







本系列博客将要总结最基本的一些数据结构与算法分析的问题,说到算法,排序显然是最基础的,但并不是所有人都理解的很好。本文也仅仅是个人的一些总结,欢迎指正。
排序一般分为内排序和外排序,所有待排数据都在内存的即为内排序,反之为外排序。而我这里将着重讨论内排序。
内排序又分为基于比较的排序和非基于比较的排序。
基于比较的排序
交换类排序
冒泡排序
作为C语言入门的一些教材,经常会以冒泡作为入门的例子。
全文所贴代码的swap函数都如下:
void Swap( int& a, int& b )
{
int c = a;
a = b;
b = c;
}冒泡(也有极个别叫沉石)的原理是相邻的数字两两进行比较,按照从小到大或者从大到小的顺序进行交换,这样一趟过去后,最大或最小的数字被交换到了最后一位,然后再从头开始进行两两比较交换,直到倒数第二位时结束,其余类似。
例子说明:
输入: 5, 9, 4, 2
第一趟(外循环):
第一次比较(内循环):(5, 9), 4, 2 => 5, 9, 4, 2
第二次比较(内循环): 5, (9, 4), 2 => 5, 4, 9, 2
第三次比较(内循环): 5, 4, (9, 2 ) => 5, 4, 2, 9
第二趟(外循环):
第一次比较(内循环): (5, 4), 2, 9 => 4, 5, 2, 9
第二次比较(内循环): 4,( 5, 2), 9 => 4, 2, 5, 9
第三趟(外循环):
第一次比较(内循环): (4, 2), 5, 9 => 2, 4, 5, 9
根据上述例子可以得出最简单的冒泡排序的写法(代码仅供参考):
void BubbleSort( int* pData, int n )
{
for (int i = n - 1; i > 0; --i)
{
for (int j = 0; j < i; ++j)
{
if (pData[j + 1] < pData[j])
{
Swap(pData[j + 1], pData[j]); //小的值往上冒泡
}
}
}
}接下来我们可以思考一下怎么优化这个算法,我们会发现,每次最后停止比较的地方,那之后的值其实已经稳定了。优化代码如下,此处不细说,留给读者琢磨。
\* bubble sort*\
void BubbleSort( int* pData, int n )
{
int lastSwapPos = n - 1;
for (int i = n - 1; i > 0; i = lastSwapPos)
{
lastSwapPos = 0;
for (int j = 0; j < i; ++j)
{
if (pData[j + 1] < pData[j])
{
Swap(pData[j + 1], pData[j]);
lastSwapPos = j;
}
}
}
}冒泡是稳定的排序,一般没有跳跃式的比较,也即相邻数据的比较,都是稳定的排序,反之是不稳定的。
稳定排序: 保证排2个相等的数,在排序前后其相对位置不发生改变
比如: dict = {“1”: 5, “2”: 9, “3”:2, “4”: 4, “5”: 2 } 这样的数据结构,根据value排序,如果出现了
dict = {“5”: 2, “3”:2, “4”: 4, “1”: 5, “2”: 9} , 即value都为2,注意key,他们的位置发生了一次调换,我们认为这样的排序是不稳定的。接下来讲了不稳定排序后,大家可以手动排序看看其区别。
冒泡的平均时间复杂度和最差时间复杂度都是 O(n2) , 空间复杂度是 O(1) 。 适用于 n 较小的情况。
快速排序
快排的原理是,通过一趟扫描将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
此处即选一个pivot的值,让比其小的割到其左边,比其大的割到其右边。一般选第一个值为pivot。
例子说明:
输入: 5, 9, 2, 4
step1:
取出5作为pivot;
第一次比较: 5 > 4, 4, 9, 2, 5
第一次比较: 5 < 9, 4, 5, 2, 9
第三次比较: 5 > 2, 4, 2, 5, 9
step2: 对[4, 2] 和[9]分别再用上述方法排序
根据上述例子所写代码(代码仅供参考):
