






数据属性
- 标称属性:它的值是符号或者事务的名字,其中每个值代表某种类别、编码或状态。
- 二元属性:即布尔属性,只有两个状态0或1,如果两个状态同等重要,则该属性是对称的,否则是非对称的。
- 序数属性:其可能值之间具有有意义的许或者排位,但是相继之间的差是未知的。
- 数值属性:该属性是定量的,用整数或实数表示。该属性有两种类型:区间标度(其值用固定的相等的单位测量)和比率标度(具有固有零点的数值属性)。
基本统计度量
度量数据中心趋势
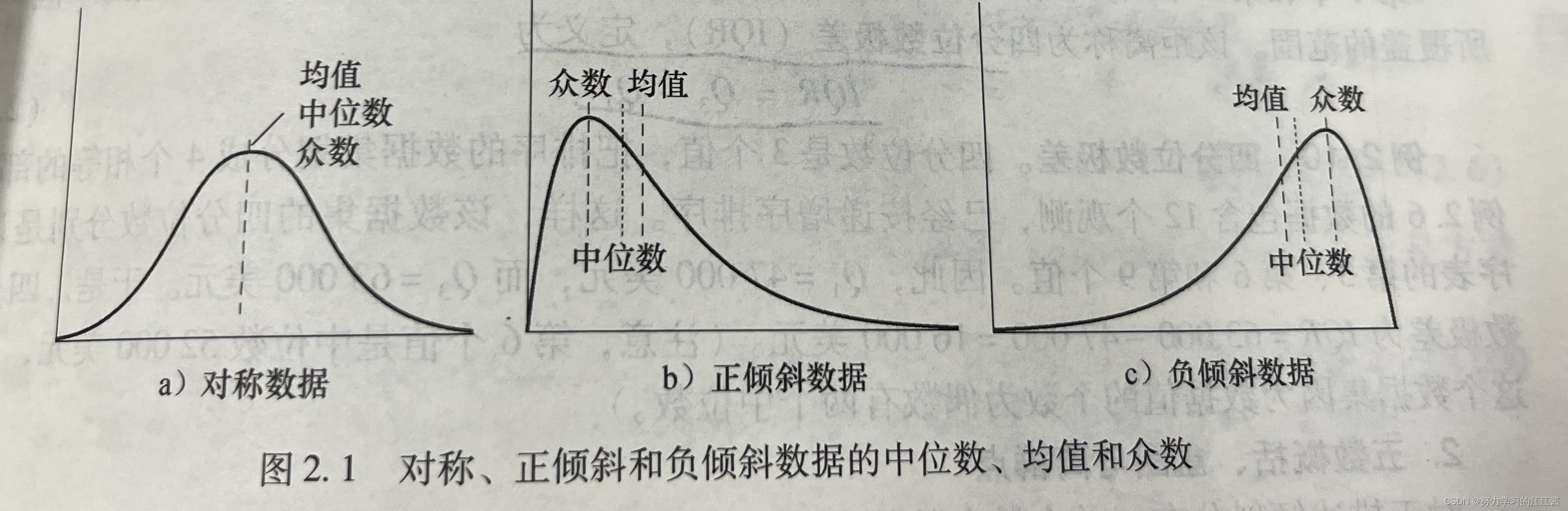
包括均值、中位数、众数、中列数。
中心趋势也就是度量数据分布的中部或中心位置。
频率:区间内数值的个数。
1.均值(mean)
数据集“中心”的最常用、最有效的数值度量是均值。
加权平均值或加权平均
加权:即权重,反应它们所依附的对应值的意义、重要性或出现的频率。
计算:xmean = ( ω1x1 + ω2x2 + … +ωNxN ) / ( ω1 + ω2 + … + ωN )
缺点:对极端值(例如:离群点)很敏感。
使用截尾均值:丢弃高低极端值后的均值。
2.中位数(median)
定义:有序数据值的中间值。
计算:N 个数值,若 N 是奇数,第 (N + 1) / 2 个数据为中位数,若 N 是偶数,则中位数不唯一,它是最中间的两个值和它们之间的任意值(在数值属性的情况下,中位数取最中间连个值的平均值)。
特点:主要度量倾斜(非对称)数据。
把数据较高的一半与较低的一半分开的值。
当数据集中值的数量很大时,中位数的计算:
用插值计算整个数据集的中位数的近似值,(将数据集划分为多个区间(如,1-000、1001-2000、2001-3000))
median = L1 + (( N/2 - (Σfreq)l ) / freqmedian ) width
median:整个数据集的中,该种属性的中位数;
L1 :中位数区间(包含中位数频率的区间,也就是包含中位数所在位置的区间)的下限(最小值);
N:整个数据集中数值的个数;
(Σfreq)l:低于中位数区间的的所有区间的频率的和;(也就是在中位数区间以后的所有区间中数值的数量的总和)
freqmedian:中位数区间的频率;(中位数所在区间的数值的个数)
