







一、 垃圾回收机制详解
垃圾回收机制(简称GC),专门回收不可用的变量值所占用的内存空间
了解:
- 栈区:变量名与值内存地址的关联关系存放于栈区
- 堆区:变量值存放于堆区,内存管理回收的则是堆区的内容
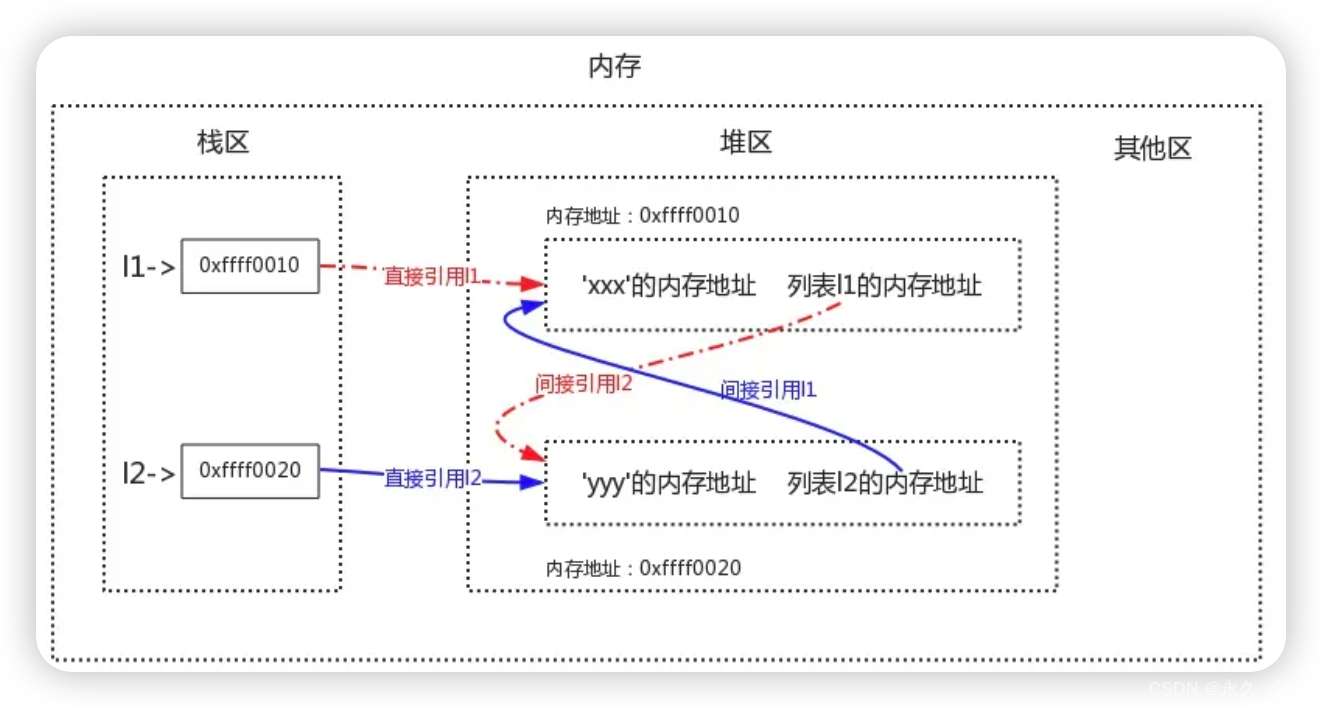
- 列表的底层原理:列表指向的是一块内存地址, 内存中存储的是列表的所引和值的内存地址。

垃圾回收的几种方法: - 引用计数(reference counting):
# 每饮用一次就会标记加一,如果引用计数为0则回收这块内存
x = 10 # 直接引用
l = ['a', x] # 间接引用
但是当我循环引用的时候
循环引用会导致:值不再被任何名字关联,但是值的引用计数并不会为0,那就用到了标记清楚
-
标记清除(mark and sweep)
- 直接引用被清除, 但是间接引用还在, 导致内存泄漏。
- 标记/清除算法的做法是当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后进行两项工作,第一项则是标记,第二项则是清除
- 原理:
- 先扫描栈区顺着栈区的线寻找只要被引用就会标记保留
- 清除的过程将遍历堆中所有的对象,将没有标记存活的对象全部清除掉
-
分代回收(generation collection)
-
背景:
- 基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍,这是非常消耗时间的,于是引入了分代回收来提高回收效率,分代回收采用的是用“空间换时间”的策略。
-
分代:
- 分代指的是根据存活时间来为变量划分不同等级
- 新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,那么该对象的权重加一,当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代
- 青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,
- 接下来,青春代中的对象,也会以同样的方式被移动到老年代中。也就是等级(代)越高,被垃圾回收机制扫描的频率越低
-
回收:
- 回收依然是使用引用计数作为回收的依据
-
虽然分代回收可以起到提升效率的效果,但也存在一定的缺点:
- 例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了,该变量应该被回收,但青春代的扫描频率低于新生代,所以该变量的回收就会被延迟。
-
二、 与用户交互
2.1 接收用户的输入
- input:会将用户输入的所有内容都存成字符串类型
2.2 格式化输出
- print()
- % :s:字符串,d:整形 最慢
# 按照位置与%对应, 按照位置一一对应
"my name is %s my age is %s"%("zpp", "18")
# 以字典的形式传值, 打破位置的限制
"my name is %(name)s my age is %(age)s"%{"name":"zpp", "age":"18"}
- .format :2.7以后都兼容, 次之(整体优先使用)
"my name is {} my age is {}".format("zpp", "18")
"my name is {0}{0}{0} my age is {1}{1}".format("zpp", "18")
"my name is {name} my age is {age}"%{"name":"zpp", "age":"18"}
- f :3.5以后才有, 最快
x = input()
y = input()
res = f'my name is {x} my age is {y}'
相关连接(笔记来自于视频课程和知乎的归类整理):
[1]: https://www.bilibili.com/video/BV1QE41147hU?p=17
[2]: https://zhuanlan.zhihu.com/p/108683483
[3]: https://zhuanlan.zhihu.com/p/108684774















 935
935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









