






常见的聚类算法:
- 基于划分算法
- 基于层次算法
- 基于密度算法
- 基于网格算法
- 基于模型算法
基于划分算法就是根据用户输入值k把给定对象分成k组,每组都是一个聚类,然后利用循环在定位技术变化里面的对象,直到满足指定条件为止,典型的基于划分算法有k-means和k-中心点算法。
k-means算法是一种基于距离的聚类算法,采用欧几里得距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
基本过程:
① 首先输入k的值,即希望将数据集D={o1,o2,…,on}经过聚类得到k个分类或分组。
② 从数据集D中随机选择k个数据点作为簇质心,每个簇质心代表一个簇。这样得到的簇质心集合为Centroid={Cp1,Cp2,…,Cpk}。
③ 对D中每一个数据点oi,计算oi与Cpj(j=1,2,…,k)的距离,得到一组距离值,从中找出最小距离值对应的簇质心Cps,则将数据点oi划分到以Cps为质心的簇(Cs簇)中。
④ 根据每个簇所包含的对象集合,重新计算得到一个新的簇质心。若|Cx|是第x个簇Cx中的对象个数,mx是这些对象的质心。
⑤ 如果这样划分后满足目标函数的要求,可以认为聚类已经达到期望的结果,算法终止。否则需要迭代③~⑤步骤。通常目标函数设定为所有簇中各个对象与均值间的误差平方和小于某个阈值ε,即
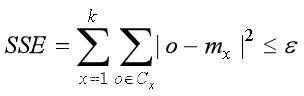
完整算法:

**
K-means优点:
(1) 算法框架清晰,简单,容易理解。
(2)算法确定的k个划分会使误差平方和 SSE 最小。当聚类是密集的,且类与类之间区别明显时,效果较好。
(3)对于处理大数据集,这个算法是机对可伸缩和高效的。
K-means缺点:
(1)算法中k要事先给定,这个k值的的选定是非常难以估计的。
(2)算法对异常数据如噪声和离群点很敏感。在计算质心的过程中,如果某个数据很异常,在计算均值的时候,会对结果影响非常大。
(3)算法首先需要确定一个初始划分 ,然后对初始划分进行优化。这个初始聚类中心的
选择对聚类结果有较大的影响。
(4)算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大的。
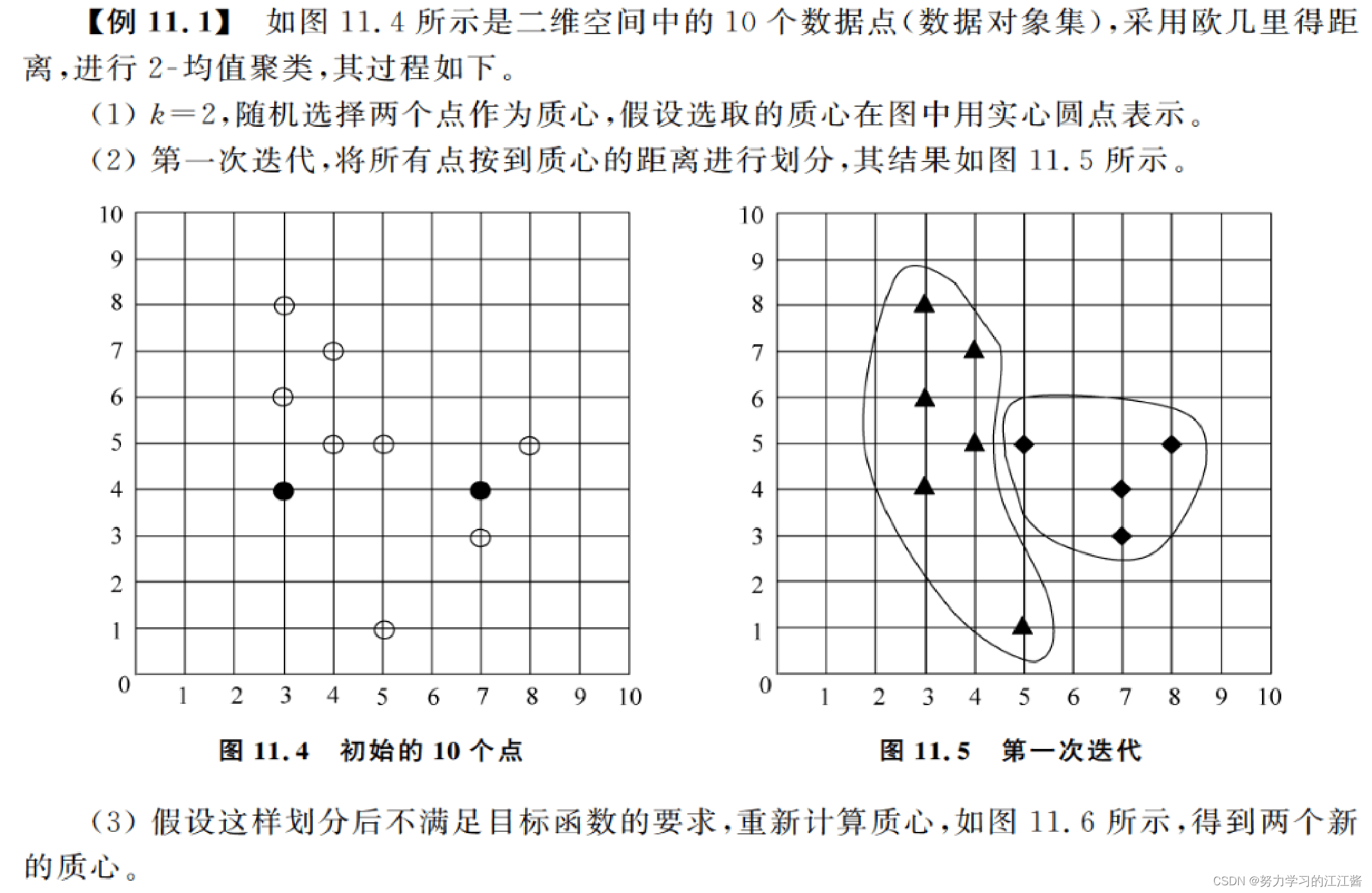
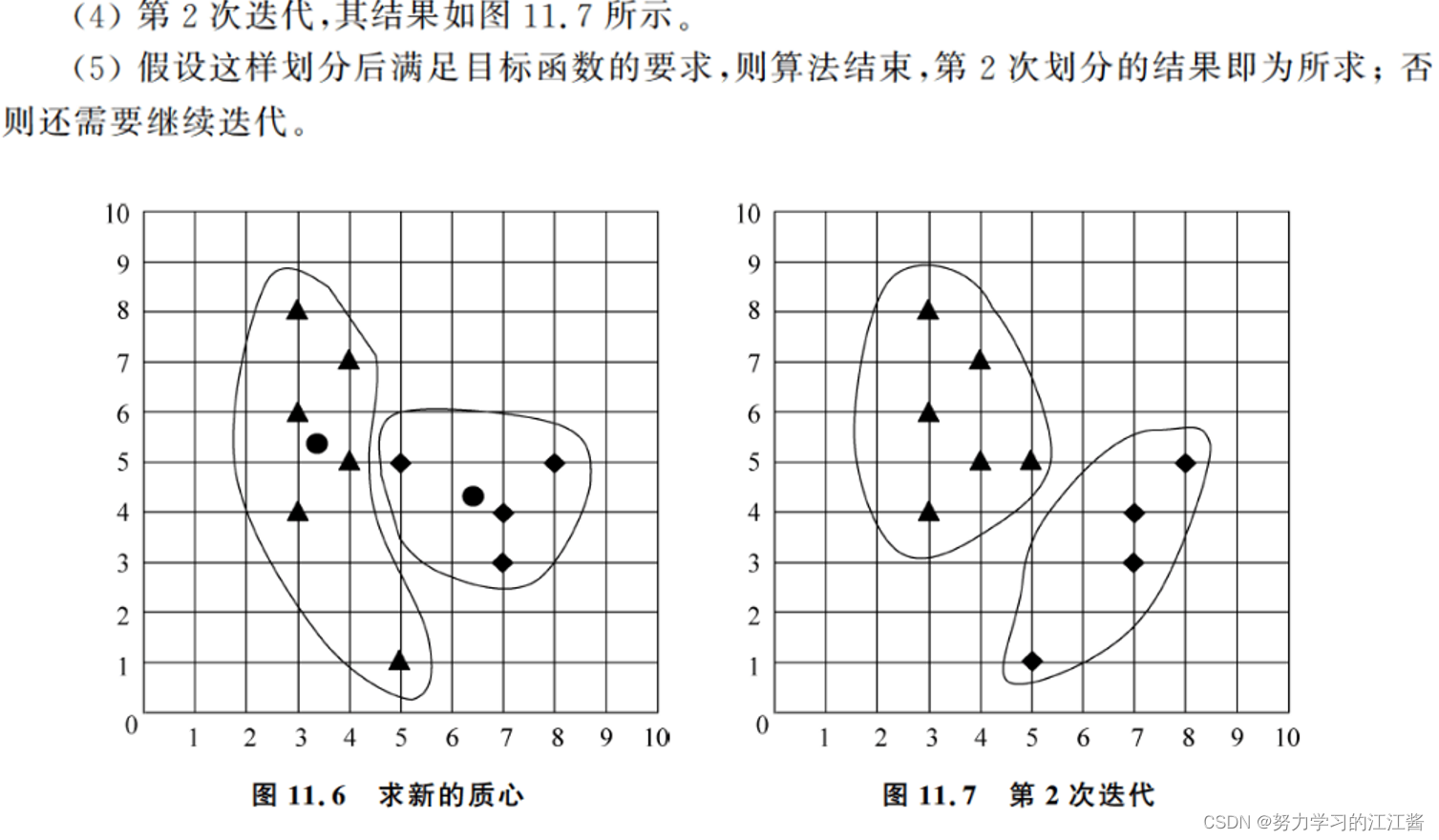
EX:















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









