







查找表相关总结
不同的底层实现方式,时间复杂度不同。哈希表优秀的代价是失去了顺序性。
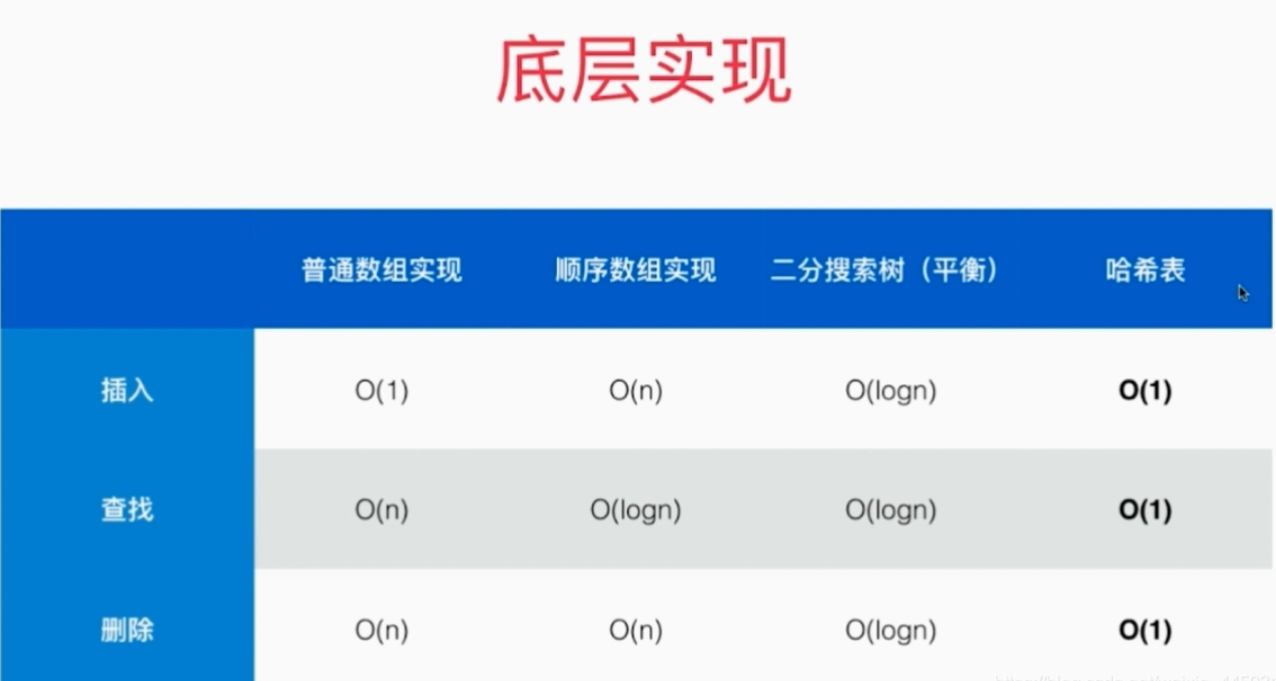
哈希实现相较于平衡树实现的优点就是时间复杂度低。
- 而平衡树实现可以:
- 求数据集中最值;
- 某个元素前驱后继
- 某个元素的floor、ceil
- 某个元素的rank
- 某个排位的元素 select
大白话:
就是先把一组数放入set或者map中,然后.find()!=.end();就是找到了,就怎么操作
类似题目有两个数组的交集,不能重复也即唯一的数用set,能重复的就map,–抵消后注意要>0。
两数之和 find(target-nums【i】) 三数之和四数之和重复的查找表不是很高效就用排序+双指针
回旋镖的数量,其实也就是搞清楚map的key和value到底存放的是啥,怎么根据key来找到value,这点很关键
根据字符出现频率排序用一个mp存储每个字符出现频率,所以key是char,value是int,然后放入vec根据value排序,因为map不能直接排序,而且要自己定义greater(a.second>b.second),排完序的vec要用begin(),end()来遍历,然后输出想要的结果
单词规律 这里很蛋疼是C++没有.split,所以要自己实现一下,用vector &v实现,然后就双映射了,str2char,char2str
0. set和map——.find()!=.end()消消乐
【349. 两个数组的交集】
方法一:排序 + 双指针
时间复杂度:O(m log m+n log n)其中 m 和 n 分别是两个数组的长度。对两个数组排序的时间复杂度分别是 O(mlogm) 和O(nlogn),双指针寻找交集元素的时间复杂度是 O(m+n),因此总时间复杂度是 O(mlogm+nlogn)。
空间复杂度:O(log m+log n)其中 m 和 n 分别是两个数组的长度。空间复杂度主要取决于排序使用的额外空间。
方法二:两个集合 O(n1+n2),O(n1+n2)
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
vector<int> vec;
unordered_set<int> st1,st2;
int n1 = nums1.size(),n2=nums2.size();
for(int i = 0;i<n1;++i) {st1.insert(nums1[i]);}//先用一个set存放一个nums
for(int j = 0;j<n2;++j){
if(st1.find(nums2[j])!=st1.end()){//在第二个set里find,交集就insert
st2.insert(nums2[j]);
}
}
for(auto it = st2.begin();it!=st2.end();it++){vec.push_back(*it);}//set的元素要用迭代器来引用
return vec;
}
};
优化: 只用到了一个unordered_set,空间上进行了优化
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
vector<int> vec;
int n1 = nums1.size(),n2=nums2.size();
unordered_set<int> st1{nums1.begin(),nums1.end()};//先用一个set存放一个nums
for(auto &it:nums2){//注意这里的it就已经是nums2的元素了,不是下标
if(st1.find(it)!=st1.end()){//在第二个set里find,交集就insert
st1.erase(it);
vec.push_back(it);
}
}
return vec;
}
};
【350. 两个数组的交集 II】
优化: 只用一个unordered_map
