







Backbone network部分,直接调用残差网络的官方源码:
import torch
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
'resnet152']
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
"""
这里的前向传播,实现两个3X3卷积核+一个跳跃连接,为一个残差快,这个模块只在RESENT18中有
"""
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = conv1x1(inplanes, planes)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = conv3x3(planes, planes, stride)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = conv1x1(planes, planes * self.expansion)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
"""
这里的前向传播,实现三个3X3卷积核+一个跳跃连接,为一个残差快,这个模块只在RESENT50和100中有
"""
class ResNet(nn.Module):
def __init__(self, block, layers, zero_init_residual=False):
super(ResNet, self).__init__()
self.inplanes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
C_1 = self.conv1(x)
C_1 = self.bn1(C_1)
C_1 = self.relu(C_1)
C_1 = self.maxpool(C_1)
C_2 = self.layer1(C_1)
C_3 = self.layer2(C_2)
C_4 = self.layer3(C_3)
C_5 = self.layer4(C_4)
return C_3, C_4, C_5
def resnet18(pretrained=False, hr_pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
# strict = False as we don't need fc layer params.
if hr_pretrained:
print('Loading the high resolution pretrained model ...')
model.load_state_dict(torch.load("backbone/weights/resnet18_hr_10.pth"), strict=False)
else:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']), strict=False)
return model
def resnet34(pretrained=False, **kwargs):
"""Constructs a ResNet-34 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet34']), strict=False)
return model
def resnet50(pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet50']), strict=False)
return model
def resnet101(pretrained=False, **kwargs):