void QuickSort( int* pData, int n )
{
QSort(pData, 0, n-1);
}
void QSort( int* pData, int low, int high )
{
if (low < high)
{
int pivot = Partition(pData, low, high);
QSort(pData, low, pivot - 1);
QSort(pData, pivot + 1, high);
}
}
int Partition( int* pData, int low, int high )
{
while (low < high)
{
while (low < high && pData[high] >= pData[low])
{
high--;
}
Swap(pData[high], pData[low]);
while (low < high && pData[low] <= pData[high])
{
low++;
}
Swap(pData[high], pData[low]);
}
return low;
}快排的平均时间复杂度是
插入类排序
插入排序
插入排序的原理是,每一步都将一个待排数据按其大小插入到已经排序的数据中的适当位置,直到全部插入完毕。
例子说明:
输入: 5, 9, 2, 4
第一趟(外循环):
第一次比较(内循环): 9 > 5, 5, 9, 2, 4
第一趟(外循环):
第一次比较(内循环): 2 < 9, 5, 2, 9, 4
第二次比较(内循环): 2 < 5, 2, 5, 9, 4
第三趟(外循环):
第一次比较(内循环): 4 < 9, 2, 5, 4, 9
第二次比较(内循环): 4 < 5, 2, 4, 5, 9
代码如下(仅供参考):
void InsertSort( int* pData, int n )
{
for (int i = 1; i < n; ++i)
{
for (int j = i; j > 0; j--)
{
if (pData[j - 1] > pData[j])
{
Swap(pData[j - 1], pData[j]);
}
else
{
break;
}
}
}
}插排的平均时间复杂度和最差时间复杂度都是
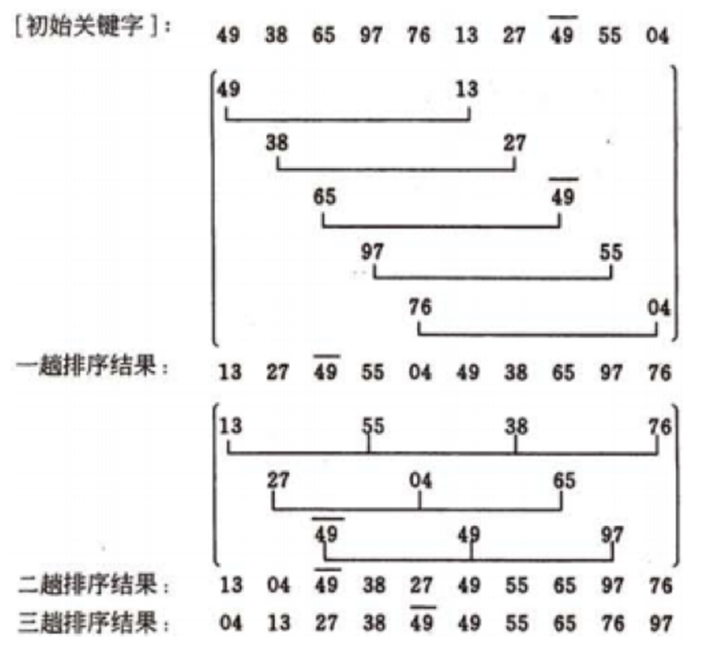
希尔(shell)排序
插入排序在序列基本有序的情况下可以获得接近 O(n)的复杂度
其是直接插入排序的一种改进,增加了递增量,分组比较。注意比较代码,实际就是多了一层while,和一个递增率incr,其它和快排完全一样。
例子说明:
void ShellSort( int* pData, int n )
{
int incr = n;
while (incr > 1)
{
incr = incr / 3 +1;
for (int i = incr; i < n; ++i)
{
for (int j = i; j > incr -1; j -= incr)
{
if (pData[j - incr] > pData[j])
{
Swap(pData[j - incr], pData[j]);
}
else
{
break;
}
}
}
}
}
希尔排序的平均时间复杂度是
选择类排序
简单选择排序
简单选择排序的原理是直接从待排序数组里选择一个最小(或最大)的数字,每次都拿一个最小数字出来,顺序放入新数组,直到全部拿完。
例子说明:
输入: 5, 9, 4, 2
第一趟(外循环): min = 5
第一次比较(内循环): 9 > min: min 不变
第二次比较(内循环): 4 < min: min = 4
第二次比较(内循环): 2 < min: min = 2
交换: 2, 9, 4, 5
第二趟(外循环): min = 9
第一次比较(内循环): 4 < min: min = 4
第二次比较(内循环): 5 > min: min 不变
交换: 2, 4, 9, 5
第三趟(外循环): min = 9
第一次比较(内循环): 5 < min: min = 5
交换: 2, 4, 5, 9
代码如下(仅供参考):
void SimpleSelectionSort( int* pData, int n )
