







最近的应用场景为捉取中国南浔的新闻,分为两个部分,一个是首页轮播新闻图,一个是更多新闻的新闻列表分页。
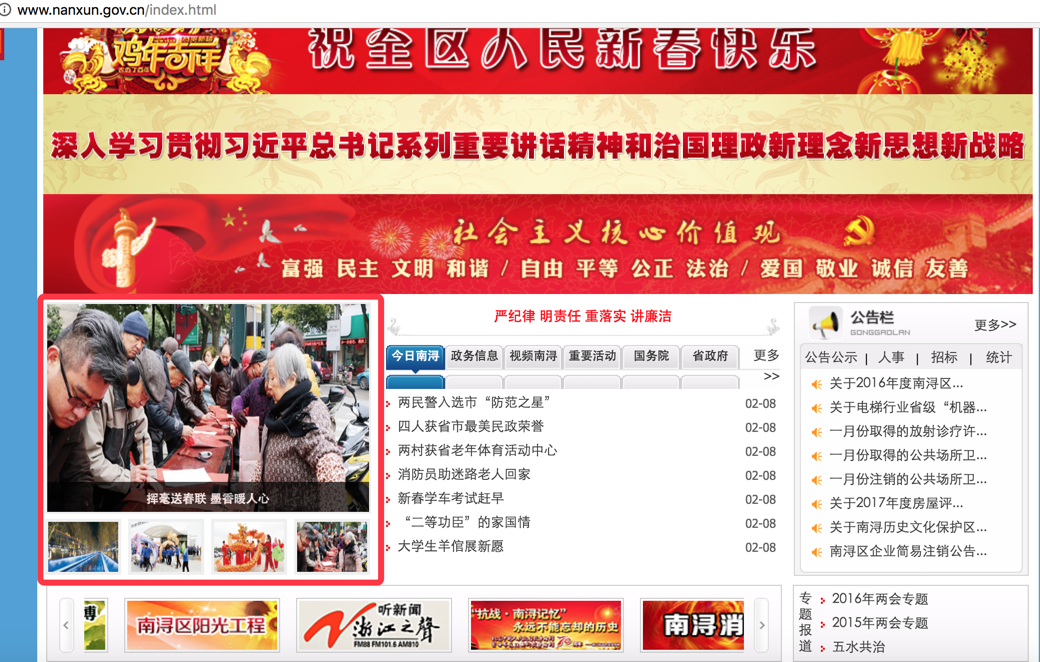
1. 首页轮播新闻抓取 如下图
首页查看该网页的源码 找到轮播图部分 如下
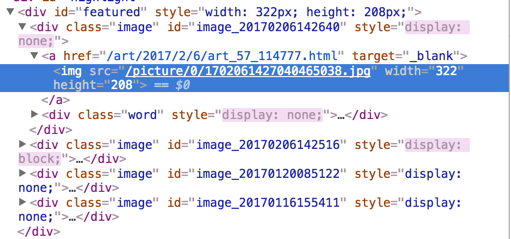
从代码结构入手 我们需要的是5张轮播图的 href 指向地址,指向具体的新闻详情页。
该部分java方法如下
public List<String> getImagesUrls(){
String url = "http://www.nanxun.gov.cn/";
String content = HttpKit.get(url);
Html html = new Html(content);
List<String> urls = html.$("#featured .image a", "href").all();
//List<String> images = html.$("#featured .image a img","src").all(); 所有图片
for(int i =0;i<urls.size();i++){
urls.set(i, urls.get(i).replaceAll("http://www.nanxun.gov.cn/","/"));
//System.out.println(urls.get(i));
}
return urls;
} String content = HttpKit.get(url);
Html html = new Html(content);
urls = html.$("#featured .image a", "href").all();
这里是根据外层div的id来定位拿到了5张轮播图的href属性。下一步就是根据href的链接地址来捉取指定url的新闻页详情。
public void getImagesNewsDetail(){
List<Map<String,String>> mapList = new ArrayList<Map<String,String>>();
List<String> imagesUrl = getImagesUrls();
try {
for(String url:imagesUrl){
Map<String, String> map = extractDetailPage(url);
mapList.add(map);
}
} catch (Exception e) {
e.printStackTrace();
}
renderJson(mapList);
}在上面方法调用 getImagesUrls() 拿到5个url, 循环来解析各个url对应的hmtl页面。 解析用到方法 extractDetailPage(String url),如下
/**
* 提取正文
* @para 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









