









上篇:机器学习(三) -- 特征工程(1)
下篇:机器学习(四) -- 模型评估(1)
前言
tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。“!!!”一般需要特别注意或者容易出错的地方。
本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。
三、特征预处理
1、定义
通过一些转换函数,将特征数据转换成更适合算法模型的特征数据的过程。
1.1、无量纲化
也称为数据的规范化,是指不同指标之间由于存在量纲不同致其不具可比性,故首先需将指标进行无量纲化,消除量纲影响后再进行接下来的分析。
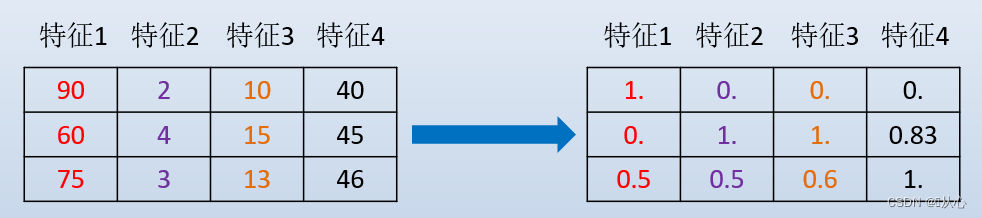
数值数据的无量纲化: 主要有两种归一化、标准化
类别型数据的无量纲化:one-hot编码
时间类型的无量纲化: 时间的切分
为什么要进行归一化/标准化?
特征的单位或者大小相差较大,或者某特征的方法相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征
特征预处理API
sklearn.preprocessing2、归一化
tips:归一化也叫离差标准化,(标准化,也叫标准差标准化,Z-Score标准化)
2.1、定义
将特征缩放到一个特定的范围,通常是[0, 1]。
2.2、分类和公式
2.2.1、线性归一化
这是最常用的归一化,也叫最大-最小归一化或最大-最小规范化。(后面也是用的这种哈)
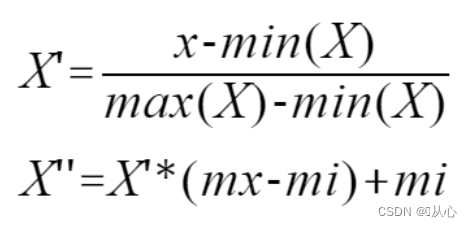
默认缩放到[0,1],如果想二次缩放,如缩放到到[-1,2]之间,则让第二个式子中的mx=2,mi=-1,即可
2.2.2、***最大最小均值归一化
2.2.3、***最大绝对值归一化
2.3、API
sklearn.preprocessing.MinMaxScaler
导入:
from sklearn.preprocessing import MinMaxScaler
语法:
MinMaxScalar(feature_range=(0,1)…)
每个特征缩放到给定范围(默认[0,1])
MinMaxScalar.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array

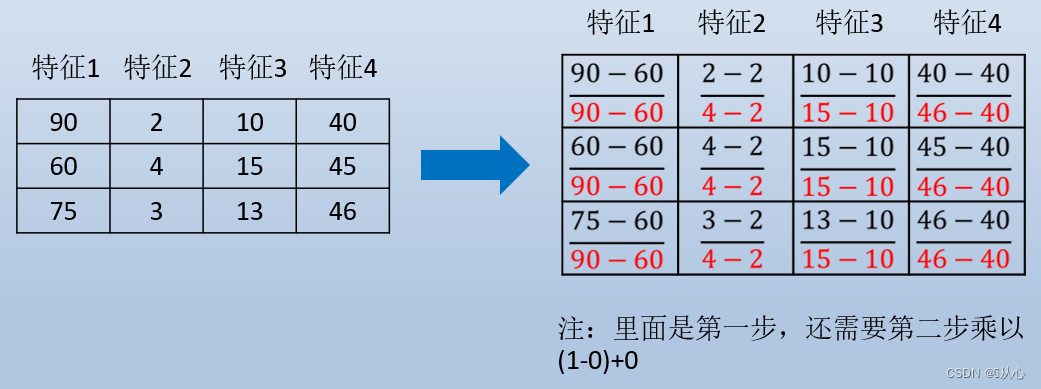
2.4、实例
流程:导入数据 --> 实例化转换器MinMaxScaler() --> 通过fit_transform()转换 --> 得到转换后数据
data=[[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
print("data:\n", data)
# 2、实例化一个转换器类
transform = MinMaxScaler()
# transform = MinMaxScaler(feature_range=[2,3])
# 3、调用fit_transform
data_new = transform.fit_transform(data)
print("data_new:\n", data_new)转换器中添加feature_range=[2,3]属性,将缩放范围变为[2,3]。

3、标准化
2.1、定义
将特征缩放为均值为0,标准差为1的分布。
2.2、公式

2.3、API
sklearn.preprocessing.StandardScaler
导入:
from sklearn.preprocessing import StandardScaler
语法:
StandardScaler(…)
处理之后每列来说所有数据都聚集在均值0附近方差为1
StandardScaler.fit_transform(X,y)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
StandardScaler.mean_
原始数据中每列特征的平均值
StandardScaler.var_
原始数据每列特征的方差

2.4、实例
流程:导入数据 --> 实例化转换器StandardScaler() --> 通过fit_transform()转换 --> 得到转换后数据
data=[[1., -1., 3.],
[2., 4., 2.],
[4., 6., -1.]]
