此课程学习策略直接应用于FixMatch,并将改进后的算法称为FlexMatch。
综上所述,本文主要做了以下三个方面的贡献:
- 提出了课程伪标注(CPL),这是一种动态利用未标注数据进行SSL学习的课程学习方法。它几乎是无代价的(cost-free),并且可以很容易地集成到其他SSL方法中。
- CPL在通用基准上显著提升了几种流行的SSL算法的精确度和收敛性能。具体地说,FlexMatch是FixMatch和CPL的集成,它实现了最先进的结果。
- 我们开源了TorchSSL,这是一个统一的基于PyTorch的半监督学习代码库,用于公平研究SSL算法。TorchSSL包括流行的SSL算法及其相应的训练策略的实现,并且易于使用或定制。
Background(背景)
SSL中最基本的一致性损失:

其中B是已标记数据的批次大小,µ是未标记数据与已标记数据的比率,ω是随机数据扩充函数(因此式(1)中的两项是不同的),ub表示一段未标记数据,Pm表示模型的输出概率。
随着伪标记技术的引入,一致性正则化被转化为更适合于分类任务的熵最小化过程。使用伪标签改善的一致性损失可以表示为:

其中,H为交叉熵,τ为预定义阈值,Pˆm(y|ω(ub))为伪标签,该伪标签既可以是‘hard’的独热标签,也可以是锐化的‘soft’标签。使用阈值的目的是过滤掉具有低预测置信度的噪声未标记数据。
FixMatch利用这种一致性正则化和强大的增强性来获得有竞争力的性能。对于未标记的数据,FixMatch首先使用弱增强来生成人工标签。然后,这些标签被用作强扩充数据的目标。因此,FixMatch中的非监督损失项具有如下形式:

其中Ω是强增强函数,而不是弱增强ω。
在上述工作中,预定义阈值(τ)是恒定的。我们相信这是可以改进的,因为某些class(类别)的数据可能天生就比其他class(类别)的数据更难学习。课程学习是一种学习策略,根据模型的学习过程逐步引入学习样本。
FlexMatch
Curriculum Pseudo Labeling(课程伪标签)

当前的SSL算法只呈现被预先定义的阈值截断的高置信度未标记数据的伪标签,而CPL在不同的时间步长将伪标签呈现给不同的类别。这一过程是通过根据每个class(类别)的模型学习状态来调整阈值来实现的。
然而,根据学习状态动态确定阈值并不是一件容易的事。最理想的方法是计算每个类别的评估精度,并使用它们来衡量阈值。

![]() 是类c在时间步长t的灵活阈值,at(c)是相应的评价精度。较低的精确度表明该类别的学习状态不太令人满意,这将导致较低的阈值,从而鼓励学习该类别的更多样本。由于我们不能在模型学习过程中使用评估集,因此可能需要从训练集中分离出额外的验证集来进行这样的准确性评估。然而,这种做法暴露出两个致命的问题:首先,在SSL场景下,由于标记的数据已经很少,这样的标记验证集从训练集分离出来的代价很高。其次,为了动态调整训练过程中的阈值,必须在每一步都连续进行精度评估,这将大大减慢训练速度。
是类c在时间步长t的灵活阈值,at(c)是相应的评价精度。较低的精确度表明该类别的学习状态不太令人满意,这将导致较低的阈值,从而鼓励学习该类别的更多样本。由于我们不能在模型学习过程中使用评估集,因此可能需要从训练集中分离出额外的验证集来进行这样的准确性评估。然而,这种做法暴露出两个致命的问题:首先,在SSL场景下,由于标记的数据已经很少,这样的标记验证集从训练集分离出来的代价很高。其次,为了动态调整训练过程中的阈值,必须在每一步都连续进行精度评估,这将大大减慢训练速度。
我们的CPL使用另一种方法来估计学习状态,该方法不引入额外的推理过程,也不需要额外的验证集。我们的关键假设是,当阈值较高时,一个类别的学习效果可以通过其预测落入该类别并高于阈值的样本数量来反映。

其中σt(c)反映类c在时间步长t的学习效果,pm,t(y|un)是模型在时间步长t对未标记数据的预测,N是未标记数据的总数。当未标记数据集是平衡的(即,属于不同类别的未标记数据的数量相等或接近)时,较大的σt(c)表示更好的估计学习效果。通过将以下归一化应用于σt(c)以使其范围在0到1之间,然后可以使用它来缩放固定阈值τ:

这种归一化方法的一个特征是,最好学习的类的βt(c)等于1,使得它的灵活阈值等于τ。这是可取的。对于难学的class(类别),降低了门槛,鼓励学习这些课程中更多的训练样本。这也提高了数据利用率。随着学习的进行,学得好的class(类别)的门槛会提高,以便有选择地挑选质量更高的样本。最终,当所有类别都达到可靠的精度时,阈值都将接近τ。
这个新的阈值用于计算FlexMatch中的非监督损失,它可以表示为:

其中qb=pm(y|ω(ub))。灵活的阈值在每次迭代时更新。最后,我们可以将FlexMatch中的损失表示为监督损失和非监督损失的加权组合(由λ计算):
![]()
其中Ls是标签数据的监督损失:

请注意,引入CPL的成本几乎是免费的,FlexMatch不会引入额外的前向传播过程来评估模型的学习状态,也不会引入新的参数。
Threshold warm-up(阈值预热)
我们在实验中注意到,在训练的早期阶段,模型可能会根据参数的初始化将大多数未标记样本盲目预测到某一类中,因此,在这个阶段,估计的学习状态可能并不可靠。因此,我们通过重写方程中的分母来引入预热过程。
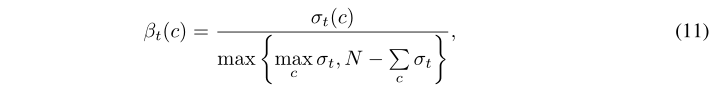
Non-linear mapping function(非线性映射)
相比于公式(7)那样的直接scale固定阈值,非线性映射使得阈值的调整可以更加自由,你可以设计任意形状的函数来实现从“归一化预估学习效果βt(c)到“最终动态阈值M(βt(c))。本文提到,凸函数可能更加有效,因为凸函数在自变量较小时因变量的变化不是很大,而在自变量大时比较敏感。这比较符合预估学习效果的变化特性,即:前期当其值较小时可能存在较大波动而后期其值变大后波动较小,且中后期多处于较高的范围内变化,因此需要对这部分更敏感。
Experiments(实验)
我们在CIFAR10/100、SVHN、STL-10和ImageNet等常用数据集上进行了实验,对比了包括FixMatch、UDA、ReMixmatch等最新最强的SSL算法。实验结果如下表所示。
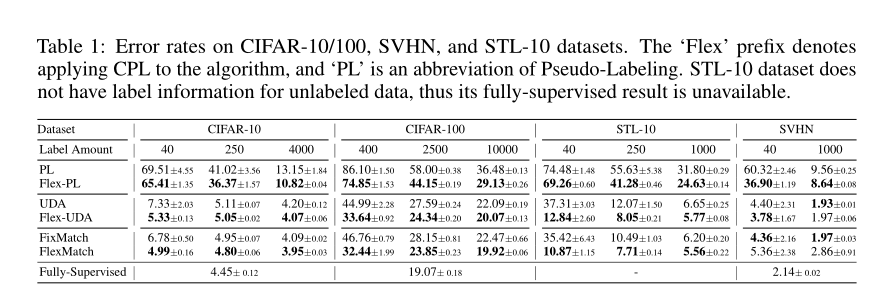