{
int lowIndex;
for (int i = 0; i < n - 1; ++i)
{
lowIndex = i;
for (int j = i + 1; j < n; ++j)
{
if ( pData[j] < pData[lowIndex] )
{
lowIndex = j;
}
}
Swap(pData[i], pData[lowIndex]);
}
}
简单选择排序的平均时间复杂度和最差时间复杂度都是 O(n2) , 空间复杂度是 O(1) 。适合n较小的情况。 是不稳定的排序。
堆排序
堆排序分为建堆和调整堆两部分。
首先有一些基础概念:
堆:
这里的堆(二叉堆),指得不是堆栈的那个堆,而是一种数据结构。
堆可以视为一棵完全的二叉树, 除了最底层之外,每一层都是满的。堆可以利用数组来表示,每一个结点对应数组中的一个元素。
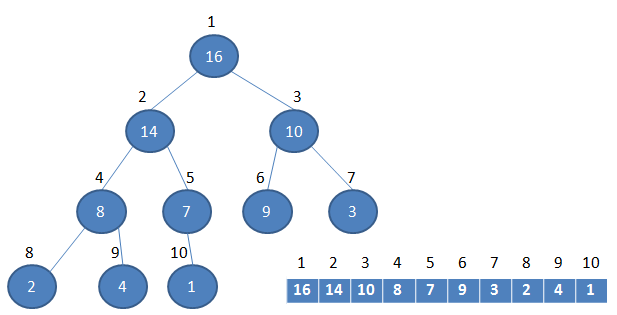
最大堆(最小堆):
是优先队列的一种。所谓最大堆,即每个父节点的元素都大于其子节点的元素。即堆顶是其最大值。
什么是最大堆
节点与数组索引关系:
对于给定的某个结点的下标
i
,可以很容易的计算出这个结点的父结点、孩子结点的下标:
堆排序原理如下:
输入:5, 9, 4, 2, 8, 3
step1: 初始化堆结构:
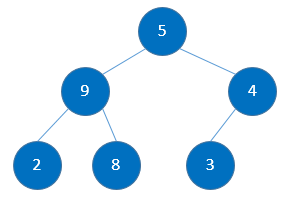
step2: 构造最小值堆,先从最后一个非叶子节点开始调整堆结构,保证得到最小堆:
第一趟: 4 与 3 比较: 4 > 3, 故需调整:
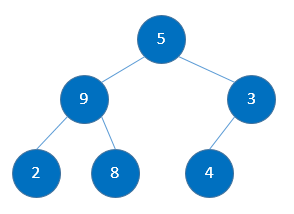
第二趟:9的叶子节点有两个,其中2 < 8, 用2与9比较, 2 < 9, 故需调整:
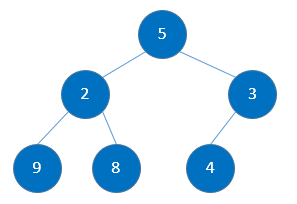
第三趟:5的叶子节点有两个,其中2 < 3, 用2与5比较, 2 < 5, 故需调整:
至此堆构造完毕。
step3:调整堆,得到排序结果
交换堆顶的元素和最后一个元素,取出最后一个元素,重新调整堆结构,重复执行,直到将堆中元素全部取出。
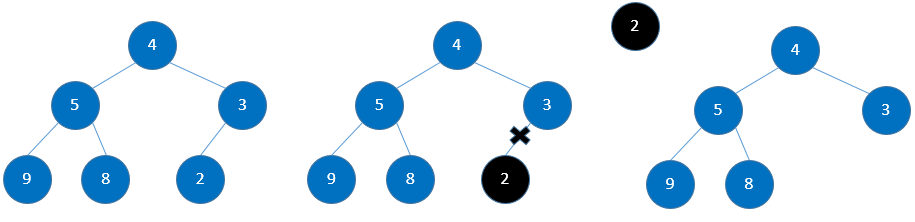
由根节点开始调整堆结构得到:
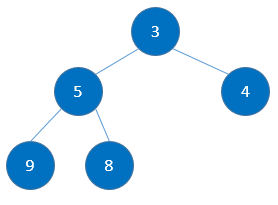
最终得到 :

代码如下(仅供参考)【注意代码是大顶堆】:
void HeapSort( int* pData, int n )
{
//build heap
for (int i = (n - 2)/2; i >= 0; i--)
{
SiftAdjust(pData, i, n - 1);
}
//sort
for (int i = n - 1; i > 0 ; i--)
{
Swap(pData[i], pData[0]); //swap heap top
SiftAdjust(pData, 0, i - 1); //adjust //attention, not i
}
}
void SiftAdjust( int* pData, int low, int high )
{
for (int f = low, i = low * 2 + 1; i <= high; i = i*2 + 1)
{
if (i < high && pData[i + 1] > pData[i])
{
i++;
} //right child is greater than left child
if (pData[f] < pData[i])
{
Swap(pData[f], pData[i]);
}
else
{
break;
}
f = i;
}
}堆排序的平均时间复杂度和最差时间复杂度都是 O(nlogn) , 空间复杂度是 O(1) 。适合n较大的情况。 是不稳定的排序。
归并排序
其实归并排序是最易懂的排序。
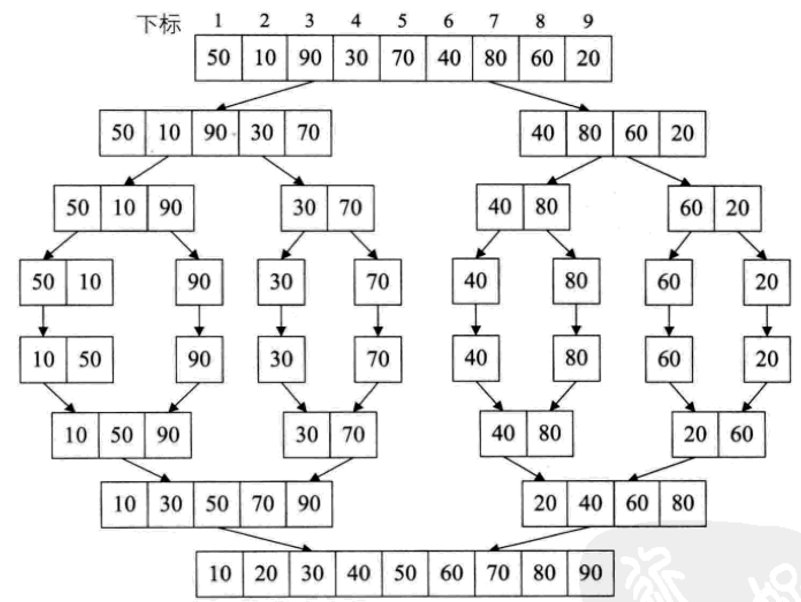
这张图比较好的反应了整个归并的迭代过程。
其原理是把原始数组分成若干子数组,对每一个子数组进行排序,继续把子数组与子数组合并,合并后仍然有序,直到全部合并完,形成有序的数组。
