







Linux中断上下文
中断概念
为了提高CPU和外围硬件(硬盘,键盘,鼠标等等)之间协同工作的性能,引入了中断的机制。没有中断的话,CPU和外围设备之间协同工作可能只有轮询这个方法:CPU定期检查硬件状态,需要处理时就处理,否则就跳过。当硬件忙碌的时候,CPU很可能会做许多无用功(每次轮询都是跳过不处理)。
中断机制是硬件在需要的时候向CPU发出信号,CPU暂时停止正在进行的工作,来处理硬件请求的一种机制。
中断类型
中断一般分为异步中断(一般由硬件引起)和同步中断(一般由处理器本身引起)。
**异步中断:**CPU处理中断的时间过长,所以先将硬件复位,使硬件可以继续自己的工作,然后在适当时候处理中断请求中耗时的部分。
**同步中断:**CPU处理完中断请求的所有工作后才反馈硬件。
中断相关函数
注册中断函数
/*
* 位置:<linux/interrupt.h> include/linux/interrupt.h
* irg - 表示要分配的中断号
* handler - 实际的中断处理程序
* flags - 标志位,表示此中断的具有特性
* name - 中断设备名称的ASCII 表示,这些会被/proc/irq和/proc/interrupts文件使用
* dev - 用于共享中断线,多个中断程序共享一个中断线时(共用一个中断号),依靠dev来区别各个中断程序
* 返回值:
* 执行成功:0
* 执行失败:非0
*/
int request_irq(unsigned int irq,
irq_handler_t handler,
unsigned long flags,
const char* name,
void *dev)释放中断函数
void free_irq(unsigned int irq, void *dev)如果不是共享中断线,则直接删除irq对应的中断线。
如果是共享中断线,则判断此中断处理程序是否中断线上的最后一个中断处理程序,
是最后一个中断处理程序 -> 删除中断线和中断处理程序
不是最后一个中断处理程序 -> 删除中断处理程序
中断处理程序
声明如下
/*
* 中断处理程序的声明
* @irp - 中断处理程序(即request_irq()中handler)关联的中断号
* @dev - 与 request_irq()中的dev一样,表示一个设备的结构体
* 返回值:
* irqreturn_t - 执行成功:IRQ_HANDLED 执行失败:IRQ_NONE
*/
static irqreturn_t intr_handler(int, irq, void *dev)中断处理机制
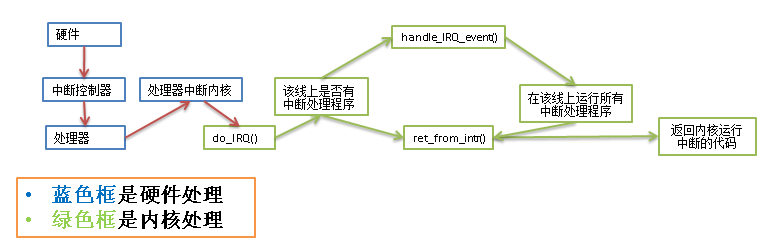
中断处理包含3个函数:
1. do_IRQ 与体系结构有关,对所接收的中断进行应答
2. handle_IRQ_event 调用中断线上所有中断处理
3. ret_from_intr 恢复寄存器,将内核恢复到中断前的状态
处理流程如图:
中断控制方法
常用的中断控制方法见下表
| 函数 | 说明 |
|---|---|
| local_irq_disable() | 禁止本地中断传递 |
| local_irq_enable() | 激活本地中断传递 |
| local_irq_save() | 保存本地中断传递的当前状态,然后禁止本地中断传递 |
| local_irq_restore() | 恢复本地中断传递到给定的状态 |
| disable_irq() | 禁止给定中断线,并确保该函数返回之前在该中断线上没有处理程序在运行 |
| disable_irq_nosync() | 禁止给定中断线 |
| enable_irq() | 激活给定中断线 |
| irqs_disabled() | 如果本地中断传递被禁止,则返回非0;否则返回0 |
| in_interrupt() | 如果在中断上下文中,则返回非0;如果在进程上下文中,则返回0 |
| in_irq() | 如果当前正在执行中断处理程序,则返回非0;否则返回0 |
中断下半部处理