可以看到CPL在多数数据集上取得了很大的提升,除了SVHN上效果不如原版FixMatch,文中的解释是说,CPL不适合数据分布不平衡且又很简单的任务,对于简单的任务而言,一个固定的高阈值似乎已经足够了。在其他数据集上,可以发现,标记数据越少,CPL带来的提升越大。任务越难,CPL的提升越大。
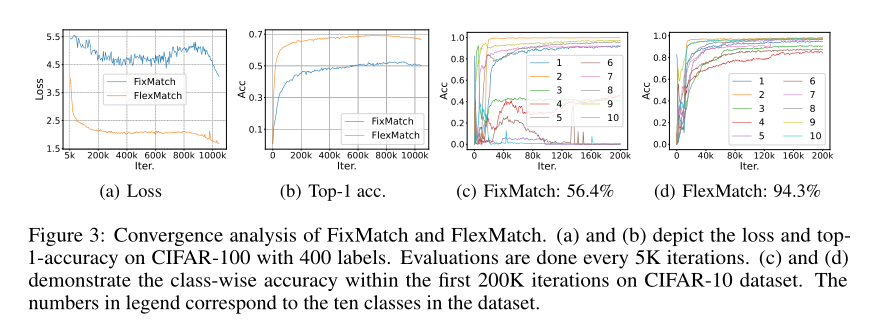
图3:FixMatch和FlexMatch的收敛分析。(A)和(B)描述了具有400个标签的CIFAR-100的损失和TOP1准确度。评估每5K次迭代进行一次。(C)和(D)在CIFAR-10数据集上展示了最初200K迭代内的类精度。图例中的数字对应于数据集中的十个类。
Conclusion and Future Work(结论和未来工作)
在本文中,我们介绍了课程伪标注(CPL),这是一种利用未标记数据进行SSL的课程学习方法。CPL极大地提高了涉及阈值的SSL算法的性能和收敛速度,同时极其简单且几乎免费( cost-free)。在未来的工作中,我们希望在长尾分布的情况下改进我们的方法,在这种情况下,属于每个类别的未标记数据非常不平衡。
论文阅读2
Predicting cancer outcomes from histology and genomics using convolutional networks (利用卷积网络从组织学和基因组学预测癌症预后)
Abstract(摘要)
癌症组织学反映了潜在的分子过程和疾病进展,并包含了丰富的表型信息,可以预测患者的预后。在这项研究中,我们展示了一种使用深度学习从数字病理图像中学习患者结果的计算方法,将自适应机器学习算法的能力与传统生存模型相结合。我们说明了这种方法如何整合来自组织学图像和基因组生物标记物的信息,以预测患者的事件发生时间结果,并展示了在预测被诊断为胶质瘤的患者的存活率方面超越当前临床范例的表现。
我们还提供了可视化通过这些深度学习生存模型学习的组织模式的技术,并建立了解决肿瘤内异质性和训练数据缺陷(训练数据少)的框架。
Introduction(介绍)
虽然预测越来越依赖于基因组生物标记物来测量基因改变、基因表达和表观遗传修饰,但组织学仍然是预测患者未来疾病进程的重要工具,组织学中存在的表型信息反映了分子改变对癌细胞行为的综合影响,并提供了一种方便的疾病侵袭性(disease aggressiveness)的视觉读数。
