










这里没有按照顺序更新,首先是因为做过了很多题,但是回头看看有些题解还是忘了,写博客是为了回顾,并且当初做题的时候有些题目自己不是很懂,网上找的要么乱七八糟要么是纯英文或者纯代码,看起来很费劲,所以想自己整理一下,也帮助后来者少走一些弯路
这道题是自己实现一个数据结构:trie,字典树,或者叫前缀树,很重要,并且在非中文的信息检索中应用广泛,但是大学期间却没有讲过,更不要提实现,而且可能很多同学跟我一样,本科一直是用c的,c++的一些规范和面向对象的知识还有些陌生,所以这里先把这道题拿上来,学习一下字典树,顺便了解下c++的数据结构编程规范:
首先什么是字典树?
字典树就是一个树形结构,每一条从根到叶子的路径就是一个单词,比如:
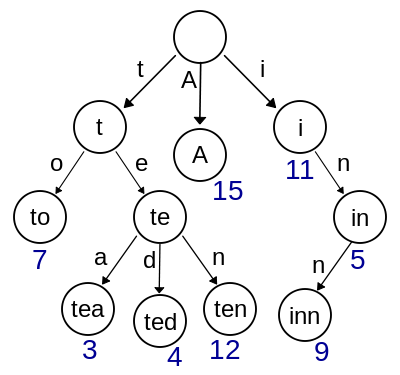
(图片来自维基百科)
在图片中我们可以明显发现,trie是把所有单词的公共前缀合并到了一条路径上,这也是它叫前缀树的原因
空间方面,由于英文单词前几个字母重复率非常高,所以在单词很多的情况下,大大降低了空间占用
时间方面,由于有公共前缀的单词都在一棵子树上,可以方便的顺着字母像查英文字典一样找到,所以在查找单词、求前缀、统计词频的方面非常高效,这也是叫字典树的原因
本博文主要是对leetcode题解的讨论,所以更多的trie相关知识可以额移步“真实的归宿”博主的博客Trie树:应用于统计和排序 或者google搜索相关内容
好了,有了上面的基础,我们来看这道题:
题干:
Implement a trie with insert, search, and startsWith methods.
Note:
You may assume that all inputs are consist of lowercase letters a-z.
Difficulty: Medium
分析:
题目简洁明了,构造trie树,并实现插入、搜索、前缀搜索三个成员函数
先贴上代码,然后我们一点点分析:
class TrieNode {
public:
TrieNode *next[26];
bool isWord;
// Initialize your data structure here.
TrieNode():isWord(false) {
memset(next, NULL, sizeof(next));
}
};
class Trie {
TrieNode *root;
public:
Trie() {
root = new TrieNode();
}
// Inserts a word into the trie.
void insert(string word) {
TrieNode *p = root;
for (auto &a : word) {
if (!p->next[a - 'a'])
p->next[a - 'a'] = new TrieNode();
p = p->next[a - 'a'];
}
p->isWord = true;
}
// Returns if the word is in the trie.
bool search(string word) {
TrieNode *p = find(word);
return p&&p->isWord;
}
// Returns if there is any word in the trie
// that starts with the given prefix.
bool startsWith(string prefix) {
if (find(prefix)) return true;
else return false;
}
private:
TrieNode* find(string key) {
TrieNode *p = root;
for (auto &a : key) {
if (p) p = p->next[a - 'a'];
else break;
}
return p;
}
};
// Your Trie object will be instantiated and called as such:
// Trie trie;
// trie.insert("somestring");
// trie.search("key");首先,构造trie树的类是这样的:
class TrieNode {
public:
TrieNode *next[26];
bool isWord;
// Initialize your data structure here.
