







xpath解析原理:
1.实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。
2.调用etree对象中的xpath方法结合xpath表达式实现标签的定位和内容的捕获。
如何实例化一个etree对象?
from lxml import etree
1.将本地的html文档中的源码数据加载到etree对象中
etree.parse(filepath)
2.可以将从互联网上获取的源码数据加载到该对象中
etree.HTML(‘page_text’)
xpath(‘xpath表达式’)
xpath被应用到不同的xpath表达式
模拟登录:
爬取用户的个人信息
需求:对人人网进行模拟登陆
- 点击登录按钮之后会发起一个post请求
- post请求中会携带登录之前录入的相关的登录信息(用户名,密码,验证码)
- 验证码:每次请求都会发生变化
编码流程:
1.验证码的识别,获取验证码图片的文字数据
2.对post请求进行发送(处理请求参数)
3.对响应数据进行持久化存储
下面进行相应的实战演习,模拟登录人人网的页面
先进入人人网的相应的内容,然后登录到相应的界面之中,发现有一个login内容,需要对login中的url进行一个相应的复制
 登录之后找到了相应的数据
登录之后找到了相应的数据
 这里面传入的数据唯一需要我们修改的就是对应的icode数值,因为icode数值就是相应的验证码
这里面传入的数据唯一需要我们修改的就是对应的icode数值,因为icode数值就是相应的验证码
import requests
from chaojiying import Chaojiying_Client
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'http://www.renren.com/SysHome.do'
#人人网对应的登录页面的url
page_text = requests.get(url=url,headers=headers).text
with open('page_text.html','w',encoding='utf-8') as file_obj:
file_obj.write(page_text)
tree = etree.HTML(page_text)
code_img_src = tree.xpath('//*[@id="verifyPic_login"]/@src')[0]
#获取验证码的url
code_img_data = requests.get(url=code_img_src,headers=headers).content
#获取验证码的图片
with open('./code.jpg','wb') as fp:
fp.write(code_img_data)
#写入相应的文件
#存储相应的code.jpg图片
chaojiying = Chaojiying_Client('xiaoguzai', 'z123456***', '911712') #用户中心>>软件ID 生成一个替换 96001
im = open('code.jpg', 'rb').read()
code_str = chaojiying.PostPic(im, 1005)
print('code_str = ')
print(code_str)
#想白嫖的可以自己手动输入验证码,设置一个输入框
login_url = 'http://www.renren.com/ajaxLogin/login'
param = {
'1':'1',
'uniqueTimestamp':'2021051122961'
}
data = {
'email': '',#对应的email的内容
'icode': code_str,
'origURL': 'http://www.renren.com/home',
'domain': 'renren.com',
'key_id': '1',
'captcha_type': 'web_login',
'password': '454b8682d3b24affd4025fdfbee30269bcd639035c4eee7f7d4a7d940511a3bf',
'rkey': 'fe41ddb7ec32db83d8bdbcc6945e267a',
'f': 'http%3A%2F%2Fwww.renren.com%2F975736813'
}
result_page = requests.post(url=login_url,params=param,data=data,headers=headers)
print(result_page.status_code)
result_page = result_page.text
with open('result_page.html','w',encoding='utf-8') as file_obj:
file_obj.write(result_page)
返回的状态码为200的时候,说明模拟登录成功,如果模拟登录失败,可能出现的情况:
1.可能是网址的url出现了错误
2.可能是data对应的参数出现了错误
模拟登录之后能够获得当前用户页面的数据,现在制定一个新的需求
需求:爬取当前用户的相关的用户信息(个人主页中显示的用户信息)
首先我们分析登录之后对应的人人网的界面
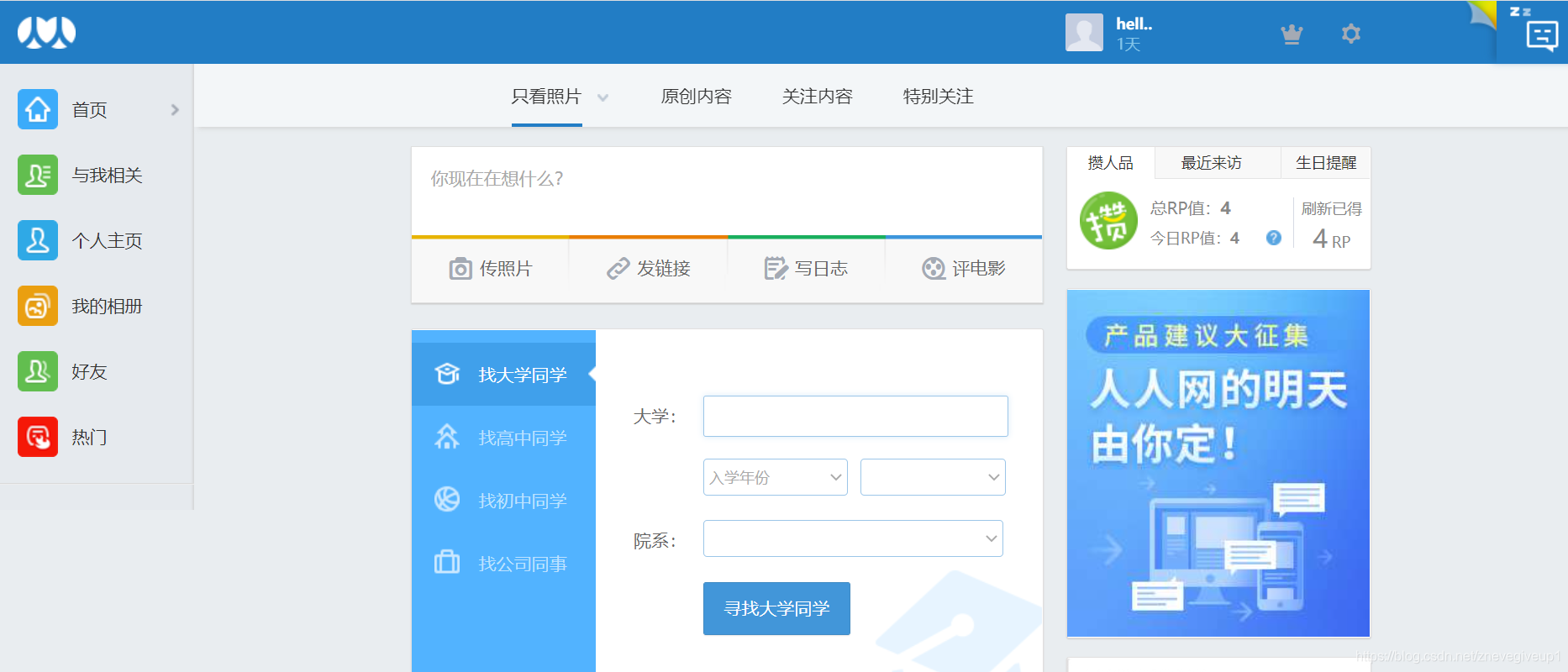 登录之后的人人网为上述的这个界面,如果我们想要进一步查看相应的个人资料,就需要对下面的网络链接发送请求
