







Linux深入理解内存管理3(基于Linux6.6)---TLB
一、前情回顾
分页机制的硬件原理, 从虚拟内存地址到物理内存地址的转换, 通过页表来处理。 为了节约页表的内存存储空间, 我们会使用多级页表。 但是, 多级页表虽然节约了存储空间, 但是却存在问题:原本对于只需要进行一次地址转换, 只需要访问一次内存就能找到对应的物理页号了,算出物理地址现在我们需要多次访问内存, 才能找到对应的物理页号。
最终带来了时间上的开销, 变成了一个“以时间换空间” 的策略, 极大的限制了内存访问性
能问题。 所以为了解决这种问题导致处理器性能下降的问题, 计算机工程师们专门在 CPU
里放了一块缓存芯片, 这块缓存芯片称之为 TLB, 全称是地址变换高速缓冲。
(Translation-Lookaside Buffer)
1.1、分页机制
分页机制将虚拟地址空间划分为多个固定大小的“页”(Page),物理地址空间也划分为相同大小的“页框”(Page Frame)。在程序运行时,虚拟内存地址通过页表来转换为物理内存地址。具体流程如下:
-
虚拟地址拆分:虚拟地址通常被拆分为两部分:
- 页号(Page Number):用来标识虚拟地址空间中的页。
- 页内偏移(Offset):用来标识页内的具体位置。
-
页表:页表存储了虚拟页与物理页框之间的映射关系。每一条页表项包含了一个虚拟页号和对应的物理页框号。
-
地址转换过程:
- 查找页表:通过虚拟地址中的页号,访问页表来查找该虚拟页号对应的物理页框号。
- 计算物理地址:通过物理页框号与虚拟地址中的偏移量,计算出最终的物理地址。
1.2、多级页表
为了节约内存空间,尤其是在地址空间较大的系统中,采用了 多级页表(Multilevel Paging)。在传统的单级页表中,页表的大小与虚拟内存空间成正比。而在多级页表中,页表本身的大小得到压缩。
- 多级页表的工作原理:
- 将虚拟地址拆分为多个部分,通常包括多个“页表索引”和一个“页内偏移”。
- 使用多个页表来逐级转换虚拟地址。
- 第一级页表将虚拟页号映射到一个二级页表的位置。
- 第二级页表将虚拟页号映射到物理页框。
通过这种方式,只有在访问到某一级页表时,才会分配相应的内存空间,从而减少了内存的浪费。
-
举例:假设虚拟地址是 32 位,分为:
- 10 位用于第一级页表(可以指向 1024 个二级页表)。
- 10 位用于第二级页表(每个二级页表指向 1024 个物理页框)。
- 剩下的 12 位用于页内偏移。
这样,虚拟地址中的前 10 位去查找第一级页表,接着再用接下来的 10 位查找二级页表,最后得到物理页框号。最后通过物理页框号和页内偏移量就能计算出物理地址。
1.3、多级页表带来的问题
尽管多级页表节省了内存空间,但它也引入了性能上的问题:
-
多次内存访问:每次进行地址转换时,需要依次访问多个级别的页表。每一次访问都需要访问内存,特别是在多级页表较深时,内存访问次数会显著增加,从而带来较大的时间开销。
- 例如:如果有 3 级页表,每次转换地址都需要访问三次内存:一次访问第一级页表,第二次访问第二级页表,第三次访问物理内存。这样就增加了每次内存访问的延迟。
-
时间开销:随着页表级数的增加,内存访问的延迟也随之增加,导致系统的性能下降。
1.4、TLB(Translation Lookaside Buffer)
为了解决多级页表带来的性能问题,CPU 引入了 TLB(Translation Lookaside Buffer),即地址转换高速缓存。
1.TLB 的工作原理
TLB 是一个高速缓存,它存储了最近使用的虚拟地址到物理地址的转换结果。通过将常见的页表项存储在 TLB 中,可以大大减少访问页表的次数,从而提高地址转换的效率。
- 访问流程:
- 当 CPU 发起虚拟地址访问时,首先检查 TLB 是否存在该虚拟地址的映射。
- 如果 TLB 中存在对应的条目(称为TLB命中),则直接使用缓存中的物理地址进行访问,节省了多次访问内存的时间。
- 如果 TLB 中没有找到对应的条目(称为TLB未命中),则需要访问页表进行地址转换,转换结果会被缓存到 TLB 中,供后续访问使用。
2.TLB 的作用
- 减少内存访问次数:通过缓存地址转换结果,减少了访问多级页表的次数。
- 提高系统性能:尤其在具有高访问局部性(局部性原理)的程序中,TLB 能显著提高性能,因为很多内存访问都会访问相同或相邻的地址。
3.TLB 的组织
TLB 通常采用类似于页表的结构,存储虚拟页号与物理页框号之间的映射关系。为了提高查找速度,TLB 通常使用 全相联映射 或 部分相联映射,以便能够更快地查找到映射条目。
- TLB 命中率:TLB 的效果与命中率密切相关,命中率越高,性能提升越显著。
- TLB 替换策略:当 TLB 满时,需要根据一定的替换算法(如 FIFO、LRU 等)选择一个条目进行替换。
二、TLB 介绍
TLB 是 Translation Lookaside Buffer 的简称, 可翻译为“地址转换后援缓冲器”, 也可简称为
“快表”。 简单地说, TLB 就是页表的 Cache, 属于 MMU 的一部分, 其中存储了当前最可能
被访问到的页表项, 其内容是部分页表项的一个副本。 处理器在取指或者执行访问 memory
指令的时候都需要进行地址翻译, 即把虚拟地址翻译成物理地址。 而地址翻译是一个漫长的
过程, 需要遍历几个 level 的 Translation table, 从而产生严重的开销。 为了提高性能, 我们
会在 MMU 中增加一个 TLB 的单元, 把地址翻译关系保存在这个高速缓存中, 从而省略了对
内存中页表的访问。
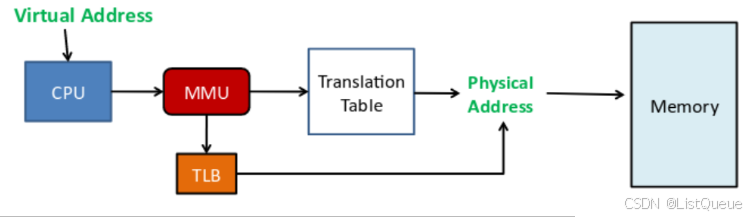
TLB 存放了之前已经进行过地址转换的查询结果。 这样, 当同样的虚拟地址需要进行地址转
换的时候, 可以直接在 TLB 里面查询结果, 而不需要多次访问内存来完成一次转换。
TLB 其实本质上也是一种 cache,既然是一种 cache,其目的就是为了提供更高的 performance。
而知道的指令 cache 和数据 cache 又又什么不同呢?
- 1.指令 cache: 解决 cpu 获取 main memory 中的指令数据的速度比较慢的问题而设立。
- 2.数据 cache: 解决 cpu 获取 main memory 中的数据的速度比较慢的问题而设立。
Cache 为了更快的访问 main memory 中的数据和指令, 而 TLB 是为了更快的进行地址翻译而
将部分的页表内容缓存到了 Translation lookasid buffer 中, 避免了从 main memory 访问页表
的过程。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5332
5332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