TrieNode():isWord(false) {
memset(next, NULL, sizeof(next));
}
};习惯用c的同学比如我,一般建立数据结构时都是用:
typedef struct trie {
struct trie *next[26];
bool isword;
}Trie;这样的结构,c是面向过程的语言,c++增加了面向对象的部分,实际上根据类的定义,数据结构struct就是一个类,里面的成员变量就是类的对象TrieNode():isWord(false) { memset(next, NULL, sizeof(next)); } 这句是封装好的构造函数实现的就是在调用TrieNode() 函数时直接对isWord 和next[] 两个对象初始化,
isWord 是一个bool型变量,代表着从根到这个元素的路径构成的字符串是否是一个存在的单词
next[] 是一个指针数组,数组中的每一个元素都是一个指向下一个next[] 的指针
我们再来看Trie 这个类:
Trie() {
root = new TrieNode();
}成员函数 Trie()定义并初始化一个指向tire树根的指针root
void insert(string word) {
TrieNode *p = root;
for (auto &a : word) {
if (!p->next[a - 'a'])
p->next[a - 'a'] = new TrieNode();
p = p->next[a - 'a'];
}
p->isWord = true;
}成员函数insert()实现对trie的插入操作,其中if (!p->next[a - 'a']) p->next[a - 'a'] = new TrieNode(); 对刚接触trie的同学可能不太好理解,因为上面的trie树图片实际是一个抽象的结构,我们真正建立trie树的时候并不需要真的存储a~z这26个字母,因为next[] 这个数组的下标是0~25正好对应a~z 26个英文字母,所以真实的trie树结构是这样的:
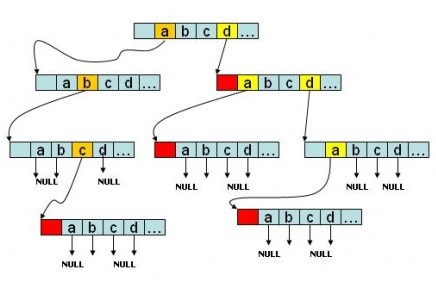
(图片来自“真实的归宿”博客,侵删)
变量a代表的是word字符串中每一个字符,a-‘a’代表啊的就是该字符串在next[] 中的下标,比如单词是bit,那么a-‘a’就是‘b’-‘a’ 就是1,也就是next[1] 代表着字母b,这跟我们的定义相符合
我们并没有存储a~z这26个字符,我们又如何判断字符是否存在呢?从图中我们可以观察到,对于存在的位置指针指向的肯定是下一个next[] 而不存在就是NULL,所以我们发现指针为空,就初始化该指针,知道word全部存储完毕
最后,讲结尾字符位置isWord = true代表根到这个字符的路径是一个单词
// Returns if the word is in the trie.
bool search(string word) {
TrieNode *p = find(word);
return p&&p->isWord;
}
// Returns if there is any word in the trie
// that starts with the given prefix.
bool startsWith(string prefix) {
if (find(prefix)) return true;
else return false;
}
private:
TrieNode* find(string key) {
TrieNode *p = root;
for (auto &a : key) {
if (p) p = p->next[a - 'a'];
else break;
}
return p;
}search()和startsWith()两个函数的功能相似,都是字符串的寻找,区别就是一个只匹配前缀,一个是查看是否是单词,我么可以用一个函数find()实现,finde()功能就是给定一个字符串,讲字符串中的字符在字典树种挨个匹配,直到匹配完成或者匹配失败,返回最后一个匹配成功的位置,我们可以发现:
(1)如果匹配到一半匹配失败,那么指针一定是指向NULL
(2)如果匹配到最后
①p->isWord == true 那么该单词存在
②p->isWord == false 那么该单词不存在
所以我们只要对返回的指针加以判断就可以用find()函数实现search()和startsWith()两个函数的功能
好了,这道题到这里就完成了,我在上面罗里吧嗦的说了很多,熟悉c++的同学肯定觉得都是废话,但是总有一些像我刚接触c++时一样的小白,根本看不懂每个语句的意思,所以希望这样细致的分析能对初学者有些帮助
最后:
trie树的应用远不止题里的这些,而且一个数据结构不是一成不变的,类中的成员变量是根据要求可以自由添加,这只是最基本的trie树实现,如果想马上试试trie树的应用,可以做下面这道题word search II















 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









