







第一部分 --- 消除回溯问题
之所以会出现回溯问题是因为当我们在遇到非终结符与给定字符不匹配时,选择这个非终结符的候选式继续展开匹配的时候采用的是逐个试探法,从第一个候选式开始展开与匹配判断如果不匹配的话就回溯到非终结符,然后再使用下一个候选式展开并匹配
逐个试探法的效率较低,且还会涉及到回溯操作,那么我们有没有办法直接选择非终结符的一个正确的候选式来进行匹配,提高效率呢? --- 答案是有的!

1.a是终结符集合中的元素
但是问题来了,一般来说两个候选的首符集出现交集的情况是比较多的,为了解决这个问题,下面来介绍一个算法,对所有候选进行处理,使得不同候选的首符集尽可能的不出现交集。
1.A‘ 是我们引入的一个非终结符
2.提取公共左因子,以及引入新的非终结符的的目的就是尽可能的保证每个非终结符的候选之间的首符集没有交集
3.首字符集合的英文名就是First集合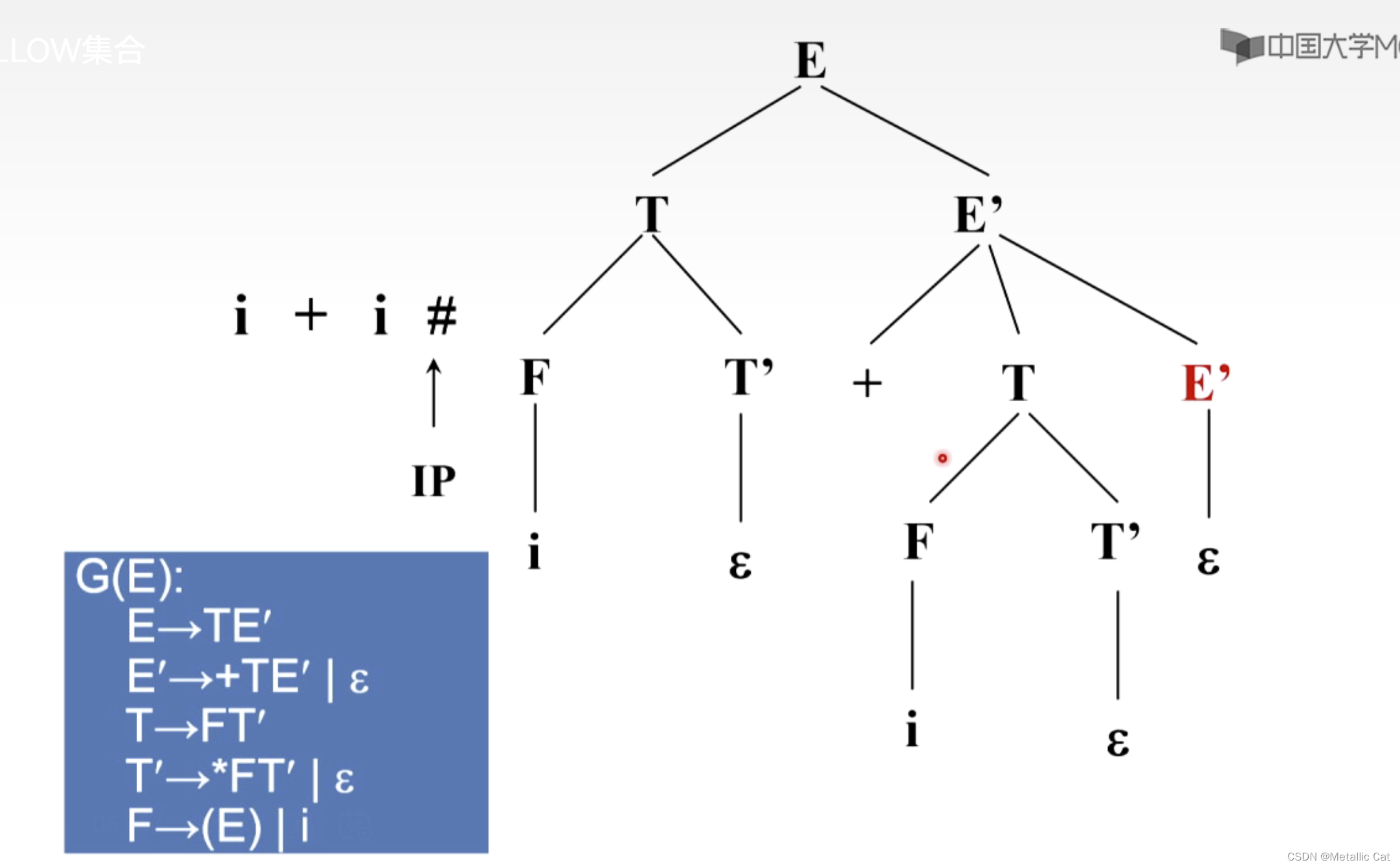
1.空字字符不需要和任何字符进行匹配就能够匹配成功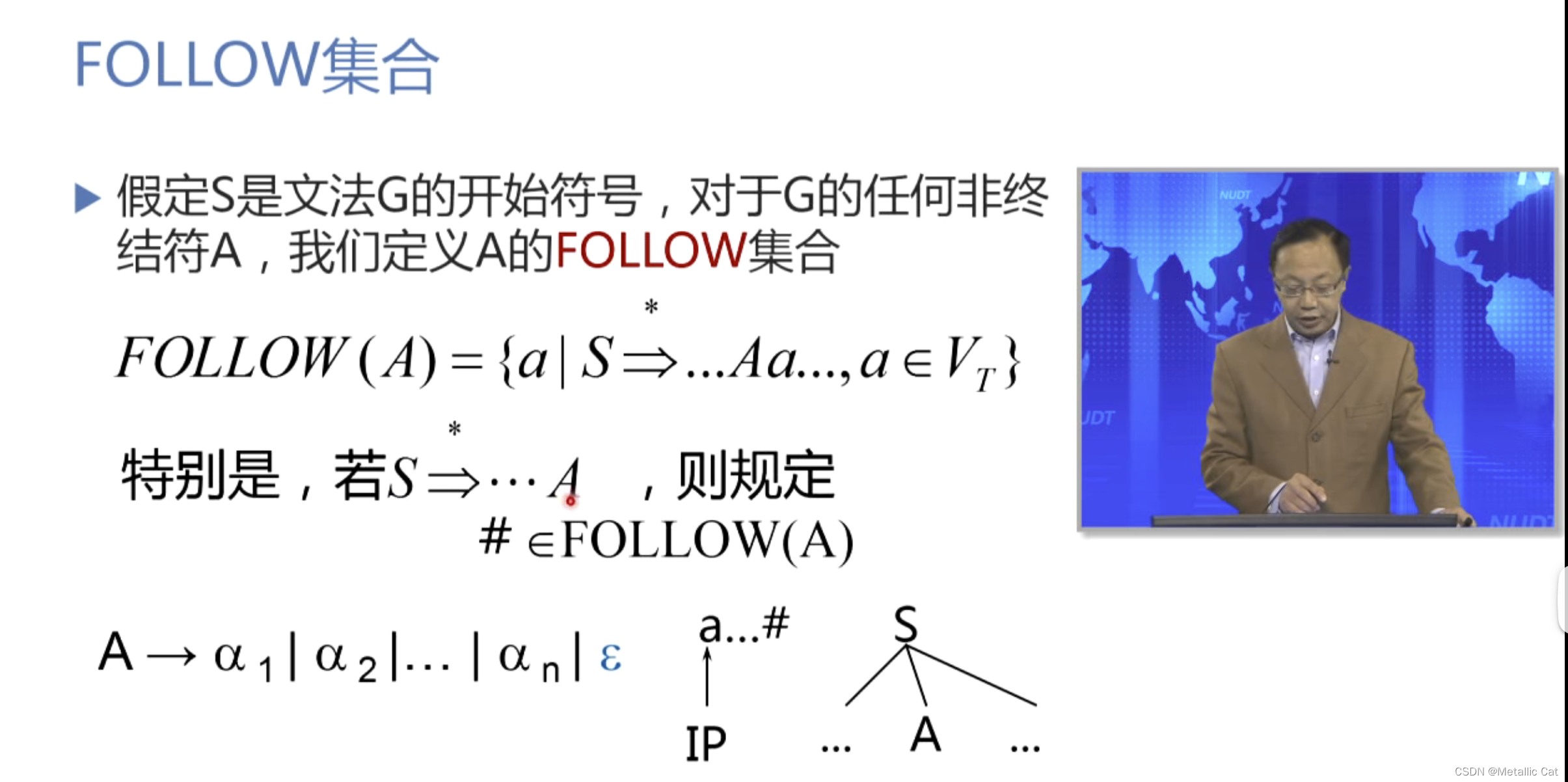
那么我们什么时候选取空字符号医婆塞洛来进行匹配呢?