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
unordered_map<int,int> mp1;
vector<int> vec;
for(auto &i:nums1) {mp1[i]++;}//老规矩,先放一个nums进集合,不能重复就set,可以就map
for(auto &j:nums2){//遍历第二个nums
if(mp1.find(j)!=mp1.end()){
vec.push_back(j);//这里的j就是元素了,不是下标
mp1[j]--;//mp1交了一个元素出去就要--,类比连连看
if(mp1[j]==0){//这里要注意控制mp1的size,如果没了就要erase
mp1.erase(j);
}
}
}
return vec;
}
};
进阶三问:
Q1:如果给定的数组已经排好序呢?你将如何优化你的算法?
A:排序+双指针,所以排好序就用双指针,值相等就push_back进vec,On
Q2:如果 nums1 的大小比 nums2 小很多,哪种方法更优?
- 哈希计数 将较小的数组哈希计数,随后在另一个数组中根据哈希来寻找。
时间复杂度:O(max(n,m));空间复杂度:O(min(n, m))
Q3:如果 nums2 的元素存储在磁盘上,内存是有限的,并且你不能一次加载所有的元素到内存中,你该怎么办?
- 通过归并外排将两个数组排序后再使用排序双指针查找
对应进阶问题三,如果内存十分小,不足以将数组全部载入内存,那么必然也不能使用哈希这类费空间的算法,只能选用空间复杂度最小的算法,即解法一。
但是解法一中需要改造,一般说排序算法都是针对于内部排序,一旦涉及到跟磁盘打交道(外部排序),则需要特殊的考虑。归并排序是天然适合外部排序的算法,可以将分割后的子数组写到单个文件中,归并时将小文件合并为更大的文件。当两个数组均排序完成生成两个大文件后,即可使用双指针遍历两个文件,如此可以使空间复杂度最低。
注意:C++ stl中实现的map,只要用 [ ]访 问过的元素,如果之前不存在,也会插入这个元素,相应的val会是默认值。
所以对应操作之前,为了排除二义性,先find 一下存不存在这个元素,再去用[ ]操作。
【242. 有效的字母异位词】
方法0:排序
class Solution {
public:
bool isAnagram(string s, string t) {
if (s.length() != t.length()) {
return false;
}
sort(s.begin(), s.end());
sort(t.begin(), t.end());
return s == t;
}
};
方法一:两个unordered_map
class Solution {
public:
bool isAnagram(string s, string t) {
unordered_map<char,int> mp1,mp2;
for(auto &i:s){mp1[i]++;}
for(auto &j:t){mp2[j]++;}
if(mp1==mp2){return true;}
return false;
}
};
优化: 只用一个unordered_map
class Solution {
public:
bool isAnagram(string s, string t) {
unordered_map<char,int> mp1;
if(s.size()!=t.size()) return false;
for(auto &i:s){mp1[i]++;}
for(auto &j:t){
if(mp1[j]>0) mp1[j]--;
// if(mp1.find(j)!=mp1.end()){//在1里找2,对应消消乐
// mp1[j]--;
// if(mp1[j]==0){//消没了要erase,不然会是0
// mp1.erase(j);
// }
// }
else {return false;}
}
return true;
}
};
方法二:hash表巨快!