那么对于一个中断,如何划分上下两部分呢?哪些处理放在上半部,哪些处理放在下半部?这里有一些经验可供借鉴:
1. 如果一个任务对时间十分敏感,将其放在上半部
2. 如果一个任务和硬件有关,将其放在上半部
3. 如果一个任务要保证不被其他中断打断,将其放在上半部
4. 其他所有任务,考虑放在下半部
实现中断下半部机制
软中断
软中断的代码在:kernel/softirq.c,流程如下:
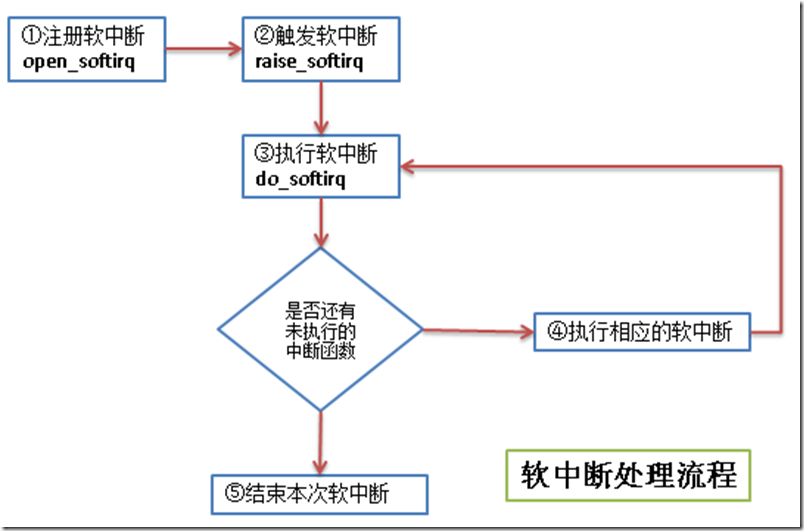
- 注册软中断的函数 open_softirq参见 kernel/softirq.c文件)
/*
* 将软中断类型和软中断处理函数加入到软中断序列中
* @nr - 软中断类型
* @(*action)(struct softirq_action *) - 软中断处理的函数指针
*/
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
/* softirq_vec是个struct softirq_action类型的数组 */
softirq_vec[nr].action = action;
}软中断类型目前有10个,其定义在 include/linux/interrupt.h 文件中:
enum
{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ,
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */
NR_SOFTIRQS
};struct softirq_action 的定义也在 include/linux/interrupt.h 文件中
/*
* 这个结构体的字段是个函数指针,字段名称是action
* 函数指针的返回指是void型
* 函数指针的参数是 struct softirq_action 的地址,其实就是指向 softirq_vec 中的某一项
* 如果 open_softirq 是这样调用的: open_softirq(NET_TX_SOFTIRQ, my_tx_action);
* 那么 my_tx_action 的参数就是 softirq_vec[NET_TX_SOFTIRQ]的地址
*/
struct softirq_action
{
void (*action)(struct softirq_action *);
};- 触发软中断的函数 raise_softirq 参见 kernel/softirq.c文件
/*
* 触发某个中断类型的软中断
* @nr - 被触发的中断类型
* 从函数中可以看出,在处理软中断前后有保存和恢复寄存器的操作
*/
void raise_softirq(unsigned int nr)
{
unsigned long flags;
local_irq_save(flags);
raise_softirq_irqoff(nr);
local_irq_restore(flags);
}- 执行软中断 do_softirq 参见 kernel/softirq.c文件
asmlinkage void do_softirq(void)
{
__u32 pending;
unsigned long flags;
/* 判断是否在中断处理中,如果正在中断处理,就直接返回 */
if (in_interrupt())
return;
/* 保存当前寄存器的值 */
local_irq_save(flags);
/* 取得当前已注册软中断的位图 */
pending = local_softirq_pending();
/* 循环处理所有已注册的软中断 */
if (pending)
__do_softirq();
/* 恢复寄存器的值到中断处理前 */
local_irq_restore(flags);
}- 执行相应的软中断 - 执行自己写的中断处理
linux中,执行软中断有专门的内核线程,每个处理器对应一个线程,名称ksoftirqd/n (n对应处理器号)
tasklet
