






Title:Adapt-Kcr: a novel deep learning framework for accurate prediction of lysine crotonylation sites based on learning embedding features and attention architecture
期刊:Briefings in Bioinformatics
发表时间:2022年01月09日
作者:南京农业大学理学院:陈媛媛和丛平
代码数据集:GitHub - Marscolono/Adapt-Kcr
一、摘要
(Kcr)是一种重要的翻译后修饰类型,与广泛的生物过程相关。识别Kcr位点对更好地理解其功能机制至关重要。然而,现有的检测Kcr位点的实验技术成本低,需要新的计算方法来解决这个问题。本文介绍了一种先进的深度学习模型Adapt-Kcr,该模型利用自适应嵌入(embedding),基于卷积神经网络(CNN)以及双向长-短期记忆网络(BLSTM)和注意力(Attention)。在独立测试集(independent testing)上,Adapt-Kcr的表现优于目前最先进的Kcr预测模型,准确率(ACC)提高了3.2%,AUC特征曲线下的面积提高了1.9%。与其他Kcr模型相比,Adapt-Kcr还具有更强的区分crotonylation和其他赖氨酸修饰的能力。另一个模型(AdaptST)被训练用于预测SARS-CoV-2的磷酸化位点,并优于同等先进的磷酸化位点预测模型。这些结果表明,自适应嵌入特征(self-adaptive embedding)在捕获鉴别信息方面优于其他特征;在注意力结构中,这可能是一种识别蛋白质Kcr位点的有效方法。总之,Adap这个框架在预测其他蛋白质翻译后修饰位点方面具有很强的潜力。
二、方法与数据集
Benchmark dataset(基准数据集):3个基准数据集
Kcr数据集:9964个Kcr位点和9964个非Kcr位点(划分比例训练集比测试集7:3)
PLMD数据集:2989个Kcr位点和4041个非Kcr位点,其中Kgly2556,Kace1485
A549细胞数据集:S/T位点阳性样本5387份,阴性样本5387份(划分比例训练集比测试集8:2)
长度:31
方法:
自适应嵌入模型
在自适应嵌入模块中,我们关注每个蛋白序列中20个氨基酸类型的标记向量信息和位置信息。首先,我们使用查找表和字母在整个序列中的位置,将20个氨基酸中的每个氨基酸映射到一个向量上。在训练模型时,每个融合向量可以根据反向传播任务自适应调整。嵌入的描述如下: Embedding的主要作用是将稀疏向量转换成稠密向量,便于上层深度神经网络处理。

CNNs长短期记忆网络与注意机制