width:中位数区间的宽度(区间的最大值与最小值的差)
3.众数(mode)
众数:数据集中出现频率最多的值;
最高频率对应多个值时,会有多个众数;
具有一个、两个、三个众数的数据集合,分别称为单峰的(unimodal)、双峰的(bimodal)、三峰的(trimodal)。
一般具有两个或更多众数的数据集是多峰的(multimodal)。
如果数据集中每个数值只出现一次,该数据集没有众数。
对于适度倾斜(非对称)的单峰数值数据,经验关系:mean - mode ≈ 3 X ( mean - median ) ;(也就是,如果均值和中位数已知,则适度倾斜的单峰频率曲线的众数容易近似计算)
4.中列数(midrange)
中列数:数据集中最大值和最小值的平均值,也可以用来评估数值数据的中性趋势。(中列数容易使用 SQL 的聚集函数 max() 和 min() 计算)
度量数据散步
包括极差(range)、四分位数(quartile)、方差(variance)、标准差(standard deviation)、四分位极差(IQR)
1.极差、四分位数、四分位数极差
极差:数据集中最大值和最小值的差。
分位数:取至数据分布的每隔一定间隔上的点,把数据划分成基本上大小相等的连贯集合。(说是基本上,因为可能不存在把数据划分成恰好大小相等的诸子集的X的数据值)
四分位数:第 N/4(Q1)、第 N/2(Q2,也即是中位数)、第3N/4(Q3) 的数,将数据划分为4份。(N表示数据集的数值的总个数)
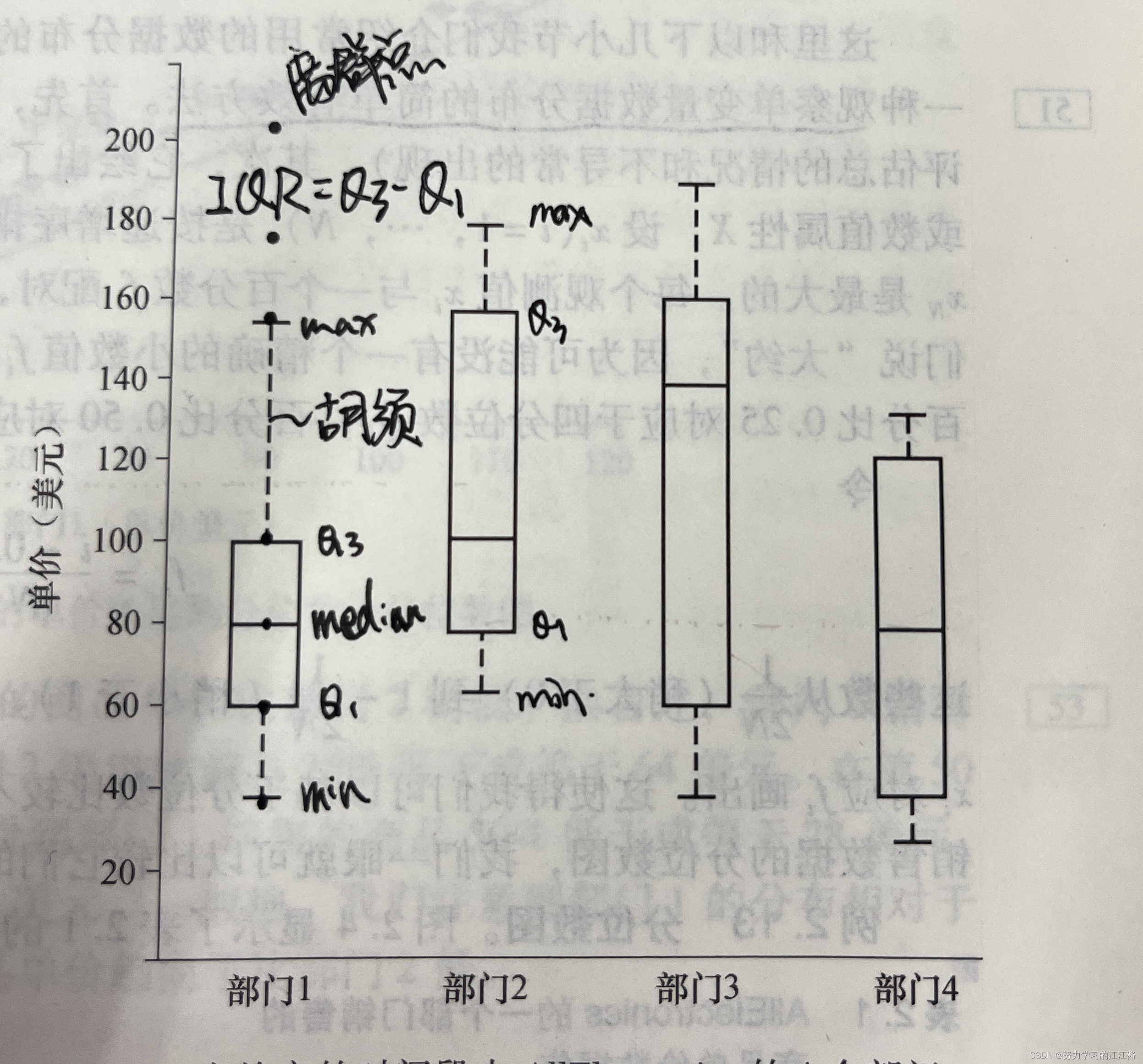
四分位数极差:IQR = Q3 - Q1;
2.五数概括(five-number summary)、盒图、离群点
对于描述倾斜分布,不能使用单个散布数值度量。
识别离群点的方法:挑选落在 Q3 以上或 Q1 以下至少 1.5IQR处的值。
五数概括:不仅使用 Q1、中位数、Q3,同时提供最高和最低数据值。(共5个数)
盒图(boxplot)
盒图可以用来比较若干个可比较的数据集。
描述数据分布的直观表示,体现了五数概括:
Q1、Q3、IQR:盒(实线长方形)的端点一般在四分位数上,使得盒图长度是四分位数的极差 IQR;
中位数:中位数用盒图的线表示;
