









Map Task内部实现
在Task运行过程分析2中提到,MapTask分为4种,分别是Job-setup Task、Job-cleanup Task、Task-cleanup Task和Map Task。其中,Job-setup Task和Job-cleanup Task分别是作业运行时启动的第一个任务和最后一个任务,主要工作分别是进行一些作业初始化和收尾工作,比如创建和删除作业临时输出目录;而Task-cleanup Task则是任务失败或者被杀死后,用于清理已写入临时目录中数据的任务。本文主要讲解第四种任务——普通的Map Task。它需要处理数据,并将计算结果存到本地磁盘上。
Map Task整体流程
Map Task的整体计算流程如下图所示,共分为5个阶段,分别是:
Read阶段:Map Task通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value
Map阶段:该阶段主要是将解析出的key/value交给用户编写的map()函数处理,并产生一系列新的key/value
Collect阶段:在用户编写的map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分片(通过调用Partitioner),并写入一个环形内存缓冲区中。
Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
Combine阶段:当所有数据处理完成后,Map Task对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
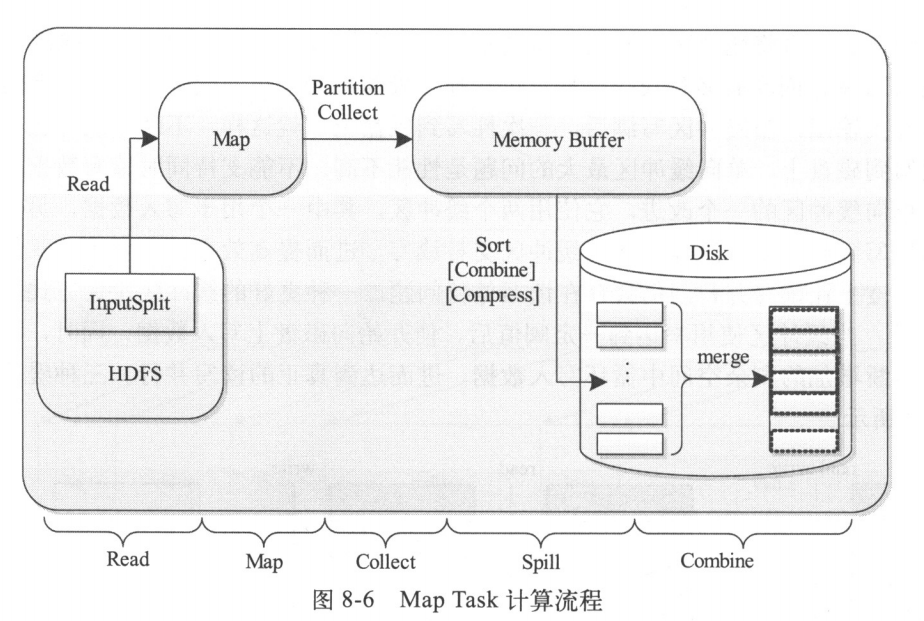
在Map Task中,最重要的部分是输出结果在内存和磁盘中的组织形式,具体涉及Collect、Spill和Combine三个阶段,也就是用户调用context.write(key,value)函数之后依次经历的几个阶段。
Collect过程分析
跟踪进入org.apache.hadoop.mapred.MapTask.java的入口函数run(),可发现,如果用户选用旧API,则会调用runOldMapper函数处理数据,如果用户选择新的API,则会调用runNewMapper函数处理数据。本文以新的API为例进行讲解。。。
跟踪进入org.apache.hadoop.mapred.MapTask.java中的runNewMapper函数,函数根据ReduceTask个数是否为0,实例化不同的org.apache.hadoop.mapreduce.RecordWriter,如果ReduceTask数目为0,则用NewDirectOutputCollector对象实例化,直接将结果写入HDFS作为最终结果,否则用NewOutputCollector对象实例化,暂时将结果写入本地磁盘上以供ReduceTask进一步处理。本章分析ReduceTask数目非0的情况
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewMapper(final JobConf job,
final TaskSplitIndex splitIndex,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException,
InterruptedException {
// make a task context so we can get the classes
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.TaskAttemptContext(job, getTaskID());
// make a mapper
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
// make the input format
org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat =
(org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)
ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
// rebuild the input split
org.apache.hadoop.mapreduce.InputSplit split = null;
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
LOG.info("Processing split: " + split);
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =
new NewTrackingRecordReader<INKEY,INVALUE>
(split, inputFormat, reporter, job, taskContext);
job.setBoolean("mapred.skip.on", isSkipping());
org.apache.hadoop.mapreduce.RecordWriter output = null;
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
mapperContext = null;
try {
Constructor<org.apache.hadoop.mapreduce.Mapper.Context> contextConstructor =
org.apache.hadoop.mapreduce.Mapper.Context.class.getConstructor
(new Class[]{org.apache.hadoop.mapreduce.Mapper.class,
Configuration.class,
org.apache.hadoop.mapreduce.TaskAttemptID.class,
org.apache.hadoop.mapreduce.RecordReader.class,
org.apache.hadoop.mapreduce.RecordWriter.class,
org.apache.hadoop.mapreduce.OutputCommitter.class,
org.apache.hadoop.mapreduce.StatusReporter.class,
org.apache.hadoop.mapreduce.InputSplit.class});
// get an output object
if (job.getNumReduceTasks() == 0) {
output =
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
mapperContext = contextConstructor.newInstance(mapper, job, getTaskID(),
input, output, committer,
reporter, split);
input.initialize(split, mapperContext);
mapper.run(mapperContext);
input.close();
input = null;
output.close(mapperContext);
output = null;
} catch (NoSuchMethodException e) {
throw new IOException("Can't find Context constructor", e);
} catch (InstantiationException e) {
throw new IOException("Can't create Context", e);
} catch (InvocationTargetException e) {
throw new IOException("Can't invoke Context constructor", e);
} catch (IllegalAccessException e) {
throw new IOException("Can't invoke Context constructor", e);
} finally {
closeQuietly(input);