CNN学习效率高,被广泛应用于图像处理、语言识别、图像语义分割等领域。cnn包含一组可学习的滤波器,每个滤波器都与该层的输入卷积,以编码一个小的接收域的本地知识。为了成功捕获图像中的空间和时间依赖性,CNN块通常由三部分组成:卷积层、池化层和全连接(FC)层。在图像领域,卷积层通过多重特征映射,可以提取边缘、颜色、梯度方向等高级特征。池化层通常用于压缩特征映射的分辨率,提取旋转不变量和位置不变量的主导特征,降低计算成本。CNN在序列分析,如自然语言处理方面的能力较低,因为它不考虑输入之间的依赖性。RNN可以克服这一缺点,但由于梯度消失和梯度爆炸的问题,RNN的训练非常困难,应用受到限制。LSTMs是一种特殊类型的RNN,用于求解梯度爆炸和消失问题。LSTMs极大地改善了早期RNN的结构,拓宽了RNN的应用范围,为后续序列建模的发展奠定了基础。LSTM层由一组重复连接的块组成,这些块包含一个或多个重复连接的存储单元和增殖单元。在LSTM中,一种存储机制取代了传统RNN中使用的隐藏函数,该隐藏函数由一组反复连接的块组成。循环连接记忆单元和增殖单元增强了LSTM的长距离依赖学习能力。与单向LSTM相比,BLSTM能更好地捕捉序列上下文信息。除了BLSTM体系结构,注意力机制也可以用于捕获位置信息。它最初被提出用于解决机器翻译任务,并已被证明能够区分更多和更不重要的信息。在自然语言处理和图像识别领域,近年来越来越多的研究探索了高级深度学习技术的应用,如注意机制,以提高模型的可解释性。注意机制经常与RNN结合在生物信息学中使用,并已被证明在广泛的生物序列分析问题中取得了具有竞争力的表现。因此,本研究利用它来识别影响(Kcr)预测的关键信息。
Adapt-Kcr模型
为了充分捕捉蛋白质序列中的信息,该文使用了深度学习网络Adapt-Kcr。该网络具有自适应嵌入模块,根据氨基酸标记和位置信息嵌入蛋白质序列数据,然后利用梯度不断更新嵌入值。Adapt-Kcr还包括一个CNN层提取序列中的高级特征,一个BLSTM层学习序列中的依赖结构,一个注意机制层识别输入数据中的关键信息,以及一个FC层。卷积层在CNN中配置了256个滤波器,每个滤波器的大小设置为10。在CNN层中使用ReLU (corrected linear activation unit)作为激活函数如下:
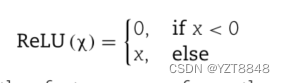
卷积层用于捕捉每个序列下的更高级别特征。为了减少特征冗余,防止过拟合,在卷积层之后增加了一个带Max pooling的pooling层。在CNN之后加入一个隐藏单元大小为32的BLSTM层来学习序列中的依赖结构。然后,在BLSTM之后添加一个隐藏大小为10的注意层,识别特征矩阵中的关键信息。
在Adapt-Kcr训练过程中使用Adam、Batch归一化和dropout来加速训练,避免过拟合。在训练模型时,dropout rate, learning rate和reduced factor分别设置为0.5,0.001和0.5。最大训练历元为50,批大小设为256。在训练过程中采用了早期停止策略,即当预测性能没有提高到验证集的水平时停止训练;耐心设置为20。该模型的整个框架在Pytorch (https://pytorch.org)中实现。
流程图:
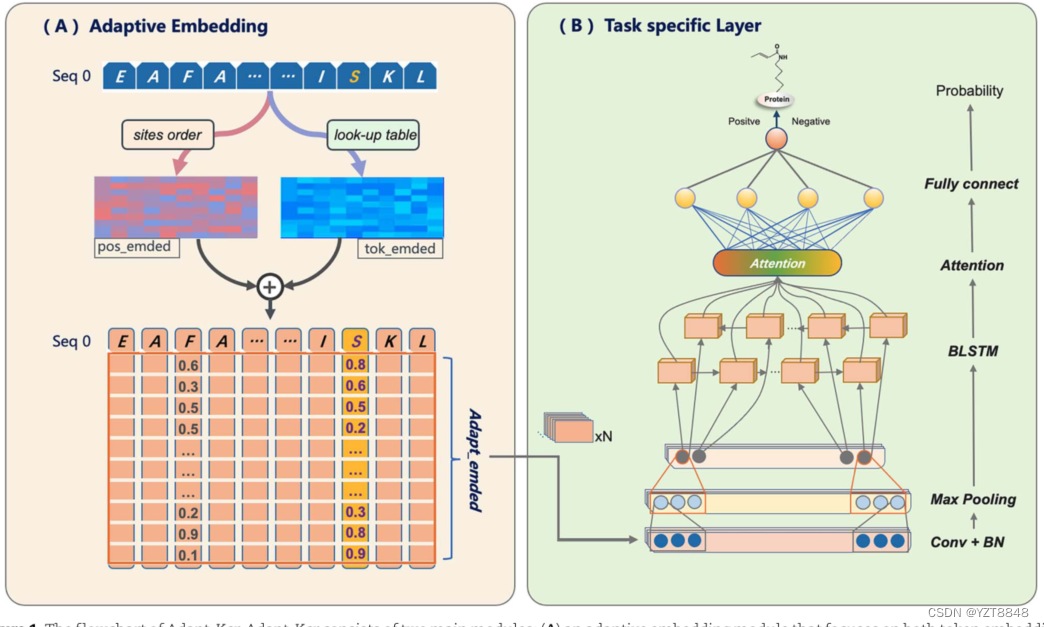
Adapt-Kcr流程图。Adapt-Kcr由两个主要模块组成:(A)一个自适应嵌入模块,它关注pos嵌入和位置嵌入,并通过反向传播进行调整;(B)一个特定于任务的层,它由CNN、BLSTM、attention和针对特定类别的响应概率分布的全连接层组成。