print("data:\n", data)
# 2、实例化一个转换器类
transform = StandardScaler()
#transform = StandardScaler(feature_range=[2,3])
# 3、调用fit_transform
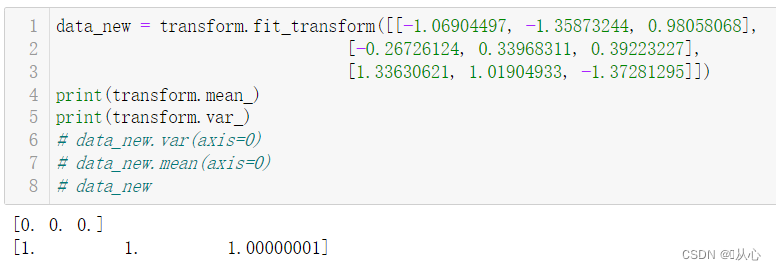
data_new = transform.fit_transform(data)
print("data_new:\n", data_new)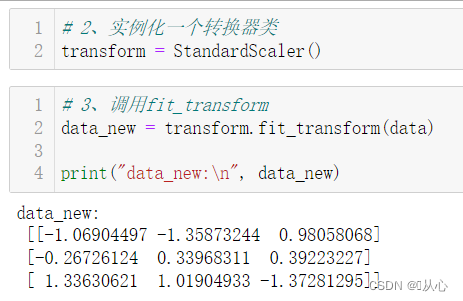
print(transform.mean_)
print(transform.var_)
print(transform.n_samples_seen_) # 样本数
验证一下:
4、***小数定标标准化
思想:通过移动数据的小数点位置来缩放特征值,使其落在一个较小的范围内,从而提高模型训练的效率和准确性。
4、***other
其实还有其他的,指数化,对数化,离散化(等频(等深)分箱、等距(等宽)分箱),正规化等。
5、缺失值处理
在数据预处理中已经说过了,缺失值处理大致就两个方法--删除、填充。
这里主要是用调用接口的方法快速完成缺失值填充处理。
5.1、API
sklearn.impute.SimpleImputer
导入:
from sklearn.impute import SimpleImputer
语法:
SimpleImputer(missing_values=np.nan, strategy='mean')
完成缺失值插补
strategy可以是['mean','median','most_frequent','constant']
['均值','中值','众数','指定值']
当为constant时,需要full_value=
SimpleImputer.fit_transform(X,y)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
5.2、实例
流程:导入数据 --> 实例化转换器SimpleImputer() --> 通过fit_transform()转换 --> 得到转换后数据
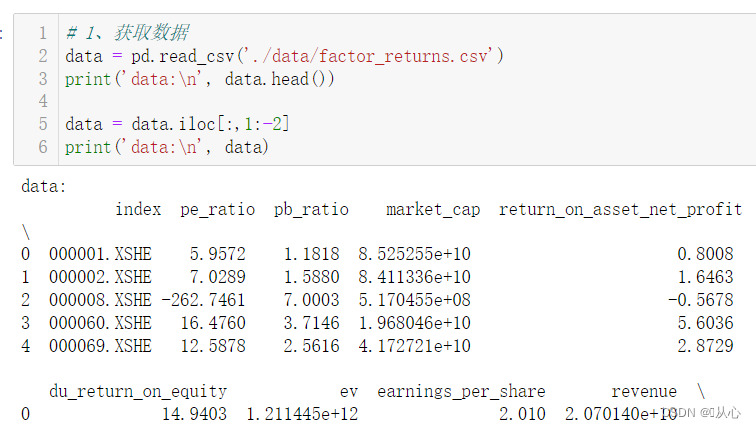
# 1、获取数据
data=[[1, 2], [np.nan, 3], [7, 6], [3, 2]]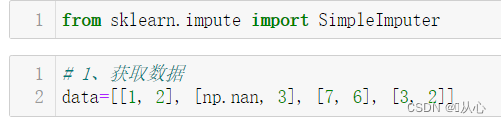
# 2、实例化一个转换器类
transform=SimpleImputer(missing_values=np.nan, strategy='mean')
# 3、调用fit_transform
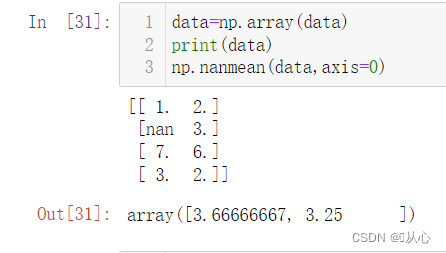
data_new=transform.fit_transform(data)
print("data_new:\n", data_new)
求证一下: nanmean():忽略nan,求均值。
6、优缺点
归一化: 优点:容易更快地通过梯度下降找到最优解