closeQuietly(output, mapperContext);
}
}然后调用org.apache.hadoop.mapreduce.Mapper.java中的run()方法
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}然后会调用用户编写的map方法。用户会调用org.apache.hadoop.mapreduce.Mapper的内部类Context的write方法,该write方法是继承自org.apache.hadoop.mapreduce.TaskInputOutputContext.java的write 方法
/**
* Generate an output key/value pair.
*/
public void write(KEYOUT key, VALUEOUT value
) throws IOException, InterruptedException {
output.write(key, value);
}output是RecordWriter,它是一个抽象类,查看它的实现类org.apache.hadoop.mapred.MapTask中的内部类NewOutputCollect中的write方法
@Override
public void write(K key, V value) throws IOException, InterruptedException {
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}在该方法中,首先会调用partitioner.getPartition函数获取记录的分区号partition,然后将三元组(key,value,partition)传递给MapOutputCollector.collect()函数做进一步处理。
collect是MapOutputCollector,它是一个接口,查看它的实现例org.apache.hadoop.mapred.MapTask中的内部类的MapOutputBuffer的collect方法。。。
MapOutputBuffer内部使用了一个缓冲区暂时存储用户输出数据,当缓冲区使用率达到一定阈值后,再将缓冲区中的数据写到磁盘上。数据缓冲区的设计方式直接影响到MapTask的写效率,而现有多种数据结构可供选择,最简单的是单向缓冲区,生产者向缓冲区中单向写入数据,当缓冲区写满后,一次性写到磁盘上,就这样,不断写缓冲区,直到所有数据写到磁盘上。单向缓冲区最大的问题是性能不高,不能支持同时读写数据。双缓冲区是对单向缓冲区的一个改进,它使用两个缓冲区,其中一个用于写入数据,另一个将写满的数据写到磁盘上,这样,两个缓冲区交替读写,进而提高效率。实际上,双缓冲区只能一定程度上让读写并行,仍会存在读写等待问题。一种更好的缓冲区设计方式是采用环形缓冲区:当缓冲区使用率达到一定阈值后,便开始向磁盘上写入数据,同时,生产者仍可以向不断增加的剩余空间中循环写入数据,进而达到真正的读写并行。三种缓冲区结构如图所示:
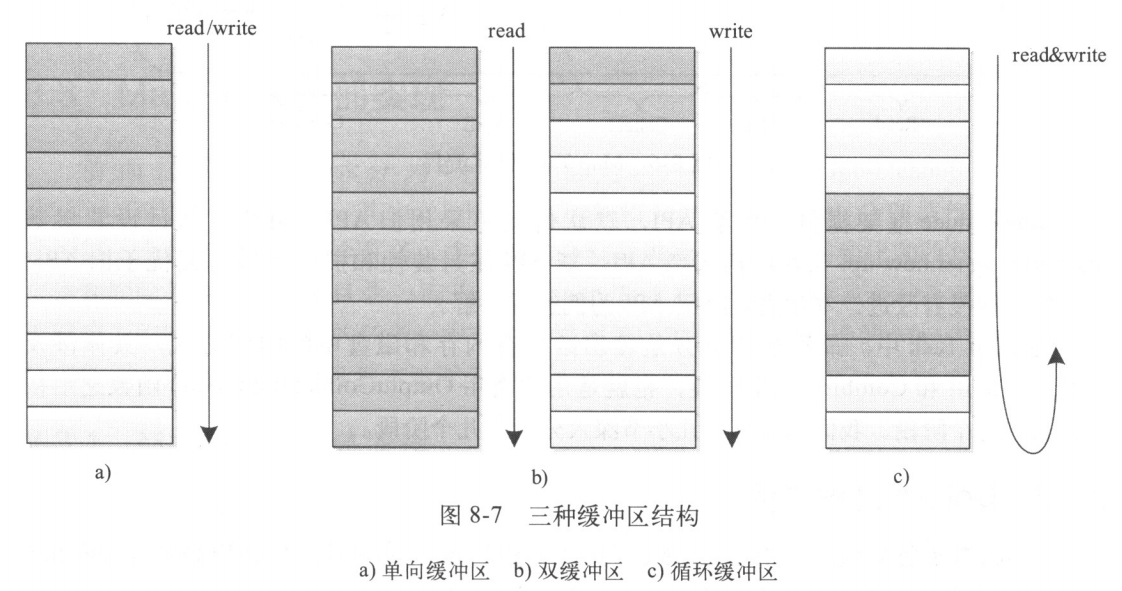
MapOutputBuffer正是采用了环形内存缓冲区保存数据,当缓冲区使用率达到一定阈值后,由线程SpillThread将数据写到一个临时文件中,当所有数据处理完毕后,对所有临时文件进行一次合并以生成一个最终文件。环形缓冲区使得MapTask的Collect阶段和Spill阶段可并行执行。
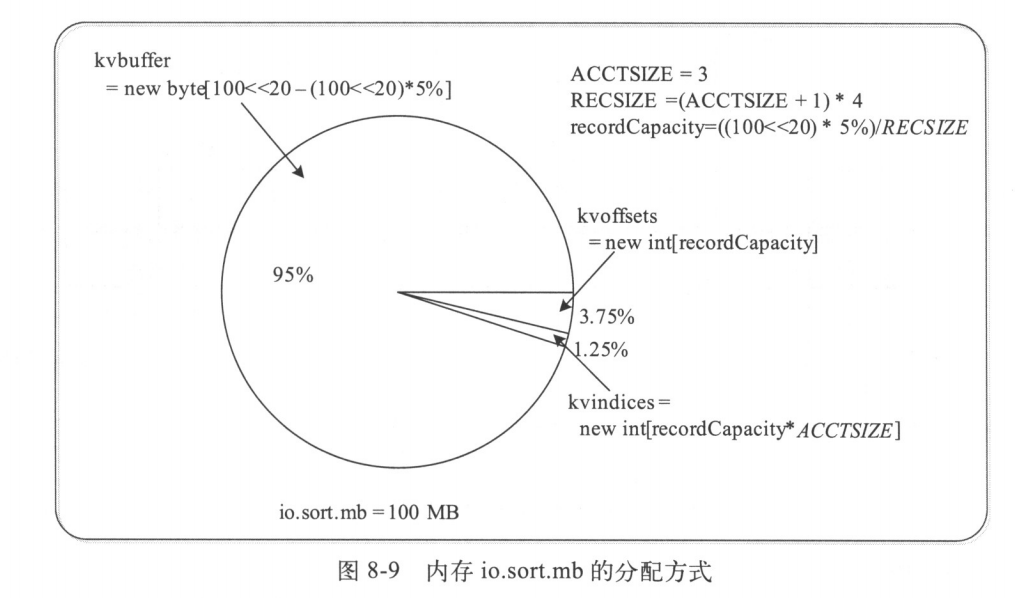
MapOutputBuffer内部采用了两级索引结构,如图所示,涉及三个环形内存缓冲区,分别是kvoffsets、kvindices和kvbuffer,这三个缓冲区所占内存空间总大小为io.sort.mb(默认是100MB)。下面分别介绍这三个缓冲区的含义
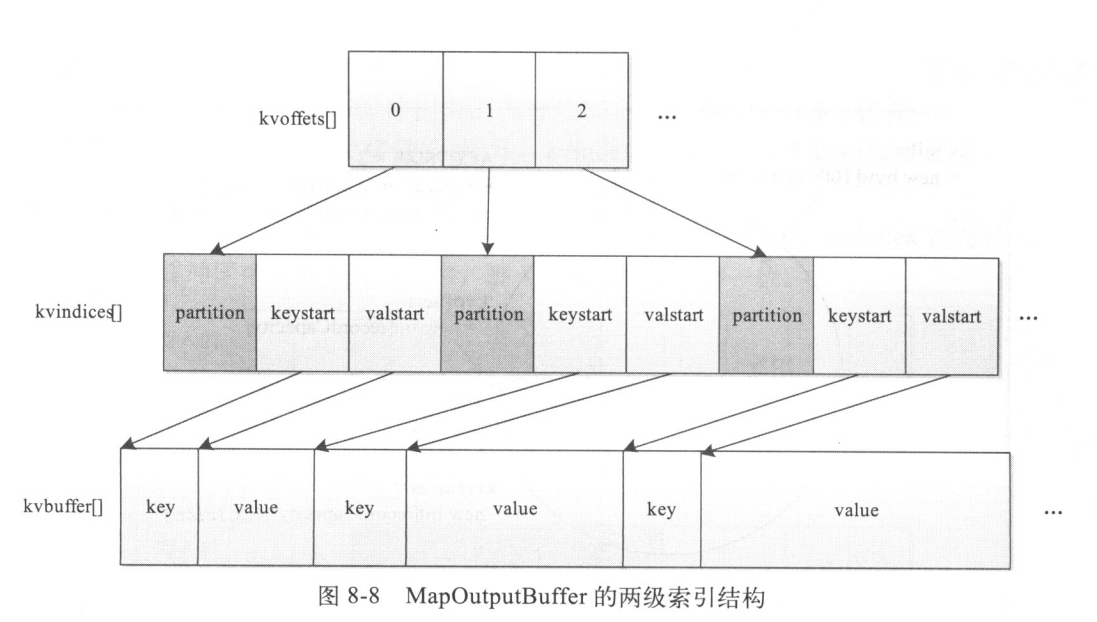
(1)kvoffsets