然而,人类对组织学的评估具有高度的主观性和不可重复性,因此组织学成像的计算分析受到了极大的关注。借助于载玻片扫描显微镜和计算机技术的进步,许多图像分析算法已经被开发出来,用于多种癌症类型的分级、分类和预测未来转移。深度卷积神经网络(CNN)已经成为一种重要的图像分析工具,并在许多具有挑战性的应用中打破了性能基准。
癌症临床治疗中的许多重要问题涉及到事件发生时间的预测,包括对总生存期、进展时间和转移时间的准确预测。尽管深度学习在其他应用中取得了压倒性的成功,但深度学习在这些问题上的应用并不广泛。
在本文中,我们提出了一种基于卷积网络的方法,称为生存卷积神经网络(SCNN),它可以从组织学图像中预测总生存期和其他事件发生时间的结果,其准确度与基于基因组生物标记物和人工组织学分级的临床范例相当或超过。
Result(结果)
Learning patient outcomes with deep survival convolutional neural networks(深度生存卷积神经网络学习患者预后)
SCNN模型体系结构如图1:
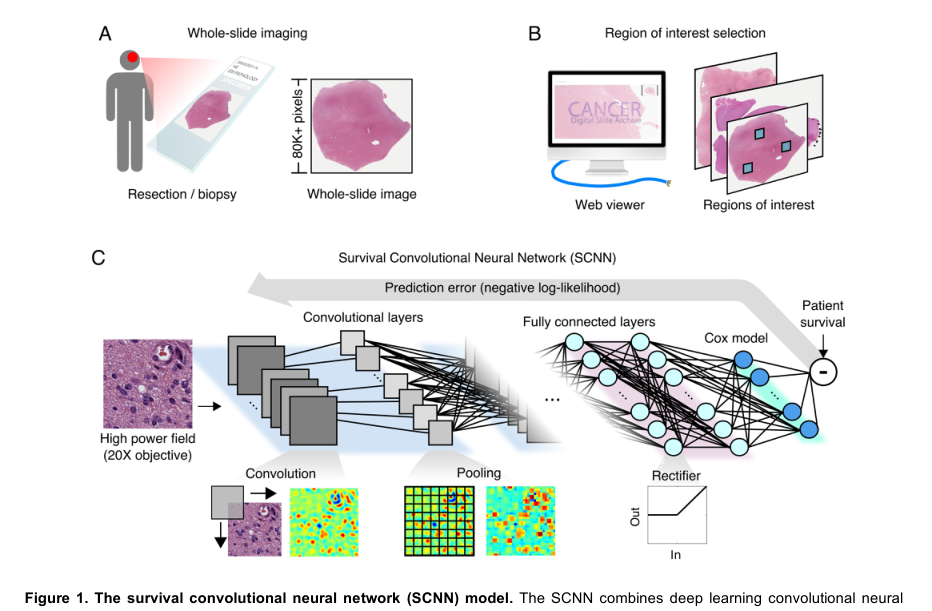
H&E组织切片首先被数字化为大的WSI图像。使用基于网络的平台对这些图像进行审查,以识别具有代表性组织学特征的感兴趣区域(ROI),来自这些ROI的HPFs然后被用来训练一个深度卷积网络,该网络与Cox比例风险模型无缝集成以预测患者结果。最终的Cox模型层输出对患者风险的预测。互连权重和卷积核是通过使用反向传播技术将网络预测的风险与存活或其他事件间隔时间结果进行比较来训练的,以优化网络的统计似然。
为了提高SCNN模型的性能,我们开发了重采样技术来解决训练样本的有限可用性(训练样本少)和肿瘤内的异质性(见图2)。对于训练,在每次训练迭代开始时,从每个ROI中随机抽取新的HPF,为SCNN模型提供对每个患者的组织学的全新观察,并捕捉ROI内的异质性。
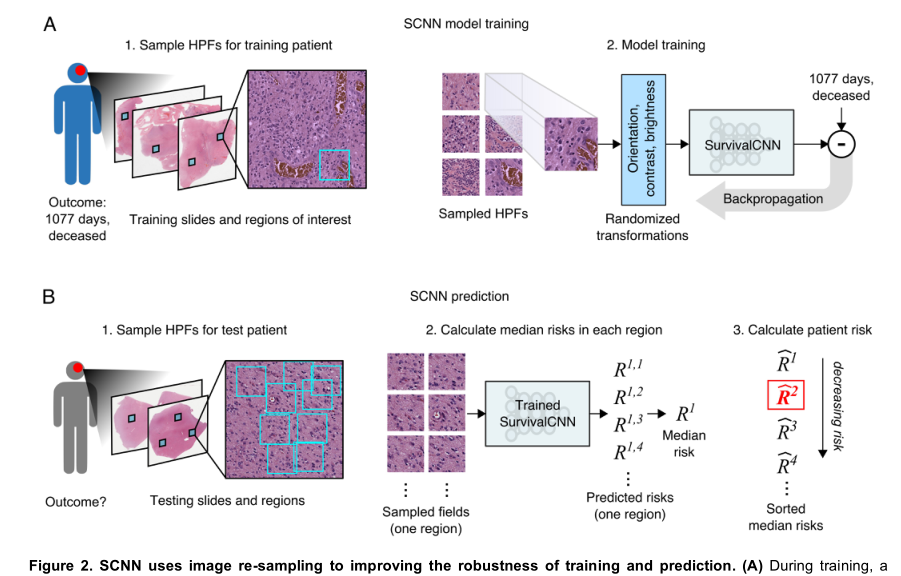
Assessing the prognostic accuracy of SCNN(SCNN预测准确性的评估)
