







语法分析——自上而下分析
语法分析是编译过程的核心部分,它的任务是在词法分析识别出单词符号串的基础上,分析并判定程序的语法结构是否符合语法规则。
语法分析器在编译程序中的地位
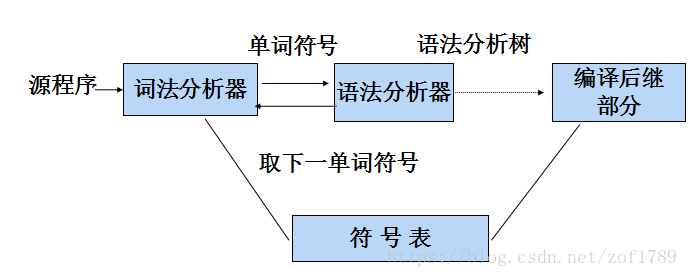
按照语法分析树的建立方法,我们可以粗略地把语法分析办法分成两类,一类是自上而下分析法,一类是自下而上分析法。
自上而下分析的主旨是,对任何输入串,试图用一切可能的办法,从文法的开始符号(根节点)出发,根据文法自上而下地为输入
串建立一棵语法树,或者说为输入串寻找一个最左推导。这种分析过程本质上是一种试探过程,是反复使用不同产生式谋求匹配
输入串的过程。
例:假定有文法(1)S—>xAy (2)A—>**|* 以及输入串x*y(记为α)。
为了自上而下构造α的语法树,我们首先按文法的开始符号产生一个根结S,并让指示器ip指向输入串的第一个符号x,然后用S的
规则将这棵树发展为:
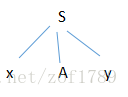
我们希望用S的子结从左至右地匹配整个输入串α。首先,此树的最左子结是以终结符x为标志的子结,它和输入串的第一个符号
相匹配。于是应将ip调整为指向下一个输入符号*,并让第二个子结A去进行匹配。非终结符A有两个候选,我们试着用它的第一
个候选式去匹配输入串,则语法树发展为下图:
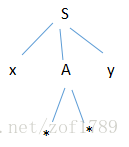
A的左子结和ip所指的符号*相符,但是A的第二个子结和y不符,故的第一个候选并不适用,应看A的第二个候选。用A的第二个
候选去匹配输入串,则语法树发展为下图:
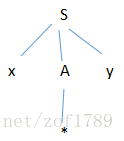
A只有一个子结*而且它和ip所指的符号串相一致,于是A完成匹配任务。S的第三个子结y与y相匹配,则y完成匹配任务。至此,
完成了α构造语法树的任务,证明了α是一个句子。
实现这种自上而下的带回溯试探法的一个简单的途径是让每个非终结符对应一个递归子程序。每个这种子程序可作为一个布尔过
程。一旦发现他的某个候选与输入串相匹配,就用这个候选去扩展语法树,并返回“真”值;否则,保持原来的语法树和ip值不
变,并返回“假”值。
自上而下分析法存在的问题:
P=>+Pα 当试图用P去匹配输入串时,在没有识别任何输入符号的情况下,又得重新要求P去进行新的匹配,这样一来,使推
导无限循环下去。
2.回溯的不确定性,要求我们将已经完成工作推倒从来
匹配不成功,需要回溯。需要把已经做过的一大堆工作(各种表格工作、语义分析等)推倒重来,既费时又费力.
3.虚假匹配的问题
例如上述的例子,考虑输入串x**y。若对A首先使用第二个候选式,A将成功地把它的唯一的子结*匹配于输入串的第二个符号,
但是S的第三个子结y与第三个输入符号*不匹配。因而导致了无法识别输入串x**y是个句子,然而,若A首先使用它的第一个候选
**,则整个输入串即可获得成功分析。这意味着,A首先使用第二个候选所得的成功匹配是虚假的。由于这种现象的产生,我们
需要更复杂的回溯技术。一般来说,消除虚假匹配是很困难的,但若从最长的候选开始匹配,虚假匹配的现象就会减少。
4.不能准确地确定输入串中出错的位置
当最终报告分析不成功时,难
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 967
967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









