






Semi-supervised Semantic Segmentation with Error Localization Network(基于误差定位网络的半监督语义分割 )
Abstract
本文研究了语义分割的半监督学习,该学习假设只有一小部分训练图像被标记,而其他图像保持未标记。未标记的图像通常被分配用于训练的伪标签,但由于对伪标签错误的确认偏差,这通常会导致性能下降的风险。 我们提出了一种新的方法来解决这个长期存在的伪标记问题。我们方法的核心是误差定位网络(ELN),它是一个辅助模块,将图像及其分割预测作为输入,并识别伪标签可能错误的像素。ELN通过在训练过程中忽略标签噪声,使半监督学习对不准确的伪标签具有鲁棒性,并且可以自然地与自训练和对比学习相结合。 此外,我们还引入了一种新的ELN学习策略,该策略模拟了ELN训练过程中可能出现的各种分割错误,以增强其泛化能力。我们的方法在PASCAL VOC 2012和Cityscapes上进行了评估,在每个评估环境中,它都优于所有现有方法。
Introduction
本文研究了语义分割的半监督学习方法,该方法假设训练图像中只有一个子集被赋予分割标签,而其他子集则保持未标记状态。毫无疑问,这项任务成功的关键是有效地利用未标记的图像。自我训练和对比学习是文献中常用的技巧。 尽管这些技术极大地提高了半监督语义分割的性能,但它们有一个共同的缺点:由于对未标记图像的预测通常会被错误破坏(corrupted by errors),因此使用此类预测作为监督进行学习会导致对错误的确认偏差,从而返回损坏的模型。 大多数现有方法只是通过不使用不确定预测作为监督来缓解这个问题,但它们的性能在很大程度上取决于手动调整的阈值。
最近的一种方法是通过学习和利用一个辅助网络来纠正伪标签上的错误;该模型被称为误差校正网络(ECN),它利用主分割网络的预测结果与训练图像的标记子集上的地面真值标签之间的差异进行学习。理想情况下,ECN可以显著提高伪标签的质量,但在实践中,由于训练中的挑战,其优势往往受到限制。**由于分割网络很快被过度拟合到少量标记图像上,**其作为ECN输入的输出不能覆盖ECN在测试中面临的各种预测错误,这导致ECN的泛化能力有限。