代码如下(仅供参考):
void MergeSort( int* pData, int n )
{
MSort(pData, 0, n-1);
}
void MSort( int* pData, int low, int high )
{
int mid;
if (low < high)
{
mid = low + (high - low) / 2;
MSort(pData, low, mid);
MSort(pData, mid + 1, high);
Merge(pData, low, mid, high);
}
}
void Merge( int* pData, int low, int mid, int high )
{
int* tmpArr = new int[high + 1];
int i, j, k;
for (i = low, j = mid + 1, k = low; i <= mid && j <= high; k++) //attention: k = low, not k =0
{
if (pData[i] <= pData[j])
{
tmpArr[k] = pData[i];
i++;
}
else
{
tmpArr[k] = pData[j];
j++;
}
}
for (; i <= mid; ++i)
{
tmpArr[k++] = pData[i];
}
for (; j <= high; ++j)
{
tmpArr[k++] = pData[j];
}
//
for (int i = low; i <= high; ++i)
{
pData[i] = tmpArr[i];
}
delete []tmpArr;
}归并排序的平均时间复杂度和最差时间复杂度都是 O(nlogn) , 空间复杂度是 O(1) 。适合n较大的情况。 是稳定的排序。
非基于比较的排序
非基于比较的排序一般都是通过空间开销开平衡时间开销的。需要注意它们的特定应用场景。
桶(箱)排序
桶排序是稳定的,消耗空间基本也是最多,大多数情况下也是最快的。
例子说明:
输入:5, 19, 40, 23, 41, 35
step1: 计算桶个数:假定以10为间隔,即每个桶可放10个元素,则需要 (41 - 5) / 10 + 1 = 4个桶
step1: 装桶: 依次遍历每个元素
(5 - 5 + 1) / 10 = 0 , 所以 第一个元素5 放到 0号桶中, 其它元素同理,最终得到
桶0: 5
桶1: 19, 23
桶1: 空的
桶3: 35, 40, 41
step2: 桶内排序(可采用快排之类):
桶0: 5
桶1: 19, 23
桶1: 空的
桶3:35, 40, 41,
step3: 将桶内元素按序取出排列:
5, 19, 23, 35, 40, 41
代码如下(仅供参考):
struct Barrel
{
int node[10];
int count;
};
void BucketSort( int* pData, int n )
{
int max = pData[0];
int min = pData[0];
for (int i = 1; i < n; ++i)
{
if (pData[i] > max)
{
max = pData[i];
}
if (pData[i] < min)
{
min = pData[i];
}
}
int num = (max - min + 1) / 10 + 1;
Barrel* pbarrels = (Barrel*)malloc(sizeof(Barrel)*num);
memset(pbarrels, 0, sizeof(Barrel)*num);
for (int i = 0; i < n; ++i)
{
int k = (pData[i] - min + 1) / 10;
pbarrels[k].node[pbarrels[k].count] = pData[i];
pbarrels[k].count++;
}
int pos = 0;
for (int i = 0; i < num; ++i)
{
QSort(pbarrels[i].node, 0, pbarrels[i].count - 1);