kvoffsets即偏移量索引数组,用于保存key/value信息在位置索引kvindices中的偏移量。考虑到一对key/value需占用数组kvoffsets的一个int(整形)大小,数组kvindices的3个int大小(分别保存所在partition号、key开始位置和value开始位置),所以Hadoop按比例1:3将大小为#{io.sort.record.percent}*#{io.sort.mb}的内存空间分配给数组kvoffsets和kvindices,计算过程在org.apache.hadoop.mapred.MapTask.java中的内部类的MapOutputBuffer的构造函数中
private static final int ACCTSIZE = 3; // 每对key/value占用kvindices中的三项
private static final int RECSIZE =
(ACCTSIZE + 1) * 4; // 每对key/value共占用kvoffsets和kvindices中的4个字节(4*4=16 byte)
final float recper = job.getFloat("io.sort.record.percent",(float)0.05);//内存中保存kvoffsets和kvindices数组所占用的内存比例
final int sortmb = job.getInt("io.sort.mb", 100);//kvoffsets、kvindices和kvbuffer所占用的总内存大小
int maxMemUsage = sortmb << 20;//将内存单元转化为字节
int recordCapacity = (int)(maxMemUsage * recper);//内存中保存kvoffsets和kvindices数组所占用的内存
recordCapacity -= recordCapacity % RECSIZE;//保证recordCapacity是4*4的整数倍
recordCapacity /= RECSIZE;//计算内存中最多保存key/value数目
kvoffsets = new int[recordCapacity];//kvoffsets占用1:3中的1
kvindices = new int[recordCapacity * ACCTSIZE];//kvindices占用1:3中的3当该数组使用率超过io.sort.spill.percent后,便会触发线程SpillThread将数据写入磁盘。
(2)kvindices
kvindices即位置索引数组,用于保存key/value值在数据缓冲区kvbuffer中的起始位置
(3)kvbuffer
kvbuffer即数据缓冲区,用于保存实际的key/value值,默认情况下最多可使用io.sort.mb中的95%,当该缓冲区使用率超过io.sort.spill.percent后,便会触发线程SpillThread将数据写入磁盘
上面三个数组缓冲区分配方式如下图所示:
以上几个缓冲区读写采用了典型的单生产者消费者模型,其中MapOutputBuffer的collect方法和MapOutputBuffer.Buffer的write方法是生产者,spillThread线程是消费者,它们之间同步是通过可重入的互斥锁spillLock和spillLock上的两个条件变量(spillDone和spillReady)完成的。
生产者的代码在org.apache.hadoop.mapred.MapTask.java中的内部类MapOutputBuffer的collect方法中
spillLock.lock();//加锁
try {
boolean kvfull;
do {
if (sortSpillException != null) {
throw (IOException)new IOException("Spill failed"
).initCause(sortSpillException);
}
// sufficient acct space
kvfull = kvnext == kvstart;//如果kvnext等于kvstart,表示缓冲区满了
final boolean kvsoftlimit = ((kvnext > kvend)
? kvnext - kvend > softRecordLimit
: kvend - kvnext <= kvoffsets.length - softRecordLimit);//计算kvoffsets是否超过阈值