其实思路和上面的一个unordered_map是一样的,只是我是个unordered_map,他是个vector table(26, 0),数组不需要像map那样find
其实我们的也是hash法,unordered_map也是个hash表
class Solution {
public:
bool isAnagram(string s, string t) {
if (s.length() != t.length()) {
return false;
}
vector<int> table(26, 0);
for (auto& ch: s) {
table[ch - 'a']++;
}
for (auto& ch: t) {
table[ch - 'a']--;
if (table[ch - 'a'] < 0) {
return false;
}
}
return true;
}
};
【202. 快乐数】
方法一:set在哈希法中的应用
题目中说了会 无限循环,那么也就是说求和的过程中,sum会重复出现,这对解题很重要!
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。
class Solution {
public:
int getSum(int n){
int sum = 0;
while(n){
sum += (n%10)*(n%10);
n /= 10;
}
return sum;
}
bool isHappy(int n) {
int sum = getSum(n);
unordered_set<int> st;
while(1){
if(sum == 1){
return true;
}
if(st.find(sum)!=st.end()){// 如果这个sum曾经出现过,说明已经陷入了无限循环了,立刻return false
return false;
}
st.insert(sum);
sum = getSum(sum);
}
}
};
方法二:见到循环就快慢指针
使用 “快慢指针” 思想,找出循环:“快指针” 每次走两步,“慢指针” 每次走一步,当二者相等时,即为一个循环周期。此时,判断是不是因为 1 引起的循环,是的话就是快乐数,否则不是快乐数。
注意:此题不建议用集合记录每次的计算结果来判断是否进入循环,因为这个集合可能大到无法存储;另外,也不建议使用递归,同理,如果递归层次较深,会直接导致调用栈崩溃。不要因为这个题目给出的整数是 int 型而投机取巧。
class Solution {
public:
int getSum(int n){
int sum = 0;
while(n){
sum += (n%10)*(n%10);
n /= 10;
}
return sum;
}
bool isHappy(int n) {
int slow = n;
int fast = getSum(n);//这里就是fast的初始位置,n和getSum(n)都行,关键在下面的一次走两步
while(slow!=fast){//但如果你这里是while的话slow和fast就不能都是n了,如果是do while就无所谓
slow = getSum(slow);
fast = getSum(getSum(fast));
}
return slow == 1;
}
};
【451. 根据字符出现频率排序】
先哈希表存起来,再转vector排序,自行定义greater,注意这里的static
还是蛮多细节的
typedef pair<char, int> chi;//复杂的pair可以这样定义个简单名字
class Solution {
public:
//自行定义greater,注意这里的static
static bool greater(chi &a,chi &b){return a.second>b.second;}
string frequencySort(string s) {
unordered_map<char,int> mp;
string res;
for(auto &i:s){//先把字符串存进mp里记录出现次数
mp[i]++;//因为vec没有++运算,所以还是要有一个mp来记录
}
vector<chi> vec{mp.begin(),mp.end()};//因为mp不能排序,所以要用vec来存
sort(vec.begin(),vec.end(),greater);//排序
for(auto &i:vec){//这里是用来输出结果string的
for(int j = 0;j<i.second;j++){//得看i有几个,所以j<i.second
res += i.first;
}
}
return res;
}
};
1. key和value——搞清楚放的啥
感觉放啥都行,怎么方便怎么来 有根据str找vec的,也有根据dis找int的
【49. 字母异位词分组】
由于互为字母异位词的两个字符串包含的字母相同,因此对两个字符串分别进行排序之后得到的字符串一定是相同的,故可以将排序之后的字符串作为哈希表的键。值当然就是要返回的值啦。
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>> res;
unordered_map<string,vector<string>> mp;
for(auto &str:strs){