登录之后的人人网为上述的这个界面,如果我们想要进一步查看相应的个人资料,就需要对下面的网络链接发送请求
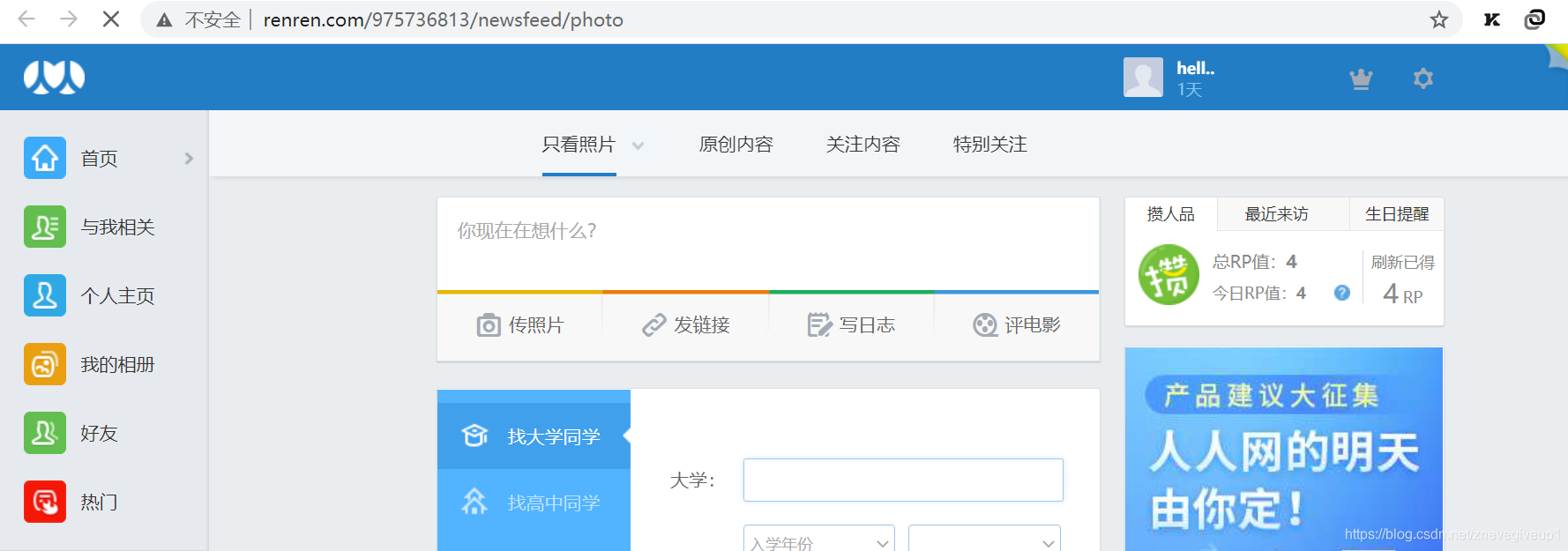 点击页面进去之后得到相应的页面的图像
点击页面进去之后得到相应的页面的图像
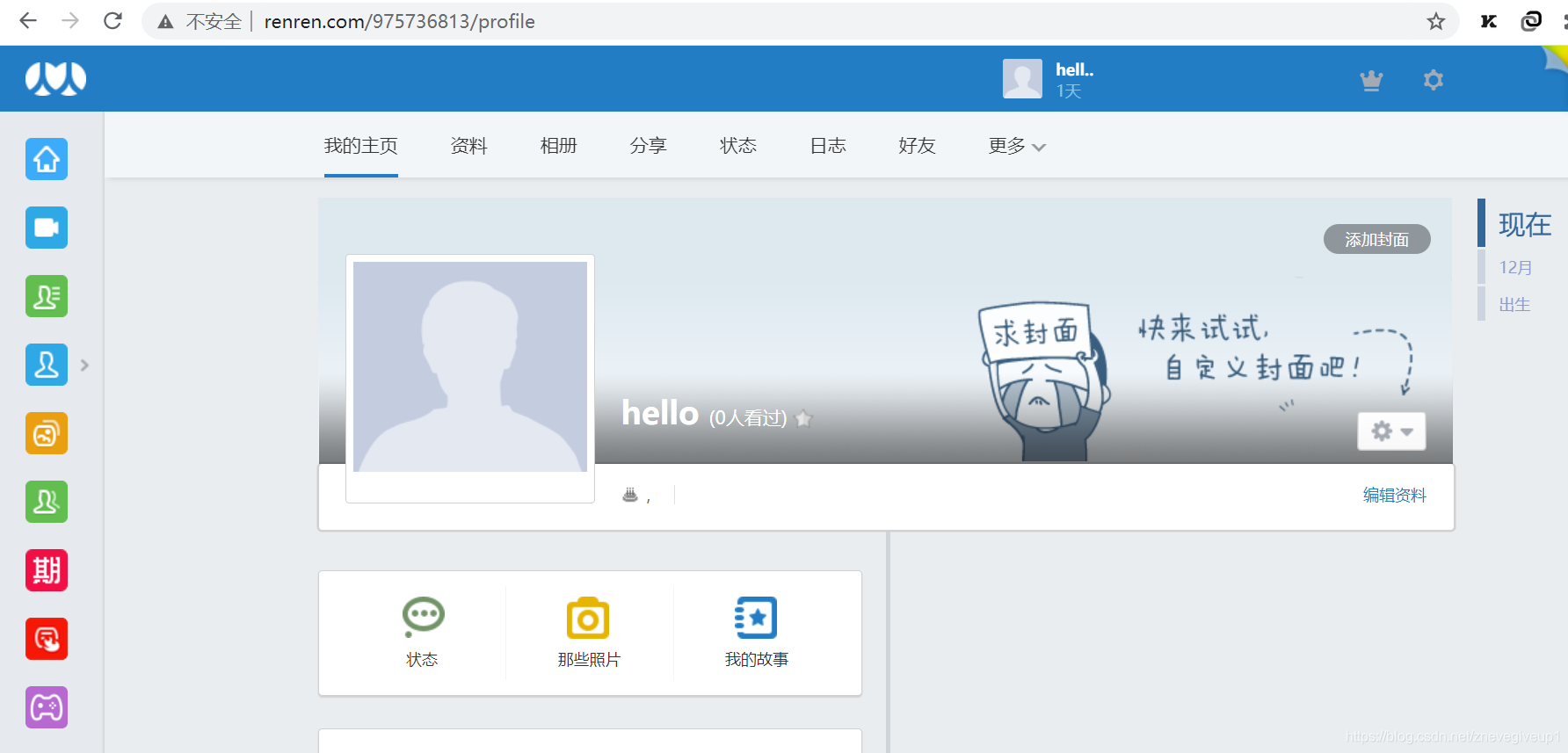 上面这张页面就是用户个人信息的页面,所以在模拟登录页面发请求得到相应的页面。
上面这张页面就是用户个人信息的页面,所以在模拟登录页面发请求得到相应的页面。
首先我们直接访问之前登录得到的页面的链接,然后将访问过的数据保存下来
import requests
from chaojiying import Chaojiying_Client
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'http://www.renren.com/SysHome.do'
#人人网对应的登录页面的url
page_text = requests.get(url=url,headers=headers).text
with open('page_text.html','w',encoding='utf-8') as file_obj:
file_obj.write(page_text)
tree = etree.HTML(page_text)
code_img_src = tree.xpath('//*[@id="verifyPic_login"]/@src')[0]
#获取验证码的url
code_img_data = requests.get(url=code_img_src,headers=headers).content
#获取验证码的图片
with open('./code.jpg','wb') as fp:
fp.write(code_img_data)
#写入相应的文件
#存储相应的code.jpg图片
chaojiying = Chaojiying_Client('xiaoguzai', 'z123456***', '911712') #用户中心>>软件ID 生成一个替换 96001
im = open('code.jpg', 'rb').read()
code_str = chaojiying.PostPic(im, 1005)
print('code_str = ')
print(code_str)
#想白嫖的可以自己手动输入验证码,设置一个输入框
login_url = 'http://www.renren.com/ajaxLogin/login'
param = {
'1':'1',