if (kvstart == kvend && kvsoftlimit) {//缓冲区使用率达到阈值
LOG.info("Spilling map output: record full = " + kvsoftlimit);
startSpill();//唤醒SpillThread线程,将缓冲区数据写入磁盘
}
if (kvfull) {//缓冲区满
try {
while (kvstart != kvend) {
reporter.progress();
spillDone.await();//等待SpillThread线程结束
}
} catch (InterruptedException e) {
throw (IOException)new IOException(
"Collector interrupted while waiting for the writer"
).initCause(e);
}
}
} while (kvfull);
} finally {
spillLock.unlock();
}生产者主要的伪代码如下:
//取得下一个可写入的位置
spillLock.lock() ;
if(缓冲区使用率达到阈值){
//唤醒SpillThread线程,将缓冲区数据写入磁盘
spillReady.signal() ;
}
if(缓冲区满){
//等待SpillThread线程结束
spillDone.wait() ;
}
spillLock.unlock() ;
//将数据写入缓冲区下面分别介绍环形缓冲区kvoffsets和kvbuffer的数据写入过程。
(1)环形缓冲区kvoffsets
通常用一个线性缓冲区模拟实现环形缓冲区,并通过取模操作实现循环数据存储。下面介绍环形缓冲区kvoffsets的写数据过程。该过程由指针kvstart/kvend/kvindex控制,其中kvstart表示存有数据的内存段初始位置,kvindex表示未存储数据的内存段初始位置,而在正常写入情况下,kvend=kvstart,一旦满足溢写条件,则kvend=kvindex,此时指针区间[kvstart,kvend)为有效数据区间。具体涉及的操作如下。
操作1:写入缓冲区。
直接将数据写入kvindex指针指向的内存空间,同时移动kvindex指向下一个可写入的内存空间首地址,kvindex移动公式为:kvindex=(kvindex+1)%kvoffsets.length。由于kvoffsets为环形缓冲区,因此可能涉及两种写入情况。
情况1:kvindex大于kvend,如下图所示。在这种情况下,指针kvindex在指针kvend后面,如果向缓冲区中写入一个字符串,则kvindex指针后移一位。
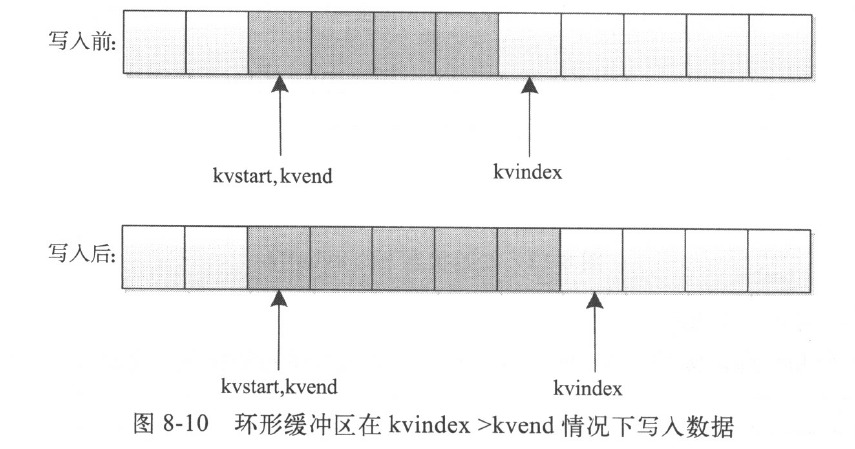
情况2:kvindex小于kvend,如下图所示。在这种情况下,指针kvindex位于指针kvend前面,如果向缓冲区中写入一个字符串,则kvindex指针后移一位。
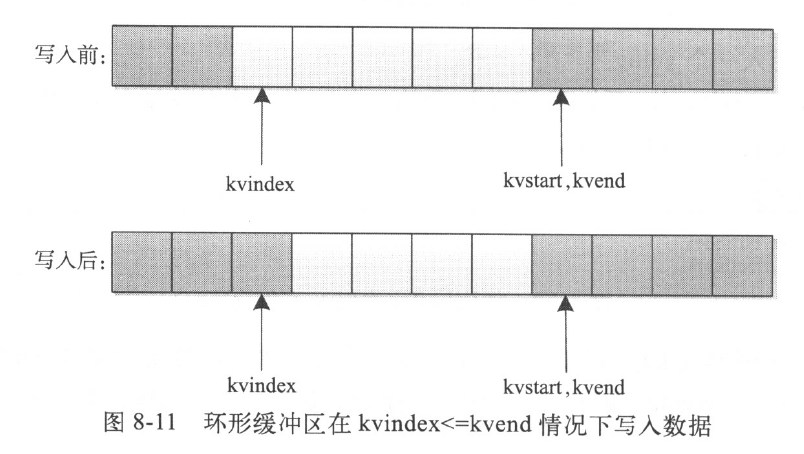
情况1和情况2对应的代码是:
final int kvnext = (kvindex + 1) % kvoffsets.length;操作2:溢写到磁盘
当kvoffsets内存空间使用率超过io.sort.spill.percent(默认是80%)后,需要将内存中数据写到磁盘上。为了判断是否满足该条件,需要先求出kvoffsets已使用内存。如果kvindex>kvend,则已使用内存大小为kvindex-kvend;否则,已使用内存大小为kvoffsets.length-(kvend-kvindex)。
对应代码为:
final boolean kvsoftlimit = ((kvnext > kvend)
? kvnext - kvend > softRecordLimit
: kvend - kvnext <= kvoffsets.length - softRecordLimit);(2)环形缓冲区kvbuffer