胡须:盒外的两条线(与虚线相连的两条线,称作胡须)延伸到最小(Minimum)和最大(Maximum)观测值(观测值:被分析的数据集中的所有数值);(胡须延伸处的最大为 Q3 + 1.5IQR,最小为Q1 - 1.5IQR,超出范围的视为离群点)、(胡须的末端必须是观测值,也就是说,胡须的末端不一定等于 Q3+1.5IQR 或 Q1-1.5IQR)
离群点:处于胡须外的观测值;(仅当最高和最低观测值超过四分位数不到 1.5IQR 时,胡须扩展到它们(离群点),否则,胡须在出现在四分位数的 1.5IQR 之内的最极端的观测值处终止,剩下的情况个别的绘出)
3.方差、标准差
作用:方差和标准差都是数据分布度量,指出数据分布的散布程度;
低标准差意味着数据观测趋向于非靠近均值,高标准差表示数据分布在一个大的值域内;
σ²:方差;σ:标准差;
标准差的性质:σ 度量关于均值的发散,仅当选择均值作为中心度量时使用;仅当不存在发散时,即当所有的观察值都均有相同值时,σ = 0;否则,σ > 0;一般,一个观测值远离均值不会超过数倍个标准差。(也就是说: X观察值 - mean ≠ nσ)大型数据库中,方差和标准差的计算是可伸缩的。
度量数据的相似性和相异性
主要的基于内存的聚类、最近邻算法都在如下两种数据结构上运行:数据矩阵和相异性矩阵。


数值属性的相异性的距离度量
包括欧几里得距离、曼哈顿距离、闵可夫斯基距离。
1.欧几里得距离
即直线或乌鸦飞行距离(直线距离)
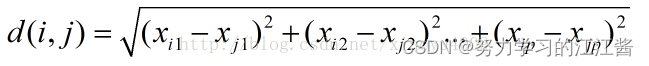
2.曼哈顿距离
两点在南北方向上的距离+东西方向上的距离
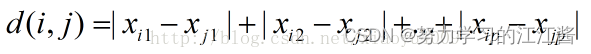
3.闵可夫斯基距离
是以上两种距离的推广
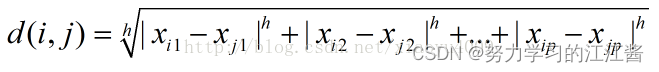
h越大越精确,当h=1,表示的是曼哈顿距离;当h=2,表示的是欧几里得距离。
4.上确界距离
又称切比雪夫距离或棋盘距离,定义为两个对象的最大值的差















 2334
2334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