string key = str;//利用key来排序
sort(key.begin(),key.end());
mp[key].push_back(str);//同样的key对应的str肯定是异构词
}
for(auto &it:mp){//注意这里的.和->
res.push_back(it.second);
}
return res;
}
};
复杂度分析
时间复杂度:O(nklogk),n是strs的length,k是最大strs的length,对strs排序要klogk,有n个strs,所以是nklogk
空间复杂度:O(nk)需要用哈希表存储全部字符串。
【447. 回旋镖的数量】
class Solution {
public:
int distance(vector<int> &p1,vector<int> &p2){
return ( (p1[0]-p2[0])*(p1[0]-p2[0]) + (p1[1]-p2[1])*(p1[1]-p2[1]) );
}
int numberOfBoomerangs(vector<vector<int>>& points) {
int res=0,n = points.size();
if(n<3) return 0;
unordered_map<int,int> mp;//key:dis,value:每一个dis的个数,根据个数来算count
for(int i = 0;i<n;i++){
for(int j = 0;j<n;j++){//固定一个点i(枢纽点),另一个点j在动
if(j != i){mp[distance(points[i],points[j])]++;}//计算i 和 j之间的distance
}
for(auto &it:mp){
if(it.second>=2){res += (it.second)*(it.second-1);}//如果有两个dis相同就说明有回旋镖,
//回旋镖个数是 相同dis个数*相同dis个数-1[用An2排序法,所以是n*(n-1)]
}
mp.erase(mp.begin(),mp.end());//这里要clear,不然影响下一个i点的判断,
//当然也可以把mp的定义放进第一个for里,下一个循环时自动重新定义
}
return res;
}
};
复杂度分析
时间复杂度:O(n^2)
空间复杂度:O(n),因为后面把他erase掉了,当然也可以把mp的定义放进第一个for里,下一个循环时自动重新定义
【149. 直线上最多的点数】
方法一:朴素解法(枚举直线 + 枚举统计)
通过判断 i 和 j 与第三个点 k形成的两条直线斜率是否相等
class Solution {
public:
int maxPoints(vector<vector<int>>& points) {
int res = 0,count = 0,n = points.size();
if(n<3) return n;
for(int i = 0;i<n;i++){//固定一个点i,记录点i的个数same=1
int same = 1;
for(int j = i+1;j<n;j++){
if(j==i) same++;//记录第二个点j,和i相同就same++
else{
count++;//不同就count++
long long xDiff = (long long)(points[i][0] - points[j][0]);//Δx1
long long yDiff = (long long)(points[i][1] - points[j][1]);//Δy1
//Δy1/Δx1=Δy2/Δx2 => Δx1*Δy2=Δy1*Δx2,计算和直线ji在一条直线上的点
for(int k = j+1;k<n;k++){
if(xDiff *(points[i][1] - points[k][1]) == yDiff *(points[i][0] - points[k][0]))
{count++;}
}
}
res = max(res,same+count);
count = 0;//和之前erase一样,这里要clear,不影响下一次判断,值已经存在res里了
}
}
return res;
}
};
复杂度分析
时间复杂度:O(n^3)
空间复杂度:O(1)
方法二:优化(枚举直线 + 哈希表统计)
用哈希表的方式存储斜率,统计最多数目的的斜率
class Solution {
public:
int maxPoints(vector<vector<int>>& points) {
int res = 2,n = points.size();
if(n<3) return n;
for(int i = 0;i<n;i++){//固定一个点i
unordered_map<double,int> mp;//key:斜率,value:相同斜率的个数
for(int j = 0;j<n;j++){
if(j!=i){
long long dx = (long long)(points[i][0] - points[j][0]);//Δx1
long long dy = (long long)(points[i][1] - points[j][1]);//Δy1
double k = dy*1.0 / dx;//斜率
if(mp.count(k)){mp[k]++;}//斜率已经存在。就++
