









前言
运维经常需要通过网络层抓包来诊断排查问题,可以说是运维必备技能之一。熟练使用wireshark来trouble shooting需要对各种网络协议都要有比较深的认识。本文对日常用到的一些技能技巧进行总结,方便各位看官入门,然后深入。
命令介绍
1.tcpdump
就是:dump the traffic on a network。根据命令选项对网络上的数据包进行截获、分析的工具。支持通过网络、协议、主机、端口的过滤,并提供and、or、not等逻辑操作。日常中更多的是通过该命令进行抓包,然后使用本文提到的wireshark进行分析。
#语法:
Usage: tcpdump [-aAdDefhIJKlLnNOpqRStuUvxX] [ -B size ] [ -c count ]
[ -C file_size ] [ -E algo:secret ] [ -F file ] [ -G seconds ]
[ -i interface ] [ -j tstamptype ] [ -M secret ]
[ -Q|-P in|out|inout ]
[ -r file ] [ -s snaplen ] [ -T type ] [ -w file ]
[ -W filecount ] [ -y datalinktype ] [ -z command ]
[ -Z user ] [ expression ]
一些常用的选项:
- -v:产生详细的输出. 比如包的TTL,id标识,数据包长度,以及IP包的一些选项。同时它还会打开一些附加的包完整性检测,比如对IP或ICMP包头部的校验和。
- -vv:产生比-v更详细的输出. 比如NFS回应包中的附加域将会被打印, SMB数据包也会被完全解码。
- -vvv:产生比-vv更详细的输出。比如 telent 时所使用的SB, SE 选项将会被打印, 如果telnet同时使用的是图形界面,其相应的图形选项将会以16进制的方式打印出来
- -w file:将原始数据包输出到指定file的文件中。可以使用-r读取。
- -c count: 抓取指定数量的包后退出。
- -C file_size:单位是1,000,000字节,约等于1M(如果按1M=1024KB)。将数据包写到文件前先检查文件大小是否超过file_size。如果是,则写入下一个文件。
- -W count: 常与-C联合使用,实现循环写入count个文件。
- -i interface: 要抓包的网卡,使用ip a可以查看网卡列表。
tcpdump的参数非常多,而且跟Linux“主命令+主参数+参数值”的模式不太类似。
主要语法如下:
tcpdump options protocol directiono type
注释:
1.options: tcpdump -h回显的那些参数;
2.protocol:可根据协议过滤,支持的关键字有:ip, ip6, arp, rarp, atalk, aarp, decnet, sca, lat, mopdl, moprc, iso, stp, ipx, or netbeui
3.direction:根据数据流向过滤,支持的关键有:src、dst、src or dst
4.type:可识别的关键有host、port、net、portrange
实例:
#针对网卡eth0抓包,-C表示300M每个文件,-W表示保留4个文件循环覆盖,-w表示将抓取的数据包保存到指定路径的文件中
tcpdump -i eth0 -w /tmp/`hostname -i`.pcap -C 300 -W 4 -vvv
#根据网卡eth0和源IP地址进行过滤
tcpdump -i eth0 src host 10.10.10.10 and port 8080
#根据网段进行过滤
tcpdump net 192.168.10.0/24
#根据端口范围进行过滤
tcpdump portrange 8000-8080
2.wireshark
wireshark是一款免费开源网络包分析工具,能实现按要求捕获指定的数据包并借助强大的过滤器实现数据包分析。常用于网络问题诊断和问题分析。
2.1 wireshark抓包
功能类似于Linux 命令的tcpdump,通过“捕获”–“捕获过滤器”按条件捕获数据包。也可以通过“选项”设置捕获过滤器。因为Linux是我的主要运维方向,Windows没有遇到过很多场景需要抓取本机的流量进行分析。
2.2wireshark分析
一般从linux tcpdump获取的文件传到windows机器上(tcpdump -r跟wireshark比起来有点弱了),再通过wireshark来分析。
wireshark的工具使用很简单,难的是它的过滤器,要弄懂过滤器就不可避免要熟悉网络协议、tcp/ip七层网络模型。而这些不是一蹴而就的,得持续学习,持续精近,我还在这条路上努力着。 毫不夸张的说学习wireshark,就是学习网络协议、学习它的过滤器。
wireshark过滤器分为“捕获过滤器(capturing filter)” 和 “展示过滤器(displaying filter)”。功能不用过多解释,捕获过滤器是抓包时用的。展示过滤器则是查看(分析)数据包时用的,能按基于以下展示特定的数据包:
- 网络协议
- 字段
- 字段值
- 字段模糊值
- ……
注意:展示过滤器只是影响的数据包的展示,数据包实际都还在捕获的文件中。
下面重点介绍下展示过滤器的一些常用用法。
过滤器一般语法:
协议[.字段1[.字段2]] 比较符 ‘值’ [逻辑运算符 协议[.字段1[.字段2]] 比较符 ‘值’]
如:
http.request.method == GET
http and http.response.code == 400
比较运算符:
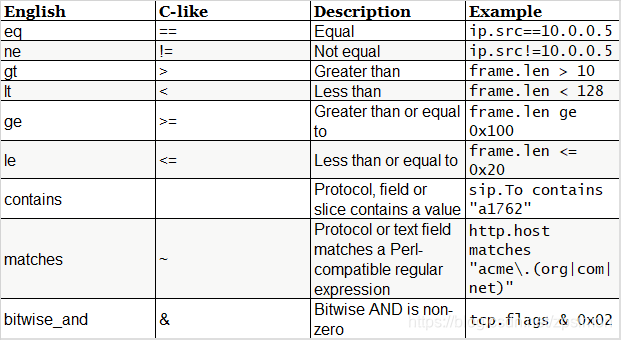
逻辑运算符:

实例:
#筛选响应码为400的报文
http.response.code == 400
#过滤请求uri中报错“/non-std/exp/pdd/service” 字符串的数据包
http.request.uri contains "/non-std/exp/pdd/service"
2.3遇到的问题
1.pcap: File has *******-byte packet, bigger than maximum of ******)
使用wireshark打开.pcap文件时,报如题错误.
editcap: The file “10.10.10.10_0.pcap” appears to be damaged or corrupt.
(pcap: File has 3932161-byte packet, bigger than maximum of 262144)
原因:是*.pcap文件中有过大的数据包,超过了wireshark的最大大小。
解决办法:从linux通过ftp传到Windows时,使用binary模式,可以解决这个问题。
ftp> binary
200 Switching to Binary mode.
ftp> get 10.10.10.10_0.pcap
网上还有另外一种解决方案,如下(我没有尝试过,可以参考下)
#将10.119.2.63_0.pcap 这个包改成按每10000个数据包切断。生成多个文件。
"D:\Program Files\Wireshark\editcap.exe" -c 10000 10.119.2.63_0.pcap first10000.pcap
2.4 一些小技巧
1)当不知道怎么写过滤器语法时,怎么办?
A:打开capture file,随便找一个类似的请求,点击数据包,右键–“作为过滤器”。然后修改过滤器即可。
2)一些常用的过滤器怎么保存下来?
A:“分析”–“Display Filters”,增加,然后保存即可。下次有类似与需求时可以稍微修改一下即可

3)如何将分析结果分享给其他人?
A:将已经过滤的数据,Ctrl+A全选,“文件”–“导出特定分组”,在对话框中勾选“Selected packet”点击保存,即可将关键信息保存成文件。

















 3350
3350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