环形缓冲区kvbuffer的读写操作过程由指针bufstart/bufend/bufvoid/bufindex/bufmark控制,其中,bufstart/bufend/bufindex含义与kvstart/kvend/kvindex相同,而bufvoid指向kvbuffer中有效内存结束为止,bufmark表示最后写入的一个完整key/value结束位置,具体写入过程中涉及的状态和操作如下:
情况1:初始状态
初始状态下,bufstart=bufend=bufindex=bufmark=0,bufvoid=kvbuffer.length,如下图所示

情况2:写入一个key
写入一个key后,需移动bufindex指针到可写入内存初始位置,如下图所示。

// serialize key bytes into buffer
int keystart = bufindex;
keySerializer.serialize(key);情况3:写入一个value
写入key对应的value后,除移动bufindex指针外,还要移动bufmark指针,表示已经写入一个完整的key/value,具体如下图所示。

// serialize value bytes into buffer
final int valstart = bufindex;
valSerializer.serialize(value);
int valend = bb.markRecord();情况4:不断写入key/value,直到满足溢写条件,即kvoffsets或者kvbuffer空间使用率超过io.sort.spill.percent(默认值为80%)。此时需要将数据写到磁盘上,如下图所示。

在写key和alue的时候使用了如下方法
keySerializer.serialize(key);
valSerializer.serialize(value);调用了org.apache.hadoop.io.serializer.Serializer.java中的serialize方法,Serializer是一个接口,查看它的实现类org.apache.hadoop.io.serializer.WritableSerialization.java中的内部类WritableSerializer的serialize方法
public void serialize(Writable w) throws IOException {
w.write(dataOut);
}传入了java.io.DataOutputStream的dataOut实例,dataOut实例是由org.apache.hadoop.io.serializer.WritableSerialization.java中的内部类WritableSerializer的open方法实例化
public void open(OutputStream out) {
if (out instanceof DataOutputStream) {
dataOut = (DataOutputStream) out;
} else {
dataOut = new DataOutputStream(out);
}
}在org.apache.hadoop.mapred.MapTask.java中的内部类MapOutputBuffer中的构造函数中有如下两行代码
private final BlockingBuffer bb = new BlockingBuffer();
keySerializer.open(bb);
valSerializer.open(bb);而在org.apache.hadoop.mapred.MapTask.jav中的内部类MapOutputBuffer中的内部类BlockingBuffer
public BlockingBuffer() {
this(new Buffer());
}
private BlockingBuffer(OutputStream out) {
super(out);
}传入了org.apache.hadoop.mapred.MapTask.jav中的内部类MapOutputBuffer中的内部类Buffer
所以, keySerializer.serialize(key)和valSerializer.serialize(value)调用的是Buffer中的write方法
/**
* Attempt to write a sequence of bytes to the collection buffer.