缺点:最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
标准化:优点:在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
四、特征降维
1、定义
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程。
降维的两种方式:特征选择、特征提取(主成分分析PCA,线性判别分析LDA)
本章主要讲,特征选择中的方差选择法,Pearson 相关系数,以及特征提取中的PCA。
2、特征选择
2.1、定义
数据中包含冗余或相关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征。
冗余:部分特征的相关度高,容易消耗计算性能
噪声:部分特征对预测结果有负影响
2.2、方法
(3种,掌握前两种)
Filter(过滤式):
主要探究特征本身特点、特征与特征和目标值之间关联
方差选择法:低方差特征过滤(方差低说明不同数据之间区分不明显,无法作为分类依据,应该删除。)
相关系数:特征与特征之间的相关程度
Embedded(嵌入式):(后面讲)
算法自动选择特征(特征与目标值之间的关联)
决策树:信息熵、信息增益
正则化:L1,L2
深度学习:卷积等
***Wrapper(包裹式):
包裹式从初始特征集合中不断的选择特征子集,训练学习器,根据学习器的性能来对子集进行评价,直到选择出最佳的子集。
包裹式特征选择直接针对给定学习器进行优化。
优点:从最终学习器的性能来看,包裹式比过滤式更好;
缺点:由于特征选择过程中需要多次训练学习器,因此包裹式特征选择的计算开销通常比过滤式特征选择要大得多。
2.3、API
sklearn.feature_selection2.4、低方差特征过滤
删除低方差的一些特征
- 特征方差小:某个特征大多样本的值比较相近
- 特征方差大:某个特征很多样本的值都有差别
API
sklearn.feature_selection.VarianceThreshold
导入:
from sklearn.feature_selection import VarianceThreshold
语法:
VarianceThreshold(threshold = 0.0)
删除所有低方差特征
默认只删除方差为0,threshold是方差阈值,删除比这个值小的那些特征。
Variance.fit_transform(X,y)
X:numpy array格式的数据[n_samples,n_features]
返回值:训练集差异低于threshold的特征将被删除。
默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
流程:导入数据 --> 实例化转换器VarianceThreshold() --> 通过fit_transform()转换 --> 得到转换后数据
data=[[0, 2, 0, 3],
[0, 1, 4, 3],
[0, 1, 1, 3]]
# 2、实例化一个转换器类
transform = VarianceThreshold()
