







一种准确预测核糖核酸假尿苷位点的新方法
期刊:Briefings in Bioinformatics
链接:https://doi.org/10.1093/bib/bbab245
背景:
假尿苷是一种普遍存在于真核生物与原核生物中的核糖核苷酸修饰类型,在各种生物过程中起着至关重要的作用。几乎所用种类的核糖核酸都受到这种修饰,因此研究该位点极为重要。
结果:
作者提出了一种新的计算方法,该方法能够准确识别假尿苷位点。该方法基于对18种常用特征编码方式进行综合评估,最后采用其中4种特征作为本次模型的数据特征提取。
数据集
a):数据分为3个物种,分别为H.sapiens、S.cerevisiae、M.musculus。
b):其中H.sapiens是长度为21的RNA序列,且训练集样本数为990,独立验证集样本数为200。
c):S.cerevisiae是长度为31的RNA序列,训练集样本数为628,独立验证集样本数为200。
d):M.musculus没有独立验证集,只有训练集,其样本数为944。
为了进一步评估模型的性能,并将其与其他最先进的方法进行比较,作者从m6A-Atlas数据库中收集了另一个独立测试集数据库。该数据库包含:3137 H.sapiens,2702 M.musculus以及 733 S.cerevisiae。
方法
1:
对数据进行18种特种编码方式进行特征提取,并结合9种常用的机器学习算法对每种特征进行评估。
2:
通过基础分类齐的不同组合构建一系列堆叠集成学习模型,并伟三个物种种的每个模型进行优化。
3:
对现有的几张最先进的方法进行交叉验证和独立测试来全面评估优化堆叠模型。
4:网络服务器。

特征提取
作者采用了18种特征编码方式,并测试了其组合方案,其中包括:二元特征、自相关、互协方差、基于三核苷酸的自协方差、累计核苷酸频率等。。。
当然这些特征的提取都可采用开源iLearn和iLearnPlus软件包来计算:链接。
1:Binary feature
即onehot特征编码
2:Pseudo k-tuple composition (PseKNC)
3:Nucleotide chemical property
根据核苷酸有不同的化学结构和化学性质。根据其化学性质,四个核苷酸可以聚集成三个不同的组。

因此可编码为:A(1,1,1), C(0,1,0) , G (1,0,0), U(0,0,1) 。
4:Position-specific trinucleotide propensity based on single strand。
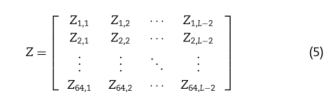
其中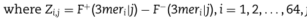
即先计算出该矩阵中的Z,Z为不同的k元组在序列各个位置的频率所构建得来。F+,F-代表着训练集中正负样本。
构建完成后,要编码的序列,则可为一下公式:
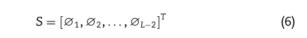
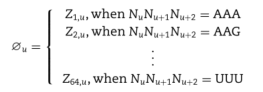















 4379
4379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