'uniqueTimestamp':'2021051122961'
}
data = {
'email': '18833273156',
'icode': code_str,
'origURL': 'http://www.renren.com/home',
'domain': 'renren.com',
'key_id': '1',
'captcha_type': 'web_login',
'password': '454b8682d3b24affd4025fdfbee30269bcd639035c4eee7f7d4a7d940511a3bf',
'rkey': 'fe41ddb7ec32db83d8bdbcc6945e267a',
'f': 'http%3A%2F%2Fwww.renren.com%2F975736813'
}
result_page = requests.post(url=login_url,params=param,data=data,headers=headers)
print(result_page.status_code)
result_page = result_page.text
#with open('result_page.html','w',encoding='utf-8') as file_obj:
# file_obj.write(result_page)
#直接对人人网的相应网页发送请求
detail_url = 'http://www.renren.com/975736813/profile'
detail_page_text = requests.get(url=detail_url,headers=headers).text
with open('bobo.html','w',encoding='utf-8') as fp:
fp.write(detail_page_text)
打开保存的网页之后,发现保存的内容并不是我们登录之后的页面,而是原始的登录页面,
http/https协议特性:无状态。向服务器发post请求,服务器并不会告诉客户端相应的状态。当我们第二次向个人主页发送服务端的get请求的时候,服务器端并不会知道当前状态下已经是一个登陆状态发起的请求。
cookie:用来让服务器端记录客户端的相关状态。
点开右上角的对应的用户,
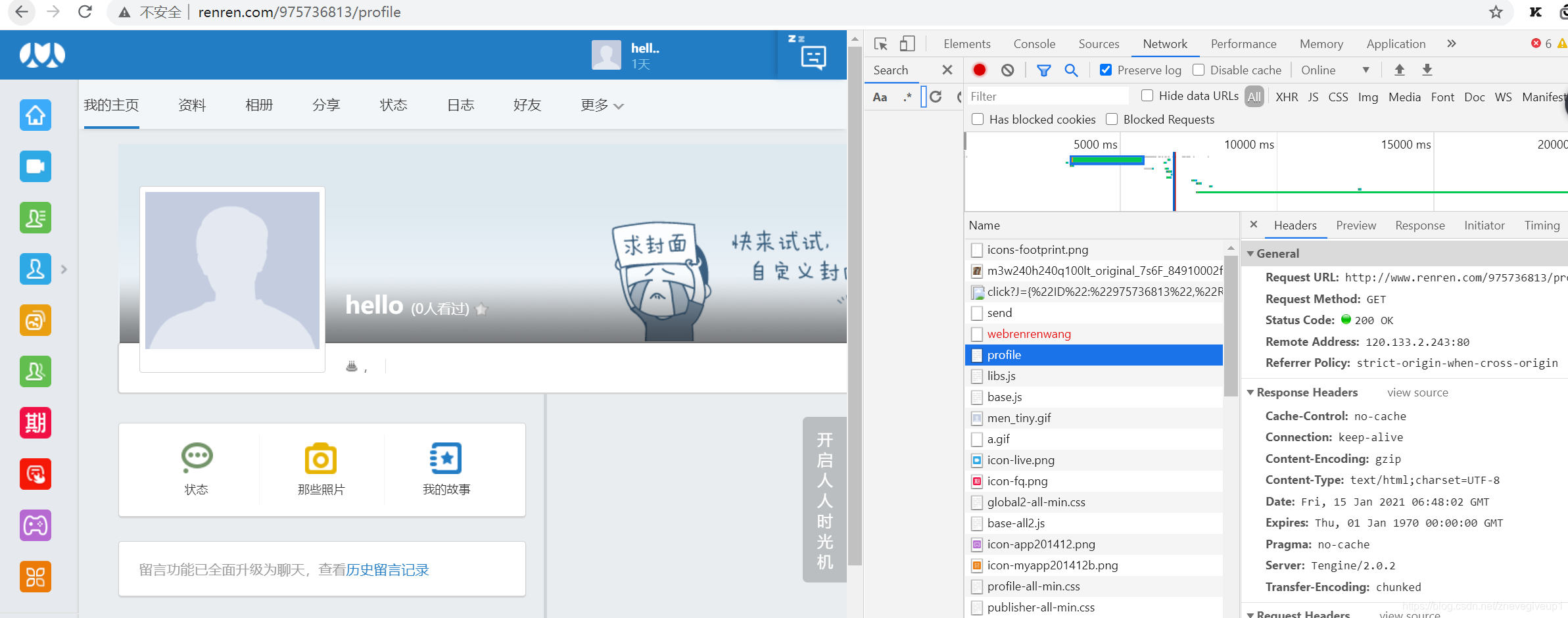 因为链接的内容为profile,所以实际上是对profile的内容进行抓包,右侧找出含有profile的对应的内容。
因为链接的内容为profile,所以实际上是对profile的内容进行抓包,右侧找出含有profile的对应的内容。