tasklet也是利用软中断来实现的,但是它提供了比软中断更好用的接口(其实就是基于软中断又封装了一下),所以除了对性能要求特别高的情况,一般建议使用tasklet来实现自己的中断。tasklet对应的结构体在
struct tasklet_struct
{
struct tasklet_struct *next; /* 链表中的下一个tasklet */
unsigned long state; /* tasklet状态 */
atomic_t count; /* 引用计数器 */
void (*func)(unsigned long); /* tasklet处理函数 */
unsigned long data; /* tasklet处理函数的参数 */
};tasklet状态只有3种值:
1. 值 0 表示该tasklet没有被调度
2. 值 TASKLET_STATE_SCHED 表示该tasklet已经被调度
3. 值 TASKLET_STATE_RUN 表示该tasklet已经运行
引用计数器count 的值不为0,表示该tasklet被禁止。
tasklet使用流程如下:
- 声明tasklet (参见
/* 静态声明一个tasklet */
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
#define DECLARE_TASKLET_DISABLED(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }
/* 动态声明一个tasklet 传递一个tasklet_struct指针给初始化函数 */
extern void tasklet_init(struct tasklet_struct *t,
void (*func)(unsigned long), unsigned long data);- 编写处理程序
参照tasklet处理函数的原型来写自己的处理逻辑
void tasklet_handler(unsigned long date)- 调度tasklet
中断的上半部处理完后调度tasklet,在适当时候进行下半部的处理
tasklet_schedule(&my_tasklet) /* my_tasklet就是之前声明的tasklet_struct */工作队列
工作队列子系统是一个用于创建内核线程的接口,通过它可以创建一个工作者线程来专门处理中断的下半部工作。工作队列和tasklet不一样,不是基于软中断来实现的。缺省的工作者线程名称是 events/n (n对应处理器号)。
工作队列主要用到下面3个结构体,弄懂了这3个结构体的关系,也就知道工作队列的处理流程了。
/* 在 include/linux/workqueue.h 文件中定义 */
struct work_struct {
atomic_long_t data; /* 这个并不是处理函数的参数,而是表示此work是否pending等状态的flag */
#define WORK_STRUCT_PENDING 0 /* T if work item pending execution */
#define WORK_STRUCT_FLAG_MASK (3UL)
#define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK)
struct list_head entry; /* 中断下半部处理函数的链表 */
work_func_t func; /* 处理中断下半部工作的函数 */
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
/* 在 kernel/workqueue.c文件中定义
* 每个工作者线程对应一个 cpu_workqueue_struct ,其中包含要处理的工作的链表
* (即 work_struct 的链表,当此链表不空时,唤醒工作者线程来进行处理)
*/
/*
* The per-CPU workqueue (if single thread, we always use the first
* possible cpu).