# transform = VarianceThreshold(threshold=10)
# 3、调用fit_transform
data_new = transform.fit_transform(data)
print("data_new\n", data_new,
'\n data_new.shape:', data_new.shape)
# 获得剩余的特征的列编号
print('剩余的特征列编号 %s' % transform.get_support(True))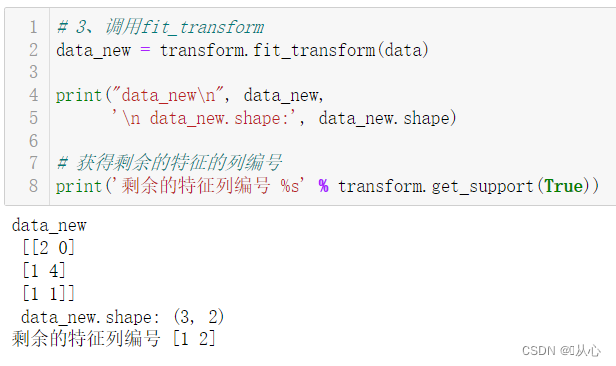
训练集差异低于threadshold的特征将被删除。默认值是保留非零方差特征,即删除所有样本中具有相同值的特征。
get_support()可以获取剩余的特征的列编号。
2.5、皮尔逊相关系数(Pearson Correlation Coefficient)
反映变量之间相关关系密切程度的统计指标。
2.5.1、公式
相关系数的值介于-1与+1之间:
相关系数的绝对值越大,相关性越强:
相关系数越接近于1或-1,相关性越强,
相关系数越接近于0,相关度越弱。
当r>0时,表示两变量正相关;
r<0时,两变量为负相关;
当|r|=1时,表示两变量为完全相关;
当r=0时,表示两变量间无相关关系;
当0<|r|<1时,表示两变量存在一定程度的相关。且|r|越接近1,两变量间线性关系越密切;|r|越接近0,表示两变量的线性相关越弱。
一般可按三级划分:|r|<0.4为低度相关;0.4<=|r|<0.7为显著相关;0.7<=|r|<1为高维线性相关
2.5.2、实例
API
from scipy.stats import pearsonr
from sklearn.feature_selection import VarianceThreshold
简单理解:
# # 数据准备
# x = [1, 2, 3, 4, 5]
# y = [6, 7, 8, 9, 10]
# # 数据准备
# x = [1, 2, 3, 4, 5]
# y = [10, 9, 8, 7, 6]
# 数据准备
x=np.random.rand(10)
y=np.random.rand(10)
# 计算相关系数和p值
corr, p_value = pearsonr(x, y)
print(pearsonr(x,y))
print("相关系数:", corr)
print("p值:", p_value)
实例:
流程:导入数据 --> 实例化转换器VarianceThreshold() --> 通过fit_transform()转换 --> 转换后数据进行相关性分析
# 2、实例化一个转换器类
#transform = VarianceThreshold()
transform = VarianceThreshold(threshold=10)
# 3、调用fit_transform
data_new = transform.fit_transform(data)
print("data_new\n", data_new,
' \n data_new.shape:', data_new.shape)