else {mp[k]=2;}//还未存在就初始值为2,因为后面返回点的个数
res = max(res,mp[k]);
}
}
}
return res;
}
};
2. 字符串——双映射
【205. 同构字符串】
【双射】
class Solution {
public:
bool isIsomorphic(string s, string t) {
unordered_map<char,char> mp1,mp2;
for(int i = 0;i < s.size();++i){
if(mp1[s[i]] && mp1[s[i]]!=t[i]) return false;//如果mp1[s[i]]存在就看是否对应t[i]
if(mp2[t[i]] && mp2[t[i]]!=s[i]) return false;
mp1[s[i]] = t[i];//不存在就先映射过去
mp2[t[i]] = s[i];
}
return true;
}
};
【290. 单词规律】——.split()实现的两种方法
【SplitString】、【双射】
c++可以用.substr 和 find()函数来实现.split()
还可以用 istringstream ss(s) 来实现
class Solution {
public:
void SplitString(const string &s,const string &c,vector<string> &v){
int l = 0,r = s.find(c);//r在第一个空格处
while(r<s.size()){
v.push_back(s.substr(l,r-l));
l = r+1;//l移到空格下一位
r = s.find(c,l);//从l位置开始找下一个空格
}
if(l!=s.size()){//别忘了最后一个单词
v.push_back(s.substr(l));
}
}
bool wordPattern(string pattern, string s) {//双射
unordered_map<char,string> c2s;
unordered_map<string,char> s2c;
vector<string> vec;//存储去除分隔符后的结果
//SplitString(s," ",vec);
string tmp;
istringstream ss(s);//从string对象s中读取字符。遇空格结束,天然的去空格小能手
while (ss >> tmp){//增加while循环,能将s全部单词打印出来
vec.push_back(tmp);
}
if(pattern.size()!=vec.size()) return false;
for(int i = 0;i<vec.size();i++){//注意要用.count
if(c2s.count(pattern[i]) && c2s[pattern[i]] != vec[i]) return false;
if(s2c.count(vec[i]) && s2c[vec[i]] != pattern[i]) return false;
c2s[pattern[i]] = vec[i];
s2c[vec[i]] = pattern[i];
}
return true;
}
};
3. 几数之和——要去重就排序+双指针
自己整理的看着最香:二三四数之和
【1.两数之和】
----暴力法
----hashmap
【15. 三数之和】
----哈希解法去重的过程不好处理,有很多小细节,如果在面试中很难想到位。
----排序+双指针
固定最左边的数,然后剩下部分双指针,结束while后稳步推进最左边的,注意j k要和旧的位置比
【18. 四数之和】
----四数之和与前面三数之和的思路几乎是一样的,外面多加一层循环就是了
【16. 最接近的三数之和】
----加个判断条件罢了
if (abs(sum - target) < abs(close - target)) {close = sum;}
if(sum==target){return target;}
【454. 四数相加 II】
----分组+hashmap
class Solution {
public:
int fourSumCount(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3, vector<int>& nums4) {
unordered_map<int,int> mp;
int res=0;
for(int i =0;i<nums1.size();++i){
for(int j =0;j<nums2.size();++j){
mp[nums1[i]+nums2[j]]++;
}
}
for(int i =0;i<nums3.size();++i){
for(int j =0;j<nums4.size();++j){
if(mp.find(0-nums3[i]-nums4[j])!=mp.end()){
res+=mp[0-nums3[i]-nums4[j]];
}
}
}
return res;
}
};
4. 滑动窗口+查找表
自己整理的看着最香:滑动窗口专栏















 1123
1123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









