







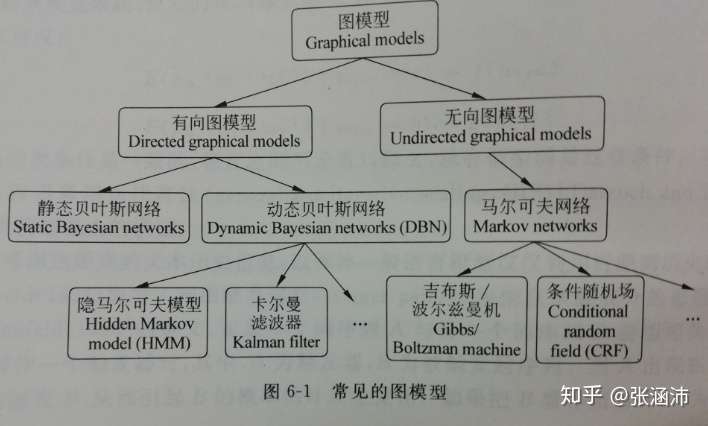
隐马尔科夫模型定义
隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。
隐藏的马尔可夫链随机生成的状态的序列,称为状态序列(state sequence);每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列(observation sequence)。
的每一个位置又可以看作是一个时刻
一个模型
隐马尔可夫模型由初始状态概率向量π、状态转移概率矩阵A和观测概率矩阵B决定。π和A决定状态序列,B决定观测序列。因此序列,隐马尔可夫模型可以用三元符号表示,即
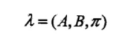
称为隐马尔可夫模型的三要素。
如果加上一个具体的状态集合Q和观测序列V,构成了HMM的五元组,这也是隐马尔科夫模型的所有组成部分。
隐马尔科夫模型的两个基本假设

三个问题
HMM的三个问题

概率计算问题。 给定模型算观测序列的概率 即计算头晕 正常 感冒概率
考虑一个村庄,所有村民都健康或发烧,只有村民医生才能确定每个人是否发烧。医生通过询问患者的感受来诊断发烧。村民只能回答说他们觉得正常,头晕或感冒。
医生认为,他的患者的健康状况作为离散的马可夫链。 “健康”和“发烧”有两个状态,但医生不能直接观察他们;健康与发烧的状态是隐藏的。每天都有机会根据患者的健康状况,病人会告诉医生他/她是“正常”,“感冒”还是“头昏眼花”。(正常,感冒,还是晕眩是我们前面说的观测序列)
观察(正常,感冒,晕眩)以及隐藏的状态(健康,发烧)形成隐马尔可夫模型(HMM),并可以用Python编程语言表示如下:
obs = ('normal', 'cold', 'dizzy')
states = ('Healthy', 'Fever')
start_p = {'Healthy': 0.6, 'Fever': 0.4}
trans_p = {
'Healthy' : {'Healthy': 0.7, 'Fever': 0.3},
'Fever' : {'Healthy': 0.4, 'Fever': 0.6}
}
emit_p = {
'Healthy' : {'normal': 0.5, 'cold': 0.4, 'dizzy': 0.1},
'Fever' : {'normal': 0.1, 'cold': 0.3, 'dizzy': 0.6}
}学习问题 给定观测序列学习模型参数
预测问题 给定模型 观测序列 预对应的隐藏标签 如健康 生病(隐藏状态) 或者对应标注
我们知道了观测序列是(Dizzy,Cold,Normal),也知道了HMM的参数,让我们求出造成这个观测序列最有可能对应的状态序列。比如说是(Healthy,Healthy,Fever)还是(Healthy,Healthy,Healthy),等等(这里有2的三次方8个)
HMM首先出现,MEMM其次,CRF最后。三个算法主要思想如下:
1)HMM模型是对转移概率和表现概率直接建模,统计共现概率,HMM就是典型的概率有向图,其就是概率有向图的计算概率方式,只不过概率有向图中的前边节点会有多个节点,而隐马尔可夫前面只有一个节点。
2)MEMM模型是对转移概率和表现概率建立联合概率,统计时统计的是条件概率,但MEMM容易陷入局部最优,是因为MEMM只在局部做归一化。
3)CRF模型中,统计了全局概率,在 做归一化时,考虑了数据在全局的分布,而不是仅仅在局部归一化,这样就解决了MEMM中的标记偏置(label bias)的问题。
- 对于CRF的话,其判断这个标注成立的概率为 P= F(s转移到s,’我’表现为s)….F为一个函数,是在全局范围统计归一化的概率而不是像MEMM在局部统计归一化的概率,MEMM所谓的局部归一化,我的理解就是你加了一个前提条件下的概率,也就是前提条件下概率也要满足各个概率之和为1,是这样的局部归一化。当前,最后出现的CRF在多项任务上达到了统治级的表现,所以如果重头搞应用的话,大家可以首选CRF。
本质上,CRF有以下三个优点:
1)与HMM比较,CRF没有HMM那样严格的独立性假设条件,因而可以容纳任意的上下文信息。特征设计灵活(与ME一样)
2)与与MEMM比较,由于CRF计算全局最优输出节点的条件概率,它还克服了最大熵马尔可夫模型标记偏置(Label-bias)的缺点。
3)CRF是在给定需要标记的观察序列的条件下,计算整个标记序列的联合概率分布,而不是在给定当前状态条件下,定义下一个状态的状态分布。凡事都有两面,正由于这些优点,CRF需要训练的参数更多,与MEMM和HMM相比,它存在训练代价大、复杂度高的缺点。
将三者放在一块做一个总结:
- HMM -> MEMM: HMM模型中存在两个假设:一是输出观察值之间严格独立,二是状态的转移过程中当前状态只与前一状态有关。但实际上序列标注问题不仅和单个词相关,而且和观察序列的长度,单词的上下文,等等相关。MEMM解决了HMM输出独立性假设的问题。因为HMM只限定在了观测与状态之间的依赖,而MEMM引入自定义特征函数,不仅可以表达观测之间的依赖,还可表示当前观测与前后多个状态之间的复杂依赖。
- MEMM -> CRF:
- CRF不仅解决了HMM输出独立性假设的问题,还解决了MEMM的标注偏置问题,MEMM容易陷入局部最优是因为只在局部做归一化,而CRF统计了全局概率,在做归一化时考虑了数据在全局的分布,而不是仅仅在局部归一化,这样就解决了MEMM中的标记偏置的问题。使得序列标注的解码变得最优解。
- HMM、MEMM属于有向图,所以考虑了x与y的影响,但没讲x当做整体考虑进去(这点问题应该只有HMM)。CRF属于无向图,没有这种依赖性,克服此问题。















 2127
2127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