"""Constructs a ResNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 23, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet101']), strict=False)
return model
def resnet152(pretrained=False, **kwargs):
"""Constructs a ResNet-152 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 8, 36, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet152']))
return model
if __name__ == '__main__':
# model = torchvision.models.resnet50()
print("found ", torch.cuda.device_count(), " GPU(s)")
device = torch.device("cuda")
model = resnet101(detection=True).to(device)
print(model)
input = torch.randn(1, 3, 512, 512).to(device)
output = model(input)
Neck network,即颈部网络:选择SPP网络,其结构非常简单,仅仅是若干不同大小的maxpooling层堆叠而成:
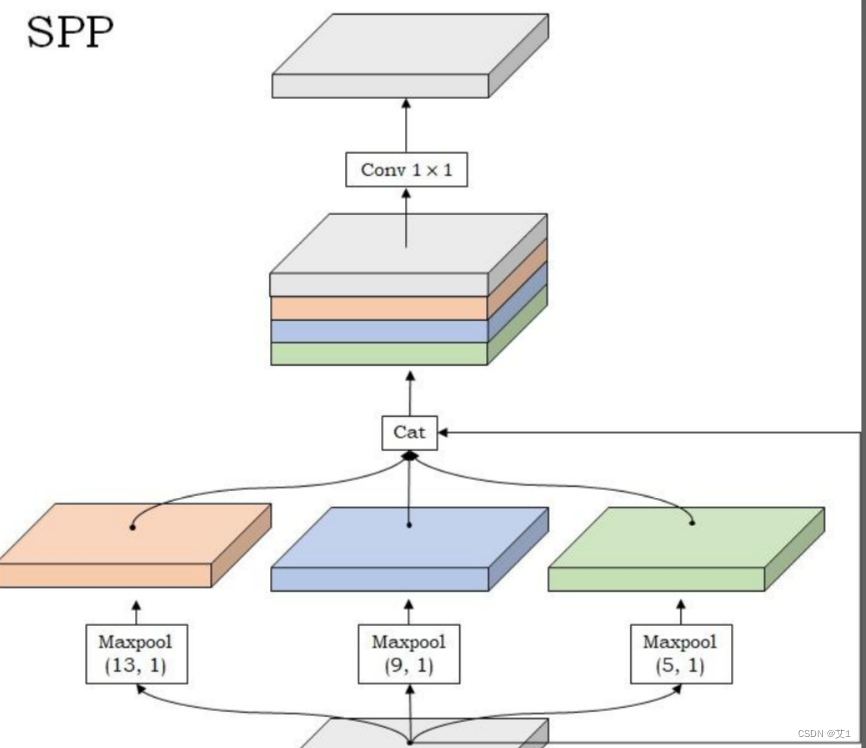
class SPP(nn.Module):
"""
Spatial Pyramid Pooling
"""
def __init__(self):
super(SPP, self).__init__()
def forward(self, x):
x_1 = torch.nn.functional.max_pool2d(x, 5, stride=1, padding=2)
x_2 = torch.nn.functional.max_pool2d(x, 9, stride=1, padding=4)
x_3 = torch.nn.functional.max_pool2d(x, 13, stride=1, padding=6)
x = torch.cat([x, x_1, x_2, x_3], dim=1)
return x借鉴YOLOV5中的CSP结构:

class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(BottleneckCSP, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k=1)
self.cv2 = nn.Conv2d(c1, c_, kernel_size=1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, kernel_size=1, bias=False)
self.cv4 = Conv(2 * c_, c2, k=1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
"""
class BottleneckCSP(nn.Module):
#CSP结构
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)#对应上面网络结构图的上面的分支的第一个CBL
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)#对应上面网络结构图的下面的分支的conv
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)#对应上面网络结构图的上面的分支的conv
self.cv4 = Conv(2 * c_, c2, 1, 1)#对应最后的CBL