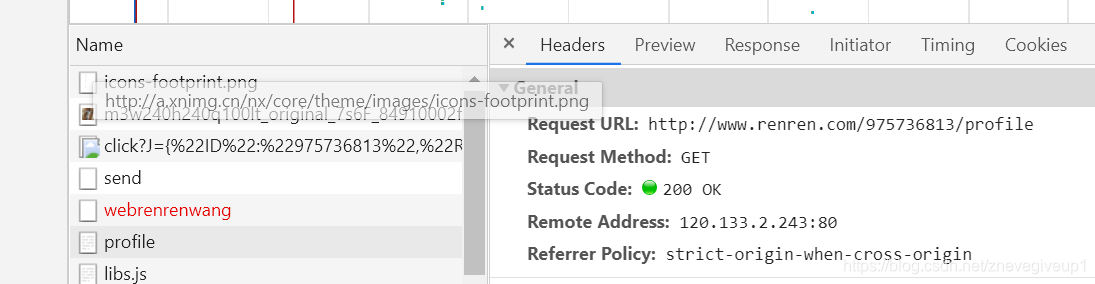 上面的Request URL跟我们请求的URL内容一样,但是我们仔细观察下面的部分,发现Request header之中多了个cookie的内容
上面的Request URL跟我们请求的URL内容一样,但是我们仔细观察下面的部分,发现Request header之中多了个cookie的内容
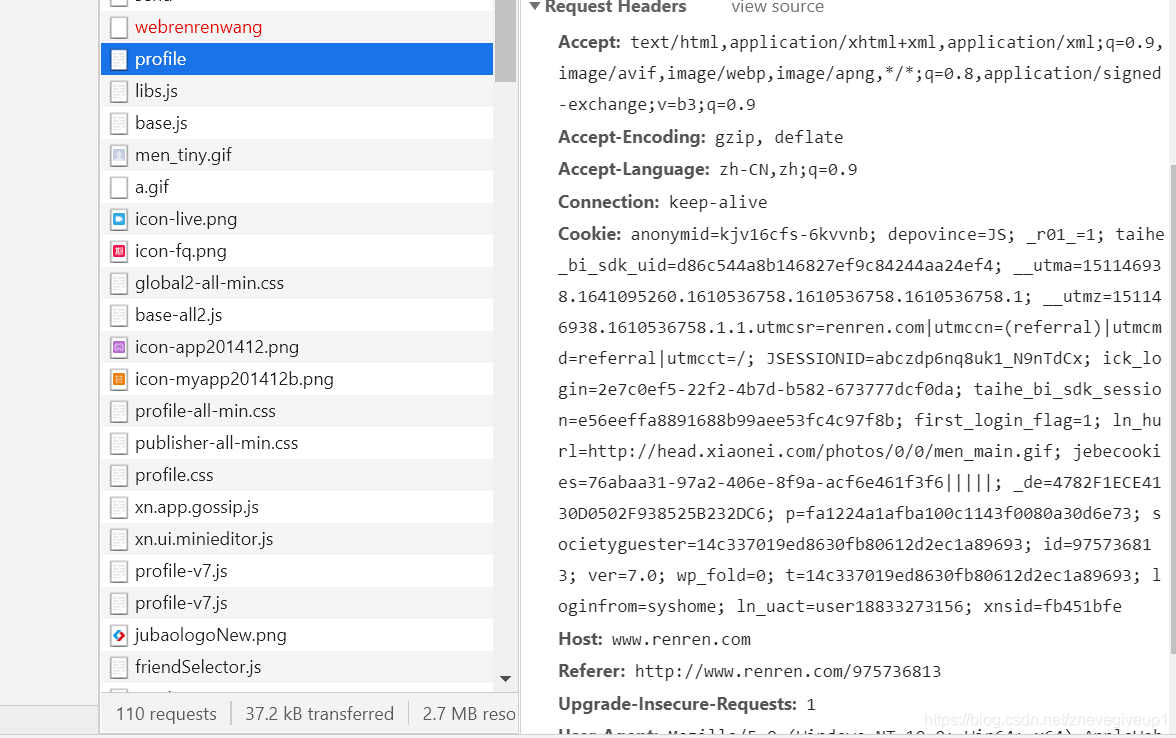 说明这个浏览器对客户端发请求的时候是携带了cookie值的,这个cookie用来服务器端记录客户端状态的内容。
说明这个浏览器对客户端发请求的时候是携带了cookie值的,这个cookie用来服务器端记录客户端状态的内容。
这个cookie可以手动放入headers对应的参数之中,但是这种方法不建议使用,因为有的cookie的值有动态时长,而且有的cookie值是动态变化的,所以这里不建议使用。
爬取的中间过程需要使用session来保存cookie,完整的爬取到界面相应数值的内容如下所示
import requests
from chaojiying import Chaojiying_Client
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'http://www.renren.com/SysHome.do'
#人人网对应的登录页面的url
session = requests.Session()
page_text = requests.get(url=url,headers=headers).text
with open('page_text.html','w',encoding='utf-8') as file_obj:
file_obj.write(page_text)
tree = etree.HTML(page_text)
code_img_src = tree.xpath('//*[@id="verifyPic_login"]/@src')[0]
#获取验证码的url
code_img_data = requests.get(url=code_img_src,headers=headers).content
#获取验证码的图片
with open('./code.jpg','wb') as fp:
fp.write(code_img_data)
#写入相应的文件
#存储相应的code.jpg图片
chaojiying = Chaojiying_Client('xiaoguzai', 'z123456***', '911712') #用户中心>>软件ID 生成一个替换 96001
im = open('code.jpg', 'rb').read()