* This method will block if the spill thread is running and it
* cannot write.
* @throws MapBufferTooSmallException if record is too large to
* deserialize into the collection buffer.
*/
@Override
public synchronized void write(byte b[], int off, int len)
throws IOException {
boolean buffull = false;
boolean wrap = false;
spillLock.lock();
try {
do {
if (sortSpillException != null) {
throw (IOException)new IOException("Spill failed"
).initCause(sortSpillException);
}
// sufficient buffer space?
if (bufstart <= bufend && bufend <= bufindex) {
buffull = bufindex + len > bufvoid;
wrap = (bufvoid - bufindex) + bufstart > len;
} else {
// bufindex <= bufstart <= bufend
// bufend <= bufindex <= bufstart
wrap = false;
buffull = bufindex + len > bufstart;
}
if (kvstart == kvend) {
// spill thread not running
if (kvend != kvindex) {
// we have records we can spill
final boolean bufsoftlimit = (bufindex > bufend)
? bufindex - bufend > softBufferLimit
: bufend - bufindex < bufvoid - softBufferLimit;
if (bufsoftlimit || (buffull && !wrap)) {
LOG.info("Spilling map output: buffer full= " + bufsoftlimit);
startSpill();
}
} else if (buffull && !wrap) {
// We have no buffered records, and this record is too large
// to write into kvbuffer. We must spill it directly from
// collect
final int size = ((bufend <= bufindex)
? bufindex - bufend
: (bufvoid - bufend) + bufindex) + len;
bufstart = bufend = bufindex = bufmark = 0;
kvstart = kvend = kvindex = 0;
bufvoid = kvbuffer.length;
throw new MapBufferTooSmallException(size + " bytes");
}
}
if (buffull && !wrap) {
try {
while (kvstart != kvend) {
reporter.progress();
spillDone.await();
}
} catch (InterruptedException e) {
throw (IOException)new IOException(
"Buffer interrupted while waiting for the writer"
).initCause(e);
}
}
} while (buffull && !wrap);
} finally {
spillLock.unlock();
}
// here, we know that we have sufficient space to write
if (buffull) {
final int gaplen = bufvoid - bufindex;
System.arraycopy(b, off, kvbuffer, bufindex, gaplen);
len -= gaplen;
off += gaplen;
bufindex = 0;
}
System.arraycopy(b, off, kvbuffer, bufindex, len);
bufindex += len;
}
}情况5:溢写