*/
struct cpu_workqueue_struct {
spinlock_t lock; /* 锁保护这种结构 */
struct list_head worklist; /* 工作队列头节点 */
wait_queue_head_t more_work;
struct work_struct *current_work;
struct workqueue_struct *wq; /* 关联工作队列结构 */
struct task_struct *thread; /* 关联线程 */
} ____cacheline_aligned;
/* 也是在 kernel/workqueue.c 文件中定义的
* 每个 workqueue_struct 表示一种工作者类型,系统默认的就是 events 工作者类型
* 每个工作者类型一般对应n个工作者线程,n就是处理器的个数
*/
/*
* The externally visible workqueue abstraction is an array of
* per-CPU workqueues:
*/
struct workqueue_struct {
struct cpu_workqueue_struct *cpu_wq; /* 工作者线程 */
struct list_head list;
const char *name;
int singlethread;
int freezeable; /* Freeze threads during suspend */
int rt;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};使用工作队列的方法见下图:

- 创建推后执行的工作 - 有静态创建和动态创建2种方法
/* 静态创建一个work_struct
* @n - work_struct结构体,不用事先定义
* @f - 下半部处理函数
*/
#define DECLARE_WORK(n, f) \
struct work_struct n = __WORK_INITIALIZER(n, f)
/* 动态创建一个 work_struct
* @_work - 已经定义好的一个 work_struct
* @_func - 下半部处理函数
*/
#ifdef CONFIG_LOCKDEP
#define INIT_WORK(_work, _func) \
do { \
static struct lock_class_key __key; \
\
(_work)->data = (atomic_long_t) WORK_DATA_INIT(); \
lockdep_init_map(&(_work)->lockdep_map, #_work, &__key, 0);\
INIT_LIST_HEAD(&(_work)->entry); \
PREPARE_WORK((_work), (_func)); \
} while (0)
#else
#define INIT_WORK(_work, _func) \
do { \
(_work)->data = (atomic_long_t) WORK_DATA_INIT(); \
INIT_LIST_HEAD(&(_work)->entry); \
PREPARE_WORK((_work), (_func)); \
} while (0)
#endif工作队列处理函数的原型:
typedef void (*work_func_t)(struct work_struct *work);- 刷新现有的工作,这个步骤不是必须的,可以直接从第①步直接进入第③步, 刷新现有工作的意思就是在追加新的工作之前,保证队列中的已有工作已经执行完了。
/* 刷新系统默认的队列,即 events 队列 */
void flush_scheduled_work(void);
/* 刷新用户自定义的队列
* @wq - 用户自定义的队列
*/
void flush_workqueue(struct workqueue_struct *wq);- 调度工作 - 调度新定义的工作,使之处于等待处理器执行的状态
/* 调度第一步中新定义的工作,在系统默认的工作者线程中执行此工作
* @work - 第一步中定义的工作
*/
schedule_work(struct work_struct *work);
/* 调度第一步中新定义的工作,在系统默认的工作者线程中执行此工作
* @work - 第一步中定义的工作
* @delay - 延迟的时钟节拍
*/
int schedule_delayed_work(struct delayed_work *work, unsigned long delay);
/* 调度第一步中新定义的工作,在用户自定义的工作者线程中执行此工作
* @wq - 用户自定义的工作队列类型
* @work - 第一步中定义的工作
*/
int queue_work(struct workqueue_struct *wq, struct work_struct *work);
/* 调度第一步中新定义的工作,在用户自定义的工作者线程中执行此工作
* @wq - 用户自定义的工作队列类型
* @work - 第一步中定义的工作
* @delay - 延迟的时钟节拍
*/
int queue_delayed_work(struct workqueue_struct *wq,
struct delayed_work *work, unsigned long delay);中断下半部总结
| 下半部机制 | 上下文 | 复杂度 | 执行能力 | 顺序执行保障 |
|---|---|---|---|---|
| 软中断 | 中断 | 高(需要自己确保软中断的执行顺序及锁机制) | 好(全部自己实现,便于调优) | 没有 |
| tasklet | 中断 | 中(提供了简单的接口来使用软中断) | 中 | 同类型不能同时执行 |
| 工作队列 | 进程 | 低(在进程上下文中运行,与写用户程序差不多) | 差 | 没有(和进程上下文一样被调度) |















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