答案是当满足下面这两个条件的时候选用医婆塞洛来进行匹配:
给定字符a,在与非终结符A不匹配后如果:(非终结符A中存在首字符集中含有空字字符的候选C)
1.非终结符A中除C外的所有候选的首字符集中都不包含字符a
2.通过文法的开始符号能够推出一个句型,这个句型中存在非终结符A后面跟着我们要分析的字符a
满足这两个条件时我们才能够选择候选式C进行匹配(空字字符不需要和任何字符进行匹配就能够匹配成功)
(PS:满足条件1和2的字符a都是非终结符A的FOLLOW(A)集合中的一个元素)
1.LL(1)文法中的第一个L表示我们从左往右扫描字符串,第二个L表示我们的分析过程是最左推导(从左往右逐步匹配),最后一个1表示我们推导时每一步只需向前查看一个符号
2.关于第三点这个条件其实是根据FIRST集合和FOLLOW集合的定义得到的:
一个候选式的FIRST集合的定义是通过这个候选式能够推出的所有句型的第一个字符的集合
一个非终结符的FOLLOW集合的定义是所有只能够与这个非终结符中首字符集(FIRST集合)中包含空字字符的候选式匹配成功的字符,且从开始符号出发能够推出非终结符在前这个字符在后的句型的所有字符的集合
结合来看就是:
一个非终结符的FELLOW集合中的任意一个字符元素都不能够存在于这个非终结符的任意一个候选式的首字符集中,如果存在的话就证明这个字符元素能够被一个候选式匹配成功,不符合FELLOW集合的定义
再翻译过来就是:
一个非终结符的FELLOW集合与其任意一个候选式的FIRST集合都无交集
给定一个文法,先将这个文法消除左递归,然后提取左公共因子。
经过上面这两步后的文法如果满足上面提到的三个条件的话,则这个文法就是LL(1)文法,我们就能够对这个文法使用LL(1)分析法
第二部分 --- FIRST集合和FELLOW集合的构造算法
1.FIRST集合 --- 首先获取从候选式出发(包括候选式本身)能够推导出的所有句型,然后再这些句型中找出以终结符作为首字符的句型,然后取我们找到的句型的首字符放入导FIRST集合中,所有我们找到的句型都被取完后FIRST集合就构造完毕了
2.非终结符A的FELLOW集合 --- 首先找出所有非终结符A无法匹配的词法分析器给出的终结符,然后从文法的所有句型中找到存在非终结符A的句型,然后从在这些句型中找到非终结符A,并依次判断非终结符A后面第一个字符是不是终结符,如果是的话又在不在我们前面找到的终结符集合中,如果在的话将这个终结符放到A的FELLOW集合中
就这样不停的比较下去,所有选出的句型都比较完毕后A的FELLOW集合构造完毕
上面这一段总结了候选式α可能出现的所有形式
1.VT是终结符集合,VN是非终结符集合
2.空字符号作为终结符的特点就是不经过匹配就能够匹配成功,且匹配成功后语法树的指针会移动,词法分析器处指向待分析的单词的指针不会移动
然后空字符号能够放入到一个文法符号的FIRST集合中的前提是:文法符号对应的产生式中存在只含有空字符号的候选式
整个的构造过程是:
1.从第一个产生式开始,到最后一个产生式结束构造每个文法符号的FIRST集合
2.如果在构造的过程中存在有文法符号的FIRST集合发生变化,我们就继续从上往下扫描,扫描完最后一个产生式后再回到第一个产生式重新开始扫描
3.直到从上往下扫描一次后所有文法符号的FIRST集合都不发生改变时才能够停止扫描
1. a \ b 这个也是一个集合,表示的是a集合中除去b集合中所有元素后得到的集合
2.当空字符号作为候选式的开头的时候,如果这个空字符号后面还有文法符号的话,则这个候选式的开头会自动更新为空字符号后面的文法符号,只有当候选式中只存在空字符号的时候,空字符号才能够成为候选式的开头
(原因是空字符号作为终结符时的特性)

构造FELLOW集合的总体步骤和构造FIRST集合一样:
1.从第一个产生式开始构造每个非终结符的FELLOW集合,到最后一个产生式构造每个非终结符的FELLOW集合结束
2.在构造的过程中一旦出现某个非终结符的FELLOW集合发生改变,我们就继续从上往下扫描,扫描完最后一个产生式后再回到第一个产生式重新开始扫描
3.就这样不停的扫描,直到从第一个产生式开始扫描到最后一个产生式结束后没有任何一个非终结符的FELLOW集合发生改变时,扫描才能够结束
1.给定一个经过消除递归和提取左公因子后的文法,首先我们要做的是计算这个文法中的每个文法符号的FIRST集合:
对于终结符而言其FIRST集合中包含的只有一个元素,那就是它本身。
对于非终结符而言,其FIRST集合就需要我们根据2,3规则来找出它的FIRST规则
2.计算玩FIRST所有文法符号的FIRST集合后我们才开始计算所有非终结符的FELLOW集合
1.对于任何一个候选式,其开头前面都有无限多个空子符号 --- 一波塞洛(因为是空字符号,所以实际上都被省略掉了),其结尾后面也有无限多个空字符号,当然我们也可以直接忽略掉这些空字符号,因为是“空”嘛。
2.根据1我们可以知道在使用FELLOW集合的构造规则的时候不要忘了空字符号 --- 我们可以让它出现在候选式的开头的前面或者是结尾的后面,我们也可以不考虑空字符号
3.FELLOW集合的构造规则中的α和β既可以是终结符也可以是非终结符,还可以是非终结符和终结符的组合体
4.计算完文法的FIRST集合和FELLOW集合之后我们再对这个文法是否符合成为LL(1)文法的三个条件进行判断,如果都符合的话这个文法就是LL(1)文法,我们就能对这个文法使用LL(1)分析法了















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









