







Hadoop将一个作业分解后的任务分成计算型任务和辅助型任务. 计算型任务是实际处理数据的任务, 包括Map和Reduce任务, 由专门的任务调度器TaskScheduler对它们进行调度(分配任务). 辅助型任务通常不会处理实际的数据, 而是用于同步计算型任务和清理磁盘上无用的目录. 包括job-setup task, job-cleanup task, task-cleanup task. 其中job-setup-cleanup用于计算型任务开始运行同步标识和结束运行同步标识. 即初始化作业时的setup和cleanup TIP.
task-cleanup task用于清理失败的计算型任务已经写到磁盘上的部分结果.
public enum TaskType { /** Enum for map, reduce, job-setup, job-cleanup, task-cleanup task types. */
MAP, REDUCE, JOB_SETUP, JOB_CLEANUP, TASK_CLEANUP
}一个正常的TaskTracker还有空闲的slot, 即acceptNewTasks=true, 则JobTracker会为TaskTracker分配新任务, 任务的选择顺序是:
优先辅助型任务,然后计算型任务: job-cleanup > task-cleanup > job-setup > map task > reduce task
// All the known jobs. (jobid->JobInProgress) 当MR客户端提交作业调用到JT.addJob时, 先放入jobs中, 然后加入监听器的队列中
Map<JobID, JobInProgress> jobs = Collections.synchronizedMap(new TreeMap<JobID, JobInProgress>());
// returns cleanup tasks first, then setup tasks.
synchronized List<Task> getSetupAndCleanupTasks(TaskTrackerStatus taskTracker) throws IOException {
if (isInSafeMode()) return null; // Don't assign *any* new task in safemode
int maxMapTasks = taskTracker.getMaxMapSlots(); // 可以运行的Map的最大数量
int maxReduceTasks = taskTracker.getMaxReduceSlots();
int numMaps = taskTracker.countOccupiedMapSlots(); // 正在运行的Map数量
int numReduces = taskTracker.countOccupiedReduceSlots();
int numTaskTrackers = getClusterStatus().getTaskTrackers();
int numUniqueHosts = getNumberOfUniqueHosts();
Task t = null;
synchronized (jobs) { // addJob时, 将新提交的作业加入到jobs中
if (numMaps < maxMapTasks) { // 只要还有剩余的槽, 就优先选择辅助型任务, 选择顺序依次: job-cleanup > task-cleanup > job-setup
for (Iterator<JobInProgress> it = jobs.values().iterator(); it.hasNext();) {
JobInProgress job = it.next();
t = job.obtainJobCleanupTask(taskTracker, numTaskTrackers, numUniqueHosts, true); // job-cleanup task
if (t != null) { return Collections.singletonList(t); } // 一次只返回一个任务
}
for (Iterator<JobInProgress> it = jobs.values().iterator(); it.hasNext();) {
JobInProgress job = it.next();
t = job.obtainTaskCleanupTask(taskTracker, true); // task-cleanup task
if (t != null) { return Collections.singletonList(t); }
}
for (Iterator<JobInProgress> it = jobs.values().iterator(); it.hasNext();) {
JobInProgress job = it.next();
t = job.obtainJobSetupTask(taskTracker, numTaskTrackers, numUniqueHosts, true); // job-setup task
if (t != null) { return Collections.singletonList(t); }
}
}
if (numReduces < maxReduceTasks) {// map优先于reduce
// 类似于上面Map的处理, 只不过调用JIP的相应方法时, 最后一个参数为false表示不是map而是reduce任务
}
}
return null;
}任务选择顺序解析
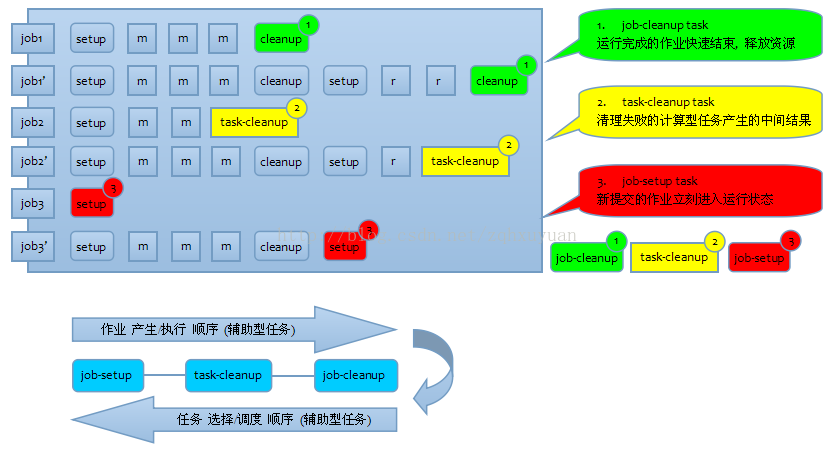
作业的运行顺序是: job-setup > map > reduce > job-cleanup. 而任务选择的顺序为什么是: job-cleanup > task-setup > job-setup > map > reduce?