准确率是使用c-index来衡量的,这是一种非参数统计,衡量了预测风险和实际存活率之间的一致性。c-index为1表示预测风险和总体存活率之间完全一致,而c-index为0.5则表示随机一致性。
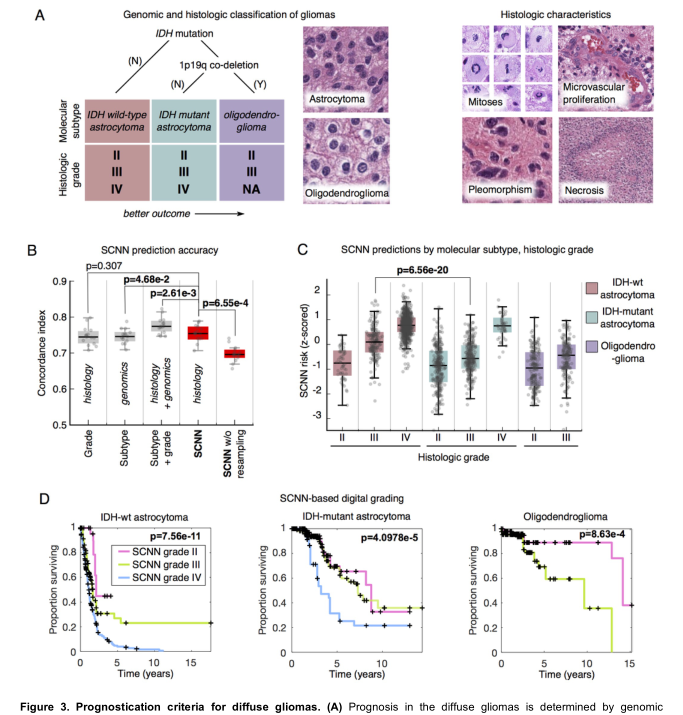
Improving prognostic accuracy by integrating genomic biomarkers(整合基因组生物标志物提高预后准确性)
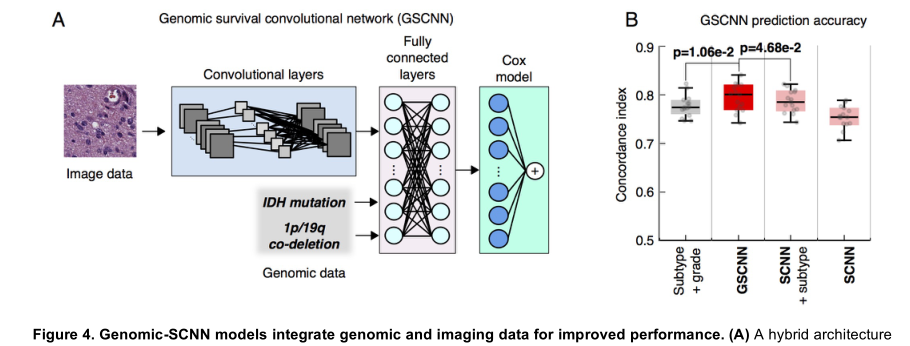
GSCNN通过将基因组变量合并到SCNN的完全连接层来提高预后准确性,从而从基因组学和组织学两方面学习预后(参见图4)。这种配置使基因组变量能够通过提供有关末端网络层附近分子亚型的信息来影响从组织学中学习到的模式。
Methods (方法)
生存卷积神经网络将19层VGG卷积网络结构的元素与Cox比例风险模型相结合,以预测图像中的事件间隔时间数据。终端全连接层输出风险预测R=![]() 与输入图像相关联,为了提供用于反向传播的误差信号,这些风险被输入到Cox比例风险层以计算负的部分对数似然:
与输入图像相关联,为了提供用于反向传播的误差信号,这些风险被输入到Cox比例风险层以计算负的部分对数似然:
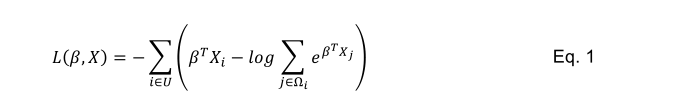
损失函数或者似然函数,要表达的意思就是我可以通过标签,也就是生存时间(survival time)和event(终点),让生存时间短的样本的risk score分数,高于生存时间长的样本的risk score。
Conclusion(结论)
我们展示了一种使用深度学习从数字病理图像中学习患者结果的计算方法,将自适应机器学习算法的能力与传统生存模型相结合。我们说明了这种方法如何整合来自组织学图像和基因组生物标记物的信息,以预测患者的事件发生时间结果,并展示了在预测被诊断为胶质瘤的患者的存活率方面超越当前临床范例的表现。我们还提供了可视化通过这些深度学习生存模型学习的组织模式的技术,并建立了解决肿瘤内异质性和训练数据缺陷的框架。















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