for (int j = 0; j < pbarrels[i].count; ++j)
{
pData[pos++] = pbarrels[i].node[j];
}
}
free(pbarrels); //attention: free not delete
}
复杂度分析:
假设有n个数字, 针对数字的范围,我们分m个桶。
1. 扫描一遍装箱: O(n),
2. 平均情况来看: 每个桶有 n/m 个元素,对每个桶排序的复杂度:(n/m) * log (n/m)
总时间复杂度: O(n + m * n/m * log n/m) = O(n + n * ( logn – logm ) )
桶排序是稳定的。当桶大小为1时,浪费的空间最多,但是时间效率最高为O(n)。
计数排序
例子说明:
输入: 2, 5, 3, 0, 2, 3, 0, 3
step1:
新建一个辅助数组C,大小为 5 - 0 + 1 = 6。
step2: 统计i元素出现的个数
| 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 2 | 0 | 2 | 3 | 0 | 1 |
step3: 统计小于等于i元素出现的个数
| 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 2 | 2 | 4 | 7 | 7 | 8 |
step4: 遍历每个元素,得到其对应有序序列的索引
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| - | - | - | - | - | - | - | - |
第一个元素2:根据step3的结果, 有序序列第4个位置为2
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| - | - | - | 2 | - | - | - | - |
第而个元素5:根据step3的结果, 有序序列第8个位置为5
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| - | - | - | 2 | - | - | - | 5 |
依次类推,当第二出现元素2的时候,位置由4往前挪一个:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| - | 0 | 2 | 2 | - | - | - | 5 |
最终结果为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 2 | 2 | 3 | 3 | 3 | 5 |
代码如下(仅供参考):
void SortTest::CountSort( int* pData, int n )
{
int max = pData[0];
int min = pData[0];
for (int i = 1; i < n; ++i)
{
if (pData[i] > max)
{
max = pData[i];
}
if (pData[i] < min)
{
min = pData[i];
}
}
int countSize = max - min + 1;
int* countArr = new int[countSize];
for (int i = 0; i < countSize; ++i)
{
countArr[i] = 0;
}
for (int i = 0; i < n; ++i)
{
countArr[pData[i] - min]++;
}
for (int i = 1; i < countSize; ++i)
{
countArr[i] += countArr[i - 1];
}
int* tmpData = new int[n];
int value, pos;
for (int i = 0; i < n; ++i) //attention
//for(int i = n-1; i >= 0; i--)
{
value = pData[i];
pos = countArr[value - min];
tmpData[pos - 1] = value;
countArr[value - min]--;
}