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.SiLU()#对应Concat后的Leaky ReLU,这里看到后期的版本是改成了SiLU
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
#nn.Sequential--序贯模型是函数式模型的简略版,为最简单的线性、从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠。
#self.m对应X个Resunit or 2 * X个CBL(对应的切换是通过Bottleneck类中的True 或 False决定,True为X个Resunit,False为2 * X个CBL)
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))#对应上面网络结构图的上面的分支
y2 = self.cv2(x)#对应上面网络结构图的下面的分支
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
#torch.cat对应Concat
#self.bn对应Concat后的BN
转载于:https://blog.csdn.net/weixin_55073640/article/details/122614176SAM结构:SAM是模仿新出的YOLOv4里的设计,结构非常得简单
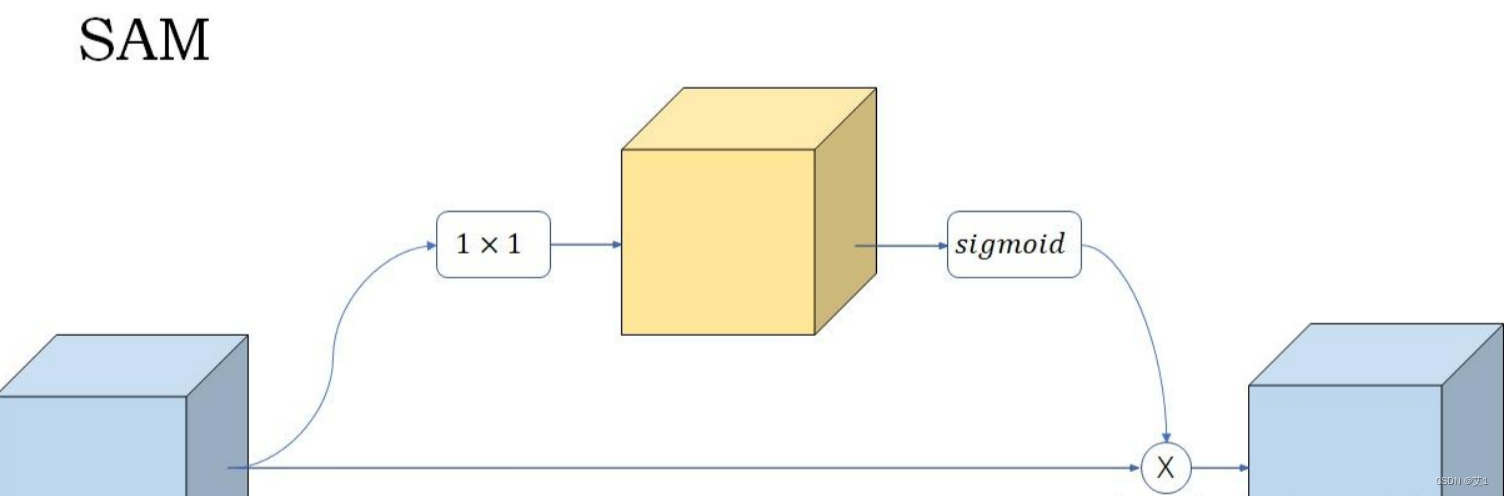
class SAM(nn.Module):
""" Parallel CBAM """
def __init__(self, in_ch):
super(SAM, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_ch, in_ch, 1),
nn.Sigmoid()
)
def forward(self, x):
""" Spatial Attention Module """
x_attention = self.conv(x)
return x * x_attention主要改进点:
1.改进Backbone
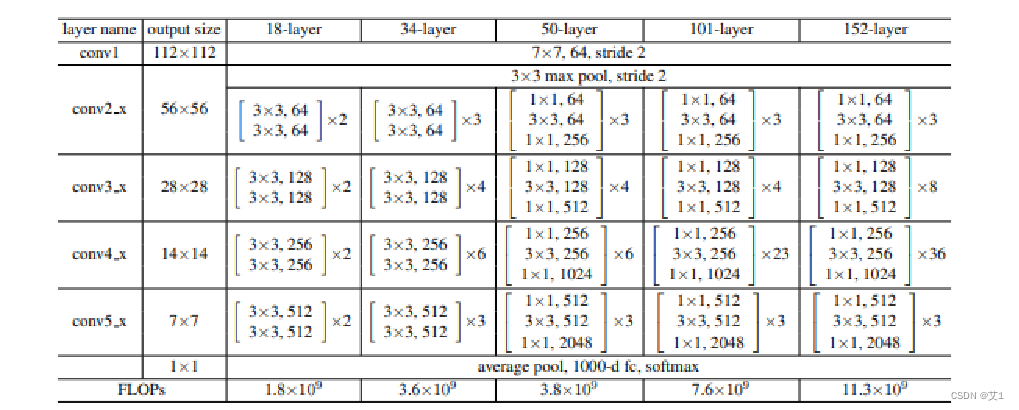
官方的YOLOv1的主干网络是参考了GoogLeNet设计的(没有inception结构),直接替换成ResNet18。
2.添加一个Neck
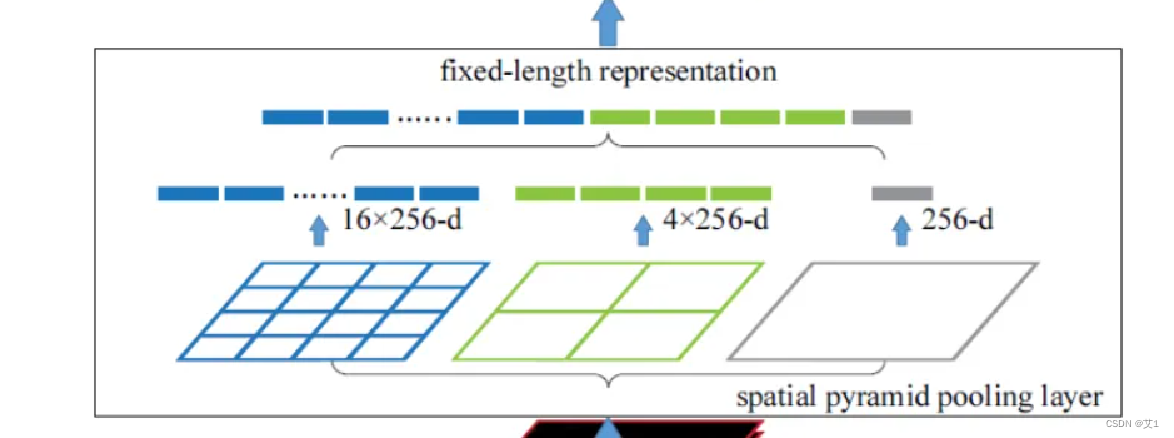
SPP接受的输入特征图大小是13x13x512,经过四个maxpooling分支处理后,再汇合到一起,那么得到的是一个13x13x2048的特征图,这里,我们会再接一个1x1的卷积层(conv1x1+BN+LeakyReLU)将通道压缩一下,这个1x1的卷积层没有在图中体现出来。
3.数据增强
随机地从图像中剪裁出一部分图像,作为输入数据
常用的随机翻转为水平翻转
常用的色彩空间变化操作包括调整图像对比度(contrast)、调整图像饱和度(saturation)、调整图像色调(hue)以及从RGB至HSV的图像颜色空间的转换。通过这些色彩增强方式,可使得模型避免对颜色特征产生过度的依赖,导致过拟合。
4.多尺度训练(YOLOV2)
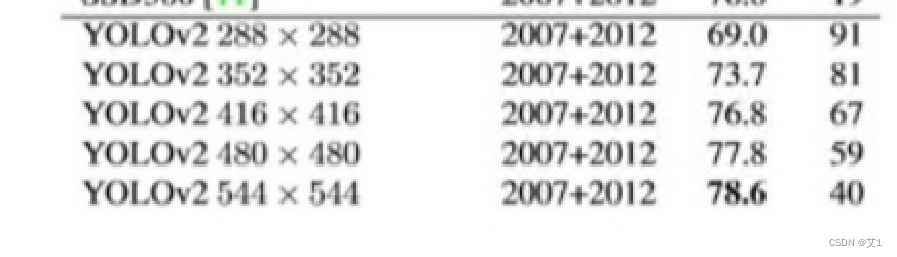
多尺度训练技巧:即在训练过程中,不断随机改变输入图像的大小,图像大小改变了,那图像中的物体大小也会跟着发生变化,其目的就是让模型能够见到更多尺度的物体,缓解模型对尺度变化不敏感的问题。 借鉴了YOLOv2工作给出的多尺度配置,每训练10次,就随机从{320,352,384,416,448,480,512,544,576,608}中抽取一个新的尺寸,用做接下来训练中的图像尺寸。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