我们提出了一种新的方法,也致力于处理伪标签上的错误,但更好地推广到那些任意未标记的图像。我们的方法的核心是错误定位网络(ELN),它以二进制分割的形式识别带有错误伪标签的像素。正如经验所证明的,简单地忽略无效的伪标签,而不是纠正它们,就足以减轻确认偏差,并学习准确的分割模型。 更重要的是,由于错误定位是一个与类无关的错误校正子问题,因此更容易解决,因此为目标任务训练一个准确且可推广的网络就更简单了。此外,我们还设计了一种新的训练策略来使得ELN泛化。**具体来说,我们将多个辅助解码器连接到主分割网络,并对它们进行训练,以达到不同的精度水平,从而在不同的训练阶段模拟分割网络。**然后对ELN进行训练,以根据辅助解码器以及主分段网络给出的预测来定位错误。该策略提高了ELN的泛化能力,因为作为ELN输入的此类预测可能会显示分割网络在使用未标记图像进行自我训练时导致的错误模式。
训练后的ELN用于语义切分的半监督学习;包含ELN的整个管道如图1所示。
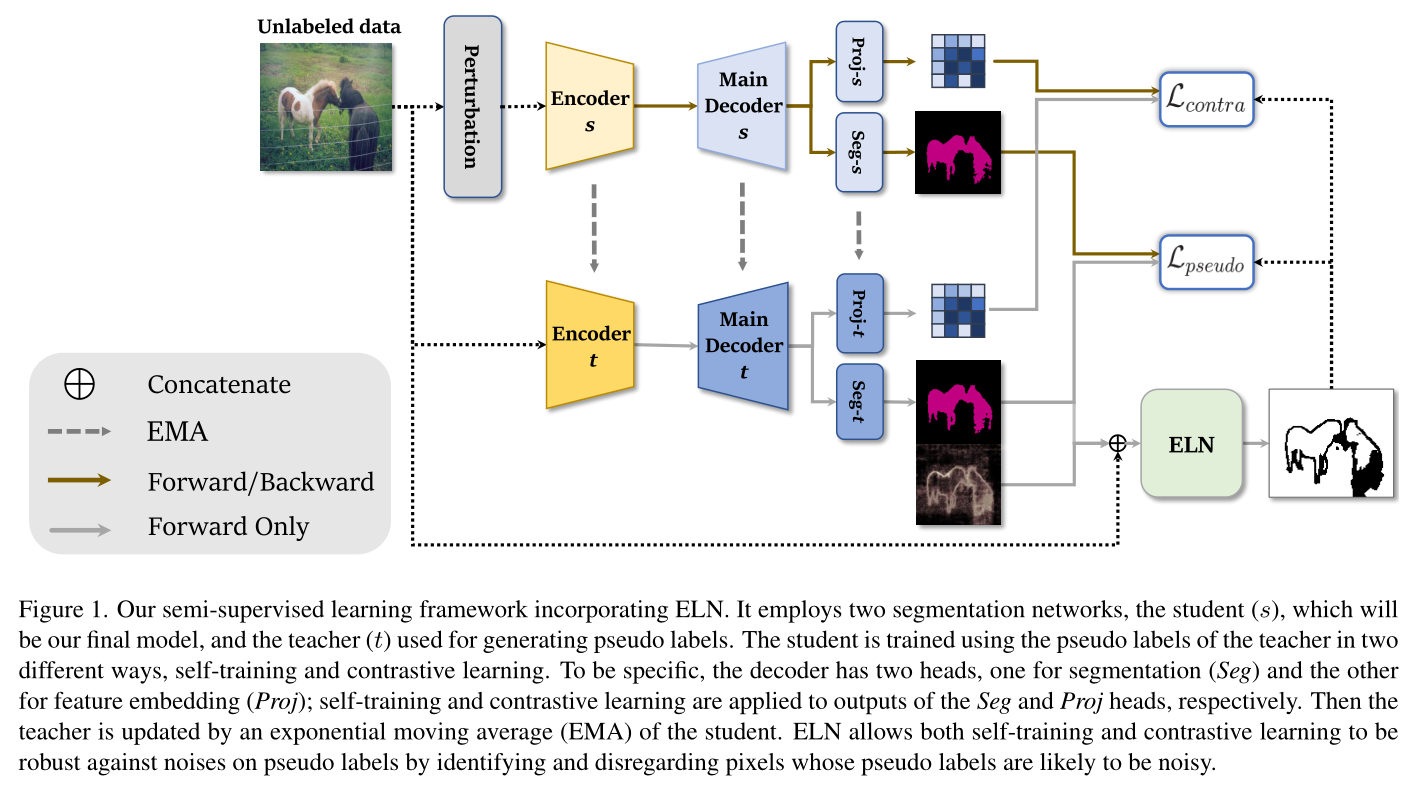
我们的框架以两种方式利用未标记的图像:自我训练和对比学习,两者都依赖于伪标签。为此,我们采用了两个分割网络。一个是学生网络,这将是我们的最终模型,另一个是产生伪标签的教师网络,并由学生的指数移动平均数更新。自我训练是通过使用教师产生的伪标签学习学生来完成的。同时,对比性学习鼓励学生和教师的嵌入向量是相似的,如果他们的伪标签是相同的。ELN通过过滤掉潜在的错误的伪标签来帮助提高自我训练和对比学习的效果。
按照惯例,我们在PASCAL VOC 2012和Cityscapes数据集上对所提出的方法进行了评估,同时改变了标注的训练图像的数量,在这两个数据集上都表现出了优于以往工作的性能。简而言之,我们的主要贡献有三个方面:
- 我们提出错误定位,这是一种处理伪标签错误的新方法。它简单而有效,可以自然地与自我训练和对比学习相结合。此外,我们从经验上证明了错误定位比错误纠正的优越性。