code_str = chaojiying.PostPic(im, 1005)
print('code_str = ')
print(code_str)
#想白嫖的可以自己手动输入验证码,设置一个输入框
login_url = 'http://www.renren.com/ajaxLogin/login'
param = {
'1':'1',
'uniqueTimestamp':'2021051122961'
}
data = {
'email': '18833273156',
'icode': code_str,
'origURL': 'http://www.renren.com/home',
'domain': 'renren.com',
'key_id': '1',
'captcha_type': 'web_login',
'password': '454b8682d3b24affd4025fdfbee30269bcd639035c4eee7f7d4a7d940511a3bf',
'rkey': 'fe41ddb7ec32db83d8bdbcc6945e267a',
'f': 'http%3A%2F%2Fwww.renren.com%2F975736813'
}
#使用session进行post请求的发送
result_page = session.post(url=login_url,params=param,data=data,headers=headers)
print(result_page.status_code)
result_page = result_page.text
#with open('result_page.html','w',encoding='utf-8') as file_obj:
# file_obj.write(result_page)
#直接对人人网的相应网页发送请求
#方法1:手动cookie处理,将cookie封装到headers当中,可以成功,但是不建议使用
#主要有的网站的cookie值有动态时长,或者有的网站的cookie值是动态变化的
#headers = {
# 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
# 'Cookie': 'anonymid=kjv16cfs-6kvvnb; depovince=JS; _r01_=1; taihe_bi_sdk_uid=d86c544a8b146827ef9c84244aa24ef4; __utma=151146938.1641095260.1610536758.1610536758.1610536758.1; __utmz=151146938.1610536758.1.1.utmcsr=renren.com|utmccn=(referral)|utmcmd=referral|utmcct=/; JSESSIONID=abczdp6nq8uk1_N9nTdCx; ick_login=2e7c0ef5-22f2-4b7d-b582-673777dcf0da; taihe_bi_sdk_session=e56eeffa8891688b99aee53fc4c97f8b; first_login_flag=1; ln_hurl=http://head.xiaonei.com/photos/0/0/men_main.gif; jebecookies=76abaa31-97a2-406e-8f9a-acf6e461f3f6|||||; _de=4782F1ECE4130D0502F938525B232DC6; p=fa1224a1afba100c1143f0080a30d6e73; societyguester=14c337019ed8630fb80612d2ec1a89693; id=975736813; ver=7.0; wp_fold=0; t=14c337019ed8630fb80612d2ec1a89693; loginfrom=syshome; ln_uact=user18833273156; xnsid=fb451bfe'
#}
#方法2:自动cookie处理
#cookie值的来源是哪里?模拟登陆post请求后,由服务器端创建
#session会话对象:作用:1.可以进行请求的发送
#2.如果请求过程中产生了cookie,则该cookie会被自动存储/携带在该session对象中
#创建一个session对象:session = requests.Session()
#1.使用session对象进行模拟登陆post请求的发送(cookie就会被存储在session中)
#2.session对象对个人主页对应的get请求进行发送(携带了cookie)
#使用携带cookie的session进行get请求的发送
detail_url = 'http://www.renren.com/975736813/profile'
detail_page_text = session.get(url=detail_url,headers=headers).text
with open('bobo.html','w',encoding='utf-8') as fp:
fp.write(detail_page_text)
因为http/https协议特性是无状态的,所以需要使用cookie去创建相应的对象














 631
631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