三、结果
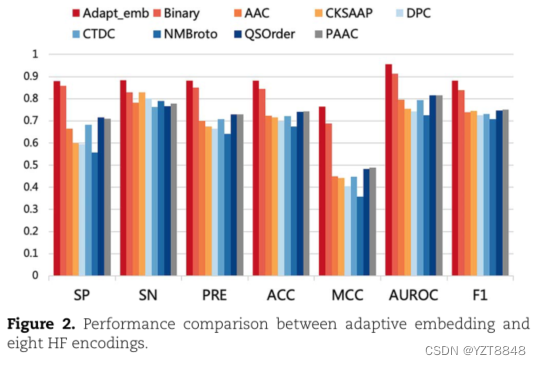
特征提取比较结果:
文章评估并比较了由8种不同的蛋白质嵌入方法和由基本CNN架构使用的自适应嵌入方法生成的特征训练的模型的预测性能。卷积层在CNN中配置了256个滤波器,每个滤波器的大小设置为10。在CNN层使用ReLU作为激活函数。最后,使用一个有32个隐藏单元的FC层,输出大小为2。根据iLearnPlus测试的8种常用高频编码分别为氨基酸组成(AAC)、二进制、CKSAAP、Kmer二肽组成(DPC)、组成(CTDC)、归一化moreau-broto (NMBroto)、准序列序描述符(QSOrder)和伪氨基酸组成(PAAC)。在8种高频嵌入方法中,二进制表现较好(图2)。但自适应嵌入在所有评价指标中排名第一;ACC、MCC、AUROC、F1、SPE和SEN的值分别比二值模型高3.84%、7.6%、4.3%、4.4%、2.1%和5.6%。我们将分类模块中倒数第二神经网络的输出维数设为2,在平面上绘制出二维输出特征向量(图3)。自适应嵌入模型的正样本和负样本明显分离,二值模型的性能次之,其他模型混合。这可能是因为自适应嵌入方法能够通过将截断的蛋白质从高维空间映射到低维空间来捕获隐藏在蛋白质序列中的信息。因此,我们发现自适应学习特征在预测(赖氨酸tonylation)方面比HF这些制作的特征更有效。
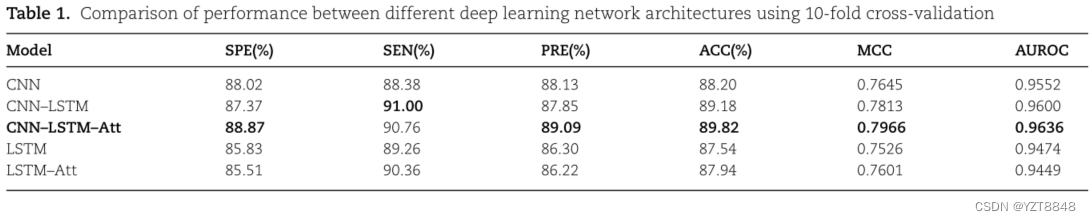
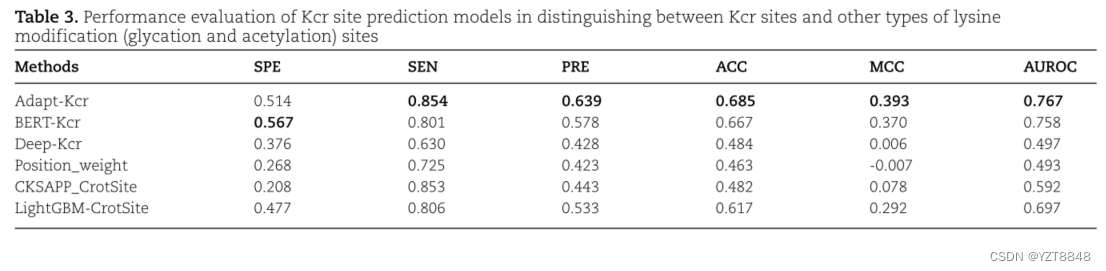
模型比较结果

四、结论
在本研究中,该文构建了一个端到端深度学习模型Adapt-Kcr,该模型集成了多种深度学习方法来有效地预测Kcr站点。Adapt-Kcr采用自适应嵌入层来描述蛋白质序列信息,然后使用CNN层来提取局部的蛋白质序列特征,然后使用BLSTM层来捕获Kcr位点的上下文依赖信息。Adapt-Kcr还使用一种注意力机制来选择对预测Kcr场址最关键的信息,然后通过FC层对每个场址做出最终决定。实验结果表明,该模型在基准数据集上的大部分指标性能优于现有模型,具有较高的ACC和鲁棒性。重要的是,我们发现,与现有方法相比,这种具有自适应嵌入特征的深度学习架构也可以用于更好地预测其他PTM数据,如丝氨酸和苏氨酸磷酸化位点。该框架对PTM预测任务具有良好的可扩展性和应用潜力。需要注意的是,本研究存在一些局限性。模型在非平衡数据上的性能略低于在平衡数据上的性能,这是生物信息学数据工程和模型架构设计需要解决的问题。由于计算时间相对较复杂,Adapt-Kcr的框架和参数设计只能实现局部最优。此外,蛋白质序列的长度可能会限制模型的性能;从理论上讲,较长的序列可以提供更多的信息。然而,以往关于Kcr位点识别的研究都是基于长度为31nt的序列,我们未来的工作将结合更长的序列信息,旨在构建一个有效的机器学习框架,用于更多的单类PTM预测或多标签预测任务。

















 1454
1454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