目的: 这样可以让`运行完成的作业快速结束, 新提交的作业立刻进入运行状态`.
问题: 根据作业的执行顺序, job-cleanup task一定是在job-setup task执行之后才会执行的. 即job-setup没有执行完, job-cleanup task显然不能执行.
那么为什么选择任务时job-cleanup task可以优先于job-setup?
场景: 作业队列jobs保存了所有未完成的作业, TT上可以同时运行多个作业.
job1执行到了job-cleanup [作业1即将完成了]
job2正执行到map, 由于执行map/reduce的时候会产生TaskAttempt, 会有些失败的任务或者TA完成, 其他的TA失效即job2有task-cleanup.
job3才刚刚开始job-setup [作业3刚刚要开始]
那么当这个TT向JT请求新任务时, 如何选择TT上的任务TaskInProgress. (注: job-cleanup, job-setup, task-cleanup都属于TaskInProgress.)
分析:
I. 优先选择job-cleanup task
我们知道作业运行过程中分为map和reduce, 任务在TT上运行需要占用槽位slot.
当作业开始时, 作业会占用TT一定数量的槽位以满足作业的运行, 当作业完成时, 就会释放槽位.
因此优先执行job-cleanup task, 不仅可以让该作业快速完成, 还可以释放作业占用的槽位, 以满足TT上其他等待槽位的作业的运行.
II. 选择task-cleanup task
Map或Reduce任务运行过程中, 会有多个TaskAttempt执行相同的Task. 有些TaskAttempt会执行成功, 有些则会失败.
对于失败的TaskAttempt产生的临时文件, 需要及时清理掉.
III. 选择job-setup task
如果都没有job-cleanup task和task-cleanup task, 现在才开始选择job-setup task. 选择此类型任务后, 任务就可以开始正式运行
注意: getSetupAndCleanupTasks按照优先级只要成功获取到上述任何一种类型的任务, 就不会往下继续寻找了.
也许你会问: job-setup还没有执行, job-cleanup不应该执行啊, 即使你获取到了, 你也不可能先执行job-cleanup吧, 这个明显违反了作业的执行顺序.
其实getSetupAndCleanupTasks针对的是队列中的所有作业. 对于同一个作业, 显然必须严格按照作业执行顺序来选择任务的.
但是到多个作业就不一定了. 多个作业之间不一定要一个作业全部执行完再执行另一个作业, 而是多个作业之间可以穿插运行.
以上述场景为例, 如果优先执行job3的job-setup task. 有可能job1因为还没有完成, 正在占用着任务需要的槽位,
在槽位不够的情况下, job1只能等到有空闲的槽位才可以获得执行的机会.
因此优先选择让处于job-cleanup task的job1优先执行, 正是确保了这一点.
同时job-cleanup task执行完后, 如果是map的job-cleanup task, 就可以继续接着执行reduce.
如果是reduce的job-cleanup task, 那么作业就真正结束了. 而我们的目的正是让一个作业尽快地执行完.
限制条件
jobs队列中的作业是在提交作业后, 直到作业完成从队列中移除, 只要作业没有完成就一直存在.
因此一个作业必然经过job-setup > map > reduce > job-cleanup 这几个阶段.