for (int i = 0; i < n; ++i) //attention
{
pData[i] = tmpData[i];
}
delete []countArr;
delete []tmpData;
}时间复杂度分析:
分析代码会发现,有关于辅助数组长度的for循环和元素总数的for循环,故为O(n+k)。稳定排序。
基数(鸽巢)排序
在基数排序中,当k很大时,时间和空间的开销都会增大(可以想一下对序列{8888,1234,9999}用基数排序,此时不但浪费很多空间,而且时间方面还不如比较排序。
原理类似桶排序,这里总是需要10个桶(10进制数),多次使用。
首先以个位数的值进行装桶,即个位数为1则放入1号桶,为9则放入9号桶,暂时忽视十位数。依次类推以高一位装桶。基数排序分为分发和收集两部分。
例子说明:
输入: 62, 14, 59, 88, 16
分配10个桶,桶编号为0-9,以个位数数字为桶编号依次入桶,变成下边这样
max = 88 故 总共只有 个位 和 十位
step1: 分发:按个位数大小入桶| 0 | 0 | 62 | 0 | 14 | 0 | 16 | 0 | 88 | 59 |
收集:62,14,16,88,59
step2: 分发:按十位数大小入桶 | 0 | 14,16 | 0 | 0 | 0 | 59 | 62 | 0 | 88 | 0 |
收集:14,16,59,62,88
代码如下(仅供参考):
void SortTest::RadixSort( int* pData, int n )
{
//detect 10 base
int max = pData[0];
int min = pData[0];
//r base, d digit
for (int i = 1; i < n; i++)
{
if( pData[i] > max)
{
max = pData[i];
}
if ( pData[i] < min )
{
min = pData[i];
}
}
int r = 10; //base
int d = 0;
while ( max > 0)
{
d++;
max /= 10;
}
RSort(pData, n, r, d);
}
void SortTest::RSort( int* pData, int n, int r, int d )
{
vector<vector<int>> linkList;
for (int i = 0; i < r; ++i)
{
vector<int> list;
linkList.push_back(list);
}
for (int i = 0; i < d; ++i)
{
Distribute(pData, n, r, i, linkList);
Collect(pData, r, linkList);
}
}
void SortTest::Distribute( int* pData, int n, int r, int i, vector<vector<int>>& list )
{
int power = (int)pow(r, i);
for (int k = 0; k < n; ++k)
{
int index = (pData[k] / power) % r;
list[index].push_back(pData[k]);
}
}
void SortTest::Collect( int* pData, int r, vector<vector<int>>& list )
{
for (int i = 0, k = 0; i < r; ++i)
{
while (!list[i].empty())
{
pData[k++] = list[i][0];
list[i].erase(list[i].begin());
list[i].pop_back();
}
}
}
时间复杂度分析:平均和最差都是
O(logRB)
B是(十进制0-9), R是(个十百千)
基数排序是稳定的。辅助空间同计数排序k+n。
至此,基本的一些排序算法已经全部学习完毕!
还有更多的排序,可参考 经典排序算法















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









