









 本文详细介绍了如何基于Kaggle上的carobjectdetection数据集构建用于小汽车检测的DataSet。首先查看数据集结构,然后通过Pandas和OpenCV验证数据,并创建了一个名为CarDetectionDataSet的类,该类能够处理多目标检测情况,并将边界框信息转换为适合神经网络的格式。最后,展示了如何从这个DataSet中获取样本并进行预处理。
本文详细介绍了如何基于Kaggle上的carobjectdetection数据集构建用于小汽车检测的DataSet。首先查看数据集结构,然后通过Pandas和OpenCV验证数据,并创建了一个名为CarDetectionDataSet的类,该类能够处理多目标检测情况,并将边界框信息转换为适合神经网络的格式。最后,展示了如何从这个DataSet中获取样本并进行预处理。
本文使用平台: kaggle
使用数据集: car object detection
任务目标: 检测出图像中的小汽车.

一.加载数据集
1.查看数据集结构

基本只用了training_images文件夹和train_solution_bounding_boxes (1).csv文件里的内容
先查看train_solution_bounding_boxes (1).csv文件里都有什么:
import numpy as np
import pandas as pd
import os
df = pd.read_csv("/kaggle/input/car-object-detection/data/train_solution_bounding_boxes (1).csv")
df.head()
输出结果:
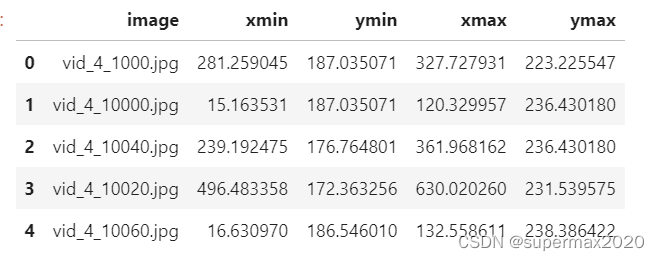
image应该是文件名, 其他四个应该是顶点坐标.
一张图片多个物体的情形
先看一下是否存在一张图片多辆车:
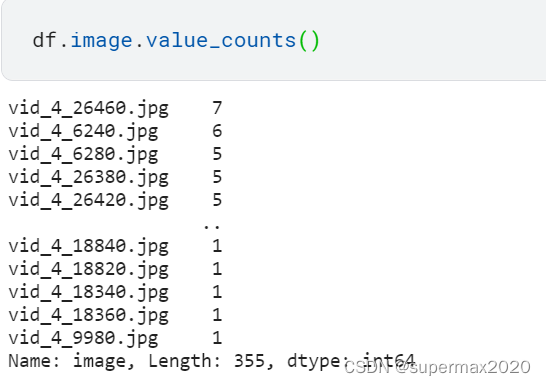
接着看这些车的位置:
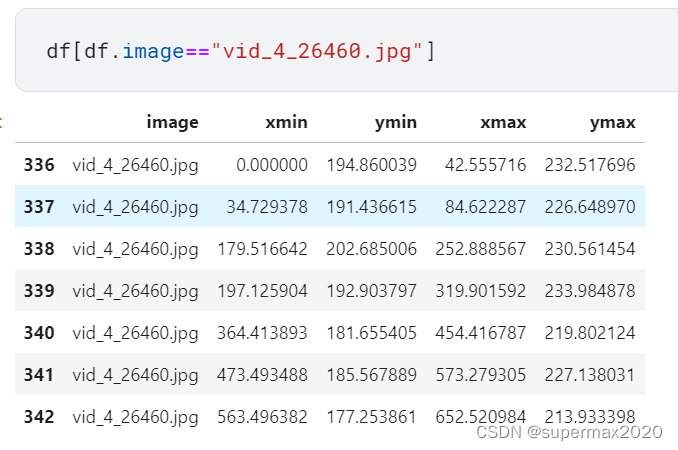
查看一下这张图片:
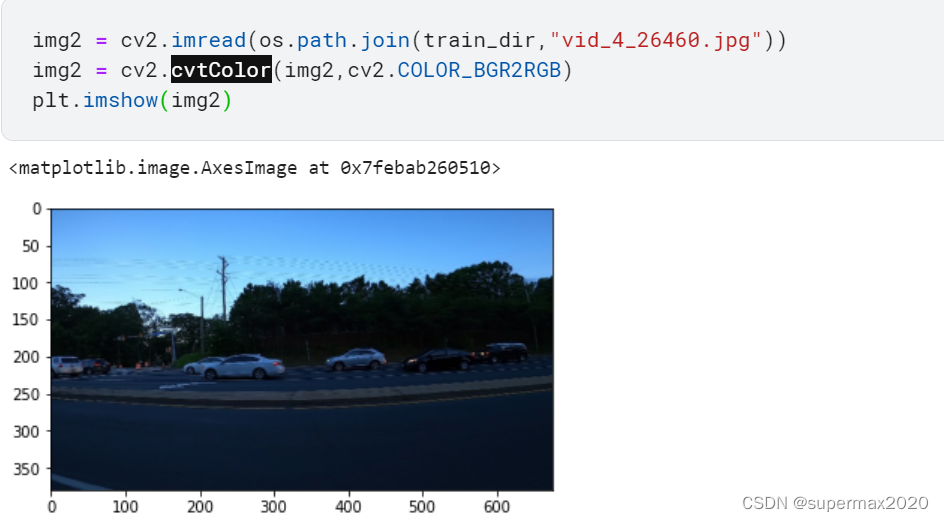
所以还需要考虑多辆车的情况
2. 验证一下数据表的属性
import cv2
import matplotlib.pyplot as plt
img = cv2.imread(os.path.join(train_dir,df["image"][0]))
# cv2.imread将图片读取并保存为numpy.ndarray
print(img.shape)# (380, 676, 3)
plt.imshow(img)
输出:

验证bounding box:
img = cv2.rectangle(img,(df.xmin[0].astype(np.int32),df.ymin[0].astype(np.int32)),(df.xmax[0].astype(np.int32),df.ymax[0].astype(np.int32)),(220,0,0),3)
plt.imshow(img)

可以判断之前的猜测是大体正确的.
image: 文件名
xmin: 左上点的横坐标
ymin: 左上点的纵坐标
xmax: 右下点的横坐标
ymax: 右下点的纵坐标
3. 正式建立DataSet类
__getitem__方法需要返回: 图片以及BoundingBox的位置
图片直接返回RGB图像(每一个像素在[0,255],float类型)
其中, BoundingBox的位置表示为: (x,y,w,h)
x,y分别是中心点坐标,w,h是BoundingBox的宽和高
class CarDetectionDataSet(Dataset):
def __init__(self,df,dataDir):
super().__init__()
self.df = df
self.df["xmid"] = (self.df.xmin+self.df.xmax)/2
self.df["ymid"] = (self.df.ymin+self.df.ymax)/2
self.df["w"] = self.df.xmax-self.df.xmin
self.df["h"] = self.df.ymax-self.df.ymin
self.imageID = df.image.unique()
self.dataDir = dataDir
def __getitem__(self, idx):
imageID = self.imageID[idx]
image = cv2.imread(os.path.join(self.dataDir,imageID))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = t.FloatTensor(image)
image = image/255
df1 = self.df[self.df.image==imageID][["xmid","ymid","w","h"]]
label = t.FloatTensor(df1.to_numpy())
return image, label
def __len__(self):
return self.imageID.shape[0]
测试一下:
carData = CarDetectionDataSet(df,train_dir)
dataloader = DataLoader(carData,batch_size = 5)
itr = iter(dataloader)
a,b = itr.next()
x,y,w,h = b[0][0].numpy()
img = cv2.rectangle(a[0].numpy(),((x-w/2).astype(np.int32),(y-h/2).astype(np.int32)),((x+w/2).astype(np.int32),(y+h/2).astype(np.int32)),(220,0,0),3)
plt.imshow(img)

数据集加载部分这样应该就大体正确了!
之后求loss的时候需要快捷地判断某个grid是否存在目标,现在这样标注很难实现,所以再改一下:
class CarDetectionDataSet(Dataset):
def __init__(self,df,dataDir):
super().__init__()
self.df = df
self.df["xmid"] = (self.df.xmin+self.df.xmax)/2
self.df["ymid"] = (self.df.ymin+self.df.ymax)/2
self.df["w"] = self.df.xmax-self.df.xmin
self.df["h"] = self.df.ymax-self.df.ymin
self.imageID = df.image.unique()
self.dataDir = dataDir
def cvt_label(self,labels):# labels是: n*4的矩阵,分别是x,y,w,h,返回值的label是SxSx5
bbox_labels = t.zeros(Grid_y_num,Grid_x_num,5)
for label in labels:
x,y,w,h = label
i = int(y*Grid_y_num)
j = int(x*Grid_x_num)
bbox_labels[i][j][0] = x%(1/Grid_x_num)*Grid_x_num# x
bbox_labels[i][j][1] = y%(1/Grid_y_num)*Grid_y_num# y
bbox_labels[i][j][2] = w
bbox_labels[i][j][3] = h
bbox_labels[i][j][4] = 1
return bbox_labels
def __getitem__(self, idx):
imageID = self.imageID[idx]
image = cv2.imread(os.path.join(self.dataDir,imageID))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = t.FloatTensor(image)
image = image/255
df1 = self.df[self.df.image==imageID][["xmid","ymid","w","h"]]
label = t.FloatTensor(df1.to_numpy())
tmp = np.array([1/image.shape[1],1/image.shape[0],1/image.shape[1],1/image.shape[0]])
for i in range(label.shape[0]):
label[i]*= tmp;
return image, self.cvt_label(label)
def __len__(self):
return self.imageID.shape[0]
这样的label是一个SxSx5的Tensor
label[i,j]是一个长度为5的tensor,对应着一个grid的x,y,w,h,c信息.
如果该grid包含物体,则c为1,否则为0

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