在如何选择以上任务的时候, 由于作业执行顺序的约定, 有一些条件是必须限制的:
**1. 选择job-setup task:**
作业已经初始化完毕, | 作业如果还没有初始化完毕, 不能开始执行job-setup --> `前置动作`
作业状态为PREP, | 新创建JobInProgress时, 状态初始为PREP --> `前置状态`
job-setup-task还没执行, | 当前任务job-setup task还没执行才可以执行, 如果已经启动了, 就无需被选择了
作业未被kill, 作业未失败 | 作业如果还没开始就被杀死或失败, 就无需执行这个作业的准备工作了
/** Check whether setup task can be launched for the job.
* Setup task can be launched after the tasks are inited and Job is in PREP state
* and if it is not already launched or job is not Killed/Failed */
private synchronized boolean canLaunchSetupTask() {
return (tasksInited && status.getRunState() == JobStatus.PREP && !launchedSetup && !jobKilled && !jobFailed);
}
**2. 选择job-cleanup task:**
作业状态是PREP或RUNNING | 作业执行的顺序决定了作业的状态: PREP->RUNNING--[m/r]--[job-cleanup]->SUCCEEDED, 确保正确的`前置状态`
未启动job-cleanup 且job-setup已完成 | 如果job-setup未完成, 就不允许选择job-cleanup
作业被kill或者作业失败 | 作业被杀死或失败, 需要清理资源
作业所有的map和reduce任务都完成 | 确保所有`前置动作`已完成: 作业所有的map和reduce都完成了(任务不管是否成功), 才可以执行job-cleanup
/** Check whether cleanup task can be launched for the job.
* Cleanup task can be launched if it is not already launched 还没执行过
* or job is Killed 作业被杀死, 执行job-cleanup, 删除执行作业过程中产生的临时文件等
* or all maps and reduces are complete 所有的map/reduce任务都完成后, 可以执行job-cleanup */
private synchronized boolean canLaunchJobCleanupTask() {
// check if the job is running 作业状态必须是PREP或者RUNNING才可以执行job-cleanup
if (status.getRunState() != JobStatus.RUNNING && status.getRunState() != JobStatus.PREP) {
return false;
}
// check if cleanup task has been launched already or if setup isn't launched already.
// The later check is useful when number of maps is zero. 还没启动cleanup而且setup必须已经完成
if (launchedCleanup || !isSetupFinished()) { // true: !lauchedCleanup && isSetupFinished
return false;
}
// check if job has failed or killed
if (jobKilled || jobFailed) return true;
// Check if all maps and reducers have finished.
boolean launchCleanupTask = ((finishedMapTasks + failedMapTIPs) == (numMapTasks));
if (launchCleanupTask) { // 一个作业的所有map任务都完成了(尽管有些map失败了), 再判断所有reduce是否完成
launchCleanupTask = ((finishedReduceTasks + failedReduceTIPs) == numReduceTasks); // 如果作业的所有reduce都完成了, 就可以执行job-cleanup
}
return launchCleanupTask;
}数据来源:
List<TaskAttemptID> mapCleanupTasks = new LinkedList<TaskAttemptID>(); // A list of cleanup tasks for the map task attempts, to be launched
List<TaskAttemptID> reduceCleanupTasks = new LinkedList<TaskAttemptID>(); // A list of cleanup tasks for the reduce task attempts, to be launched
TaskInProgress maps[] = new TaskInProgress[0];
TaskInProgress reduces[] = new TaskInProgress[0]; // upper 4 data structures are all for task-cleanup task [2]
TaskInProgress cleanup[] = new TaskInProgress[0]; // for job-cleanup task [1]
TaskInProgress setup[] = new TaskInProgress[0]; // for job-setup task
public synchronized void updateTaskStatus(TaskInProgress tip, TaskStatus status) {
if (state == TaskStatus.State.FAILED_UNCLEAN || state == TaskStatus.State.KILLED_UNCLEAN) {
tip.incompleteSubTask(taskid, this.status);
// add this task, to be rescheduled as cleanup attempt
if (tip.isMapTask()) { mapCleanupTasks.add(taskid);
} else { reduceCleanupTasks.add(taskid); }
// Remove the task entry from jobtracker
jobtracker.removeTaskEntry(taskid);
}
}














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