- 我们开发了一种新的策略,用于在ELN的训练过程中有意生成不同的、合理的预测错误。这提高了ELN的泛化能力,即使使用少量的标记数据进行训练。
- 由我们的方法训练的分割网络在两个基准数据集–PASCAL VOC 2012和Cityscapes–的各种设置中都达到了最先进的水平。
Proposed Method
我们的框架包括两个阶段,使用标记数据学习ELN和使用ELN的半监督学习。第一阶段的主要问题是主网络的预测缺乏多样性,这导致ELN的泛化能力较差。 为了解决这个问题,除了主分段网络(编码器E,解码器D),我们还使用了辅助解码器(D1aux,…,DKaux),它们被故意学习为不如主分段网络;辅助解码器的预测将描述合理且多样的错误。ELN与分段网络和辅助解码器一起学习,以识别预测中的错误。ELN培训的整个过程如图2所示。
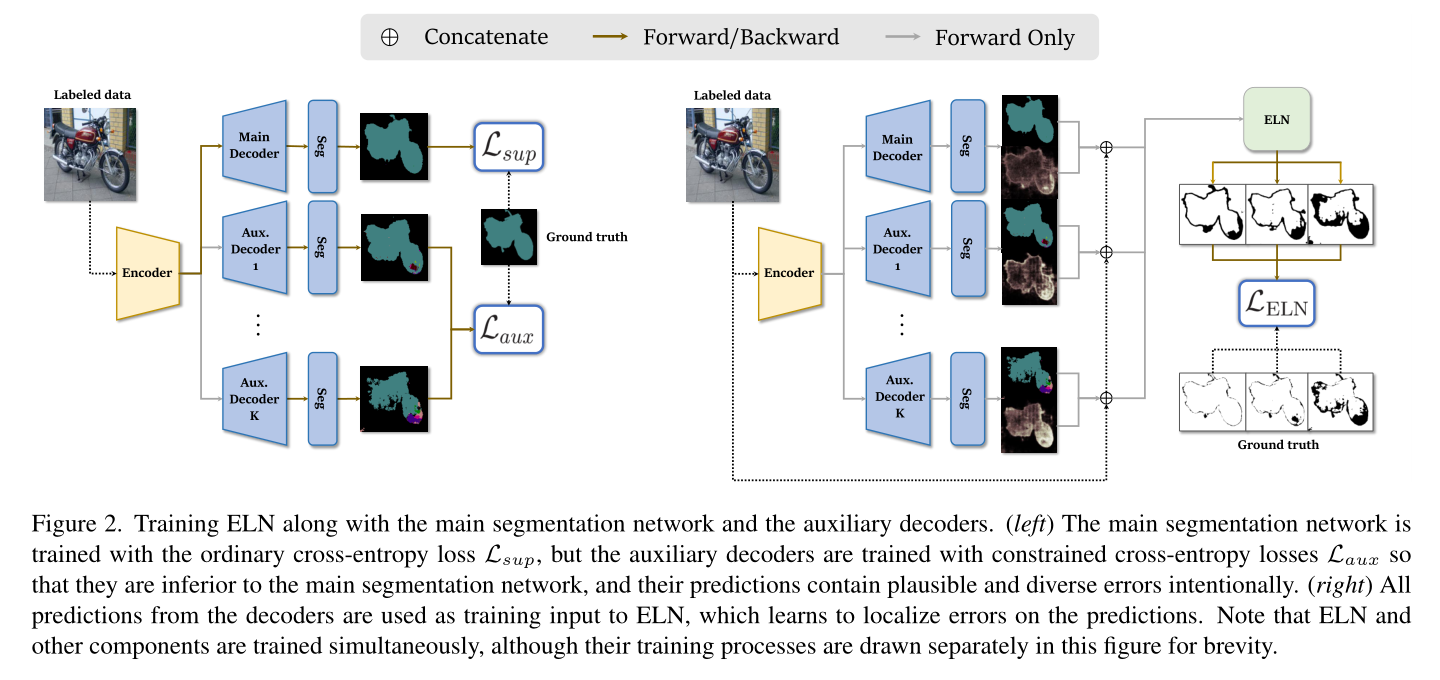
在第二阶段,将训练好的ELN用于语义分割的半监督学习,通过两种方式利用未标记图像,即自我训练和对比学习。ELN的作用是识别伪标签可能错误的像素,以便我们在自我训练和对比学习过程中忽略这些像素,以获得稳定有效的训练 。本节剩余部分将详细介绍我们方法的两个阶段。
Learning ELN Using Labeled Data
首先,在标记图像集DL上使用标准的像素级交叉熵损失Lsup对主分割网络进行预训练。 让Lce(P,Y)表示分割预测P与其地面真值标签Y之间的标准像素交叉熵:
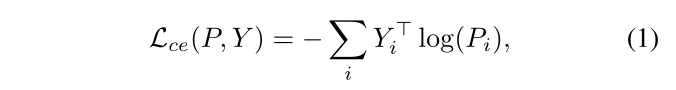
其中i是指示输入的每个像素的索引,Yi是像素i的地面真值的一个热向量。让P=D(E(X))表示图像X的主网络的分割预测。然后,Lsup由 :
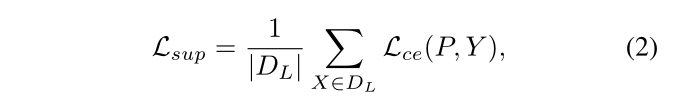
其中Y是输入图像X的基本真值 。
当预训练完成时,每个辅助解码器的训练与主网络类似,但具有受限的交叉熵损失,该损失仅最小化至Lce(P,Y)的特定倍数,并且其梯度不会传播到辅助解码器之外。 设K为所有辅助解码器的数量,K为它们的索引。然后,用Laux表示的K辅助解码器的总损耗由下式给出:
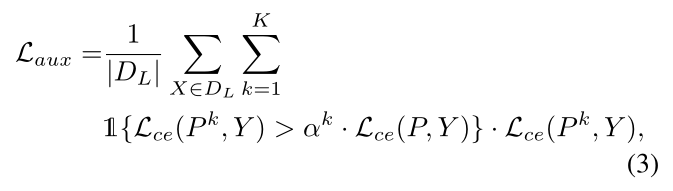
其中pk=Dk(E(X))表示第k个解码器的分段预测,αk表示用于约束应用于第k个辅助解码器的损耗的尺度超参数。 以这种方式训练辅助解码器使其能够产生看似错误的预测,这些预测被用作ELN的训练输入。 给定一幅图像及其分割预测作为输入,通过有监督学习训练ELN来定位预测中的错误,通过将预测与地面真实值进行比较来揭示错误的真实位置。 设Ek是pk的像素熵图和Bk=ELN(X⊕Pk⊕Ek)表示ELN的预测,是以二进制分割图的形式,其中⊕ 表示按通道的矩阵连接 。然后,ELN的二元交叉熵损失LELN由下式给出:
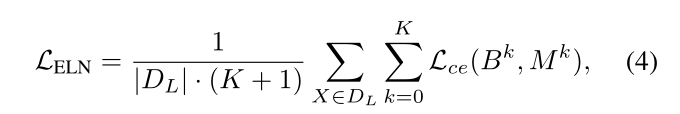
其中mk表示Bk的地面真相面具;如果像素i的预测正确,则M ki为1,否则为0。 请注意,k=0表示主解码器。 尽管使用了辅助解码器,但M k中像素级二进制标签的总体通常偏向于1(正确),这削弱了ELN的错误识别能力。为了缓解这种情况,对LELN中预测错误的像素应用重新加权因子,以进行平衡训练。让Lwce表示分段预测P与其二进制地面真值标签Y之间的权重重新调整的像素级交叉熵:
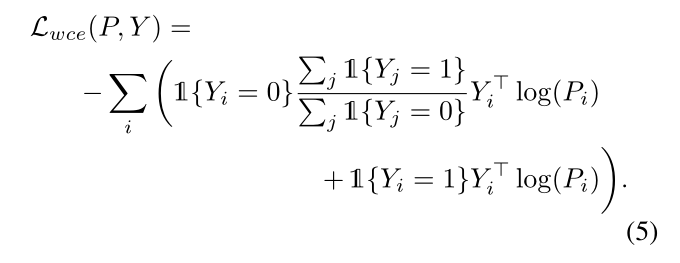
然后将等式(4)中的损失修正为:
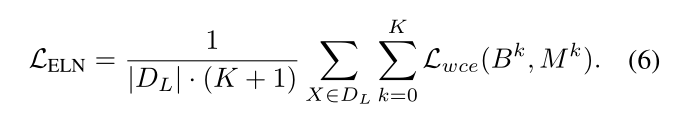
标签数据在第一阶段的总损失最小化如下:
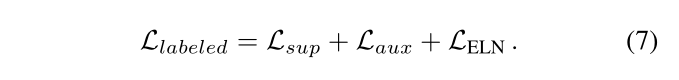
请注意,尽管在训练前Lsup完全最小化,但在第一阶段,Llabeled中的损失将联合优化。
Semi-supervised Learning with ELN
学习ELN后,主分割网络在未标记图像集DU上进行训练,该图像集有两个损失,一个是自训练损失,一个是像素级对比损失。 我们采用了mean-teacher框架,该框架允许教师网络向学生网络提供更稳定的伪监督。教师的权重θ(E,D)由学生权重θ(E,D)的指数移动平均值更新,更新率β:
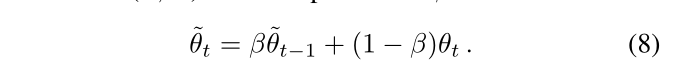
提出的自训练损失Lpseudo是像Lsup一样的像素交叉熵损失,但仅适用于ELN识别的有效像素。 让 ˜P = ˜D( ˜E(X)) 表示教师网络的分割预测,P a = D(E(A - X)) 表示学生网络的预测,其中A是应用于输入图像X的扰动算子。另外,让˜B = ELN(X ⊕ ˜P ⊕ ˜E)是ELN的二进制分割输出。那么Lpseudo由以下公式给出:

其中⌊⌉是一个四舍五入到最接近的整数的函数,ˆYi表示像素i的伪标签的单热向量。 通过四舍五入的二进制掩码,主分割网络可以只对有效像素进行训练。为了进一步提高所学特征的质量,我们采用了一个像素对比损失Lcontra。具体来说,在这个损失中,伪标签相同的特征会相互吸引,而不同类别的特征会在特征空间中被推开。我们不在单一图像上应用损失,而是将其范围扩大到整个输入批次,以考虑各种特征关系,从而导致性能的显著提高。对于一个给定的输入,让Ωip表示属于像素i的类别的像素集合,Ωin表示不属于像素i的类别的像素集合。另外,让d代表一个距离函数,d(f1, f2) = exp(cos(f1, f2)/τ),其中cos表示余弦相似度,τ是一个温度超参数。那么,像素级的对比损失Lcontra由以下公式给出:
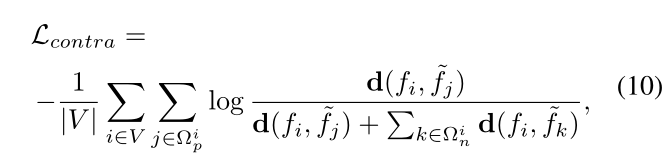
其中,V表示DU上有效像素的集合,fi和˜fi分别是学生和教师网络中像素i的特征嵌入。无标签数据的总损失如下:
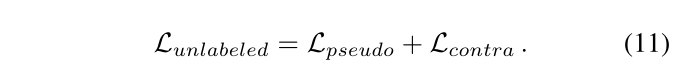
请注意,标注的数据也通过Llabeled参与训练。当训练完成后,只有学生网络被用于推理,因为其他的,包括ELN,都是支持学生半监督学习的辅助模块。
后面部分就不看了,只看了方法部分,因为效果肯定也是SOTA的。具体细节得看代码,慢慢学习。














 4243
4243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