# 计算两个变量之间的相关系数
r = pearsonr(data["pe_ratio"],data["pb_ratio"])
print("相关系数:\n", r)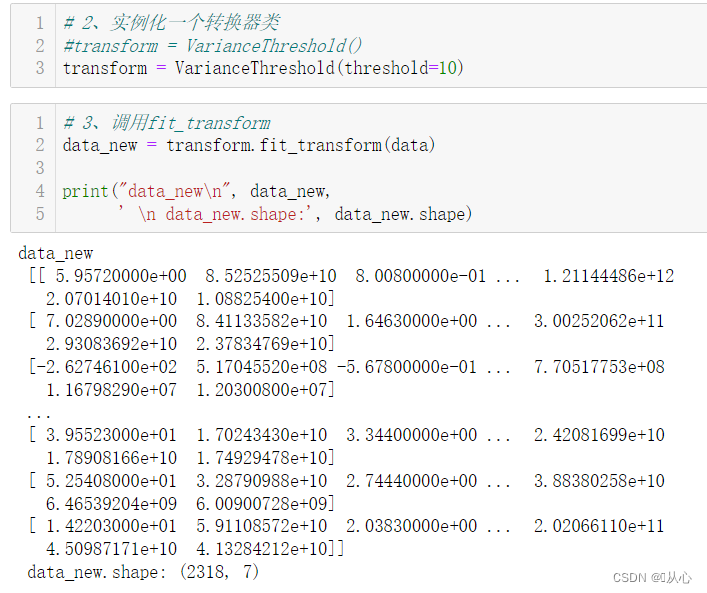
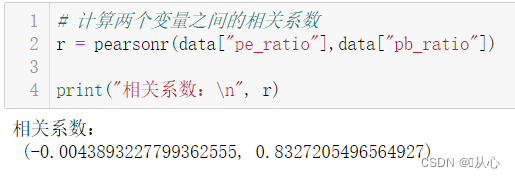
前面的数为相关系数。
3、主成分分析(PCA)
3.1、定义
旨在利用降维的思想,把多指标转化为少数几个综合指标(即主成分),其中每个主成分都能够反映原始变量的大部分信息,且所含信息互不重复。
本质:PCA是一种分析、简化数据集的技术
目的:是数据维数的压缩,尽可能降低原数据的维数(复杂度),损失少量信息
作用:可以削减回归分析或者聚类分析中特征的数量
3.2、理解
数据:
(-1,-2)
(-1, 0)
( 0, 0)
( 2, 1)
( 0, 1)
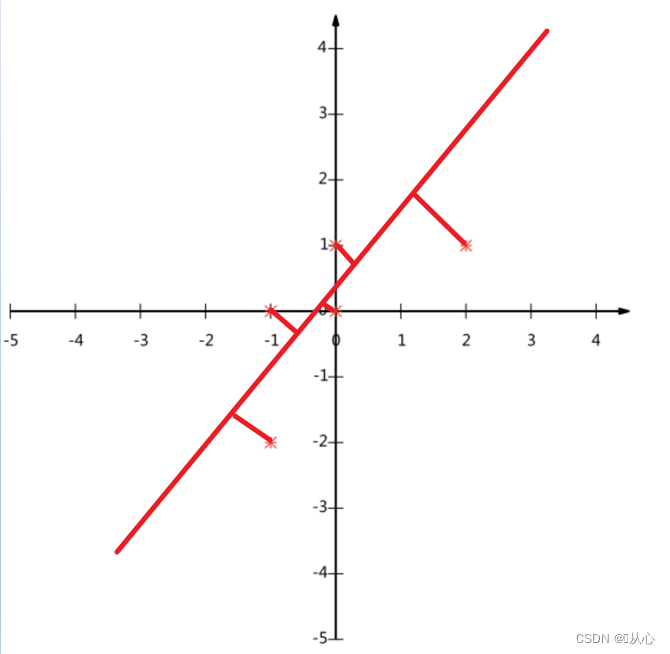
PCA遵循一定原则,如二维简化成为一维, (不是将某一维度进行删除,计算后的值一般不和原来任何值相等)要求所有的点到直线的垂直距离最小(其实就是后面要讲的最小二乘法),降维后特征值更能反应原空间中特征值的特点
-- 点到线的垂直距离和最小,这样就确定了对应的线,也确定了每个点在新的维度上的特征值
3.3、实例
API
sklearn.decomposition.PCA
导入:
from sklearn.decomposition import PCA
语法:
PCA(n_components=None)
将数据分解为较低维数空间
n_ components:整数 减少到的特征数量
小数 0~1、90% 业界选择:90~95%
PCA.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后指定维度的array
![]()
流程:导入数据 --> 实例化转换器PCA() --> 通过fit_transform()转换 --> 得到转换后数据

# 1、实例化一个转换器类
transform = PCA(n_components=2) # 4个特征降到2个特征
# 2、调用fit_transform
data_new = transform.fit_transform(data)
print("data_new\n", data_new)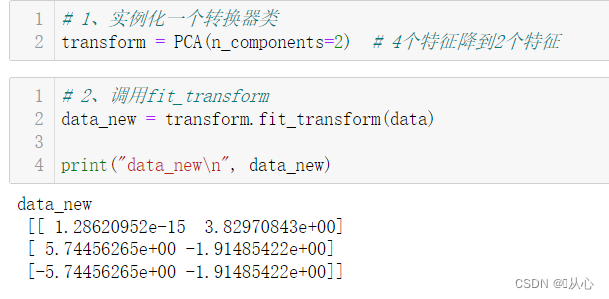
# 1、实例化一个转换器类
transform2 = PCA(n_components=0.95) # 保留95%的信息
# 2、调用fit_transform
data_new2 = transform2.fit_transform(data)
print("data_new2\n", data_new2) 
旧梦可以重温,且看:机器学习(三) -- 特征工程(1)
欲知后事如何,且看: 机器学习(四) -- 模型评估(1)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