如果达到溢写条件,则令bufend等于bufindex,并将缓冲区[bufstart,bufend)之间的数据写到磁盘上,具体如下图所示。

代码如下:
if (bufsoftlimit || (buffull && !wrap)) {
LOG.info("Spilling map output: buffer full= " + bufsoftlimit);
startSpill();
}溢写完成之后,恢复正常写入状态,令bufstart等于bufend,如图所示
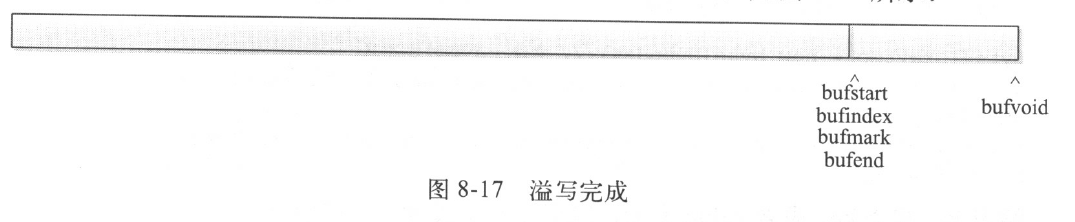
在溢写的同时,MapTask仍可向kvbuffer中写入数据,如下图所示
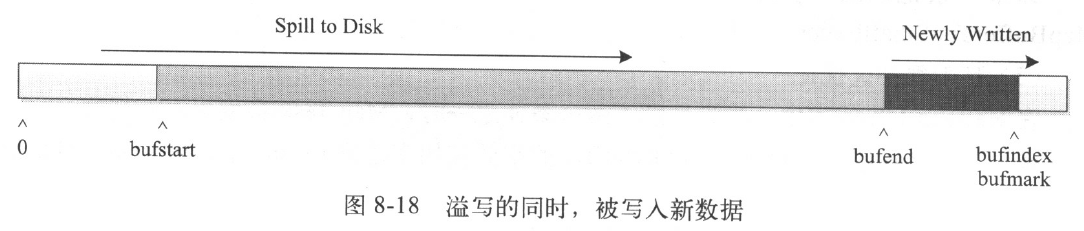
代码如下:
System.arraycopy(b,off,kvbuffer,bufindex,len) ;情况6:写入key时,发生跨界现象。
当写入某个key时,缓冲区尾部剩余空间不足以容纳整个key值,此时需要将key值分开存储,其中一部分存到缓冲区末尾,另外一部分存到缓冲区首部,具体如图所示

情况7:调整key位置,防止key跨界现象
由于key是排序的关键字,通常需交给RawComparator进行排序,而它要求排序关键字必须在内存中连续存储,因此不允许key跨界存储。为了解决该问题,Hadoop将跨界的key值重新存储到缓冲区的首位置,通常可分为以下两种情况。
A、bufindex+(bufvoid-bufmark)小于bufstart:此时缓冲区前半段有足够的空间容纳整个key值,因此可通过两次内存复制解决跨行问题。
int headbytelen = bufvoid - bufmark ;

B、bufindex+(bufvoid-bufmark)大于等于bufstart:此时缓冲区前半段没有足够的空间容纳整个key值,将key值移到缓冲区开始位置时将触发一次Spill操作。这种情况下,可通过三次内存复制解决跨行问题:
byte[] keytmp = new byte[bufindex] ;//申请一个临时缓冲区
System.arraycopy(kvbuffer,0,keytmp,0,bufindex) ;
bufindex = 0 ;
out.write(kvbuffer,bufmark,headbytelen) ; //将key值写入缓冲区开始位置
out.write(keytmp) ;情况8:某个key或者value太大,以至于整个缓冲区不能容纳它。
如果一条记录的key或value太大,整个缓冲区都不能容纳它,则MapTask会抛出MapBufferTooSmallException异常,并将该记录单独输出到一个文件中。
(3)环形缓冲区优化
在Hadoop1.X版本中,当满足以下两个条件之一时,MapTask会发生溢写现象。
条件1:缓冲区kvindices或者kvbuffer的空间使用率达到io.sort.spill.percent(默认值为80%)
条件2:出现一条kvbuffer无法容纳的超大记录。
前面提到,MapTask将可用的缓冲区空间io.sort.mb按照一定比例(有参数io.sort.record.percent决定)静态分配给了kvoffsets、kvindices和kvbuffer三个缓冲区,而正如条件1所述,只要任何一个缓冲区的使用率达到一定比例,就会发生溢写现象,即使另外的缓冲区使用率非常低。因此,设置合理的io.sort.record.percent参数,对于充分利用缓冲区空间和减少溢写次数,是十分必要的。考虑到每条数据(一个key/value对)需占用索引大小为16B,因此,建议用户采用以下公式设置io.sort。record.percent:
io.sort.record.percent=16/(16+R)
//其中R为平均每条记录的长度实例:假设一个作业的MapTask输入数据量和输出数据量相同,每个MapTask输入数据量大小为128MB,且共有1342177条记录,每条记录大小约为100B,则需要索引大小为16*1342177=20.9MB。根据这些信息,可设置参数如下:
io.sort.mb = 128MB + 20.9MB = 148.9MB
io.sort.record.percent : 16/(16+100) = 0.138
io.sort.spill.percent : 1.0这样配置可保证数据只“落”一次地,效率最高!当然,实际使用时可能很难达到这种情况,比如每个MapTask输出数据量非常大,缓冲区难以全部容纳它们,但至少可以设置合理的io.sort.record.percent以更充分地利用io.sort.mb并尽可能减少中间文件数目
接下来分析Spill过程和Combine过程。。。。















 869
869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









