







mybatis
源码解析:

读取mybatis配置文件,注驱动--》加载mapper文件,有4中加载方式--》读取mapper文件,解析关键字,例如 select resultMap --》获取连接,sqlsession执行sql语句(如果有缓存,会先从缓存中获取数据),返回结果集ResultSet--》结果对象关系映射--》关闭连接
索引
索引使用某种数据结构来保存数据,从而提高查询效率。
二叉树;左小右大。
从理论上讲,二叉树查找速度和比较次数都是最小的,IO较大,树高
把1,2,3,4,5,6,7(排好序)已二叉树保存
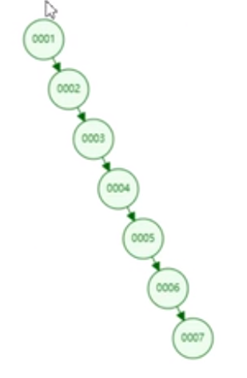

比如要查询,id位7的那个数据,二叉树减少了查询次数
红黑树:自平衡的二叉查找树,就是在二叉树的基础上,每次添加数据都会去按照性质去自平衡。
性质1:每个节点要么是黑色,要么是红色。
性质2:根节点是黑色。
性质4:每个红色结点的两个子结点一定都是黑色。

树高还是比较高。
B树:
IO次数就是树的高度,内存的比较速度非常快,耗时可以忽略,IO少,就可以提高查询性能,而“矮胖”就是b树的特征之一,它的每个节点最多包含m个孩子,m称为b树的阶,m的大小取决于磁盘页的大小。

B+树;

P1指针指向磁盘块4(保存了磁盘4里的数据),只有叶子节点存储数据。
Hash
Hash :散列,通过关于键值(key)的函数,将数据映射到内存存储中一个位置来访问。这个过程叫做Hash,这个映射函数称做散列函数,存放记录的数组称做散列表(Hash Table),又叫哈希表。JAVA函数hashCode()即请求对象的哈希值。

Key 数组 链表
当查找key=john,使用散列函数,查到哈希表(数组),然后找到对应的数据(链表)。
当使用散列函数,查的哈希值一样就会发生哈希碰撞,john和sandra就发生了哈希碰撞,他们的数据存在一个桶里面。
HashMap 先通过哈希运算,得到目标元素在哈希表中的值,然后再进行少量比较就可以得到元素。当哈希冲突时候,HashMap采用拉链法进行解决。HashMap 的底层实现是采用数组+链表,
jdk1.8之后当冲突元素达(链表元素)到8个后用红黑树。
链表过长,导致遍历查找过久,
当数组的存储个数大于初始容量*负载因子就会扩容,第一次扩容阀值是 12(16 * 0.75)。
通过扩容就可以一定程度的平衡哈希碰撞,数组变大了,当哈希碰撞就会使数组变链表。数组查询快于链表。平衡查找效率。
HashMap 的特点
- key 用 Set 存放,所以想做到 key 不允许重复,key对应的类需要重写 hashCode 和 equals 方法
- 元素是无序的,而且顺序会不定时改变
- 插入、获取的时间复杂度基本是 O(1)(前提是有适当的哈希函数,让元素分布在均匀的位置)
- 两个关键因子:初始容量(数组数量)负载因子(哈希表在其容量自动增加之前可以达到多满的一种饱和度百分比,其衡量了一个散列表的空间的使用程度)负载因子过大那么冲突的可能就会大
- HashMap 的添加、获取时需要通过 key 的 hashCode() 进行 hash(),然后计算下标 ( n-1 & hash),从而获得要找的同的位置。
- 当发生冲突(碰撞)时,利用 key.equals() 方法去链表或树中去查找对应的节点。
常用的存储引擎
- MyISAM(非聚集索引,key和数据是分开存储的)
节省数据库空间,当数据查询多时,可以使用该存储引擎,主键索引和辅助索引是独立的。 - InnoDB(聚集索引,key和数据一块存储)
保证有主键,主键索引快,一次就可以得到主键和数据。
非主键索引,第一次索引得到的是主键,第二次索引得到数据。
支持事务,如果数据修改较多时,可以使用该存储引擎。
InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限。这也是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;
索引类别:
普通索引,唯一索引,主键索引,组合索引,全文索引。
组合索引:最左原则,比如组合索引为name,age,postiton,. Select *from table where age =34 and postiton= manager.不会用到索引,因为name为组合索引的第一个,name,age,postiton必须从最左开始查,如果左边的没有,则不会使用索引。
使用explain,查看索引使用情况。
索引优化
查看是否开启慢查询日志功能:show variables like '%slow_query%';

#慢查询时间
SHOW VARIABLES LIKE 'long_query_time';
#慢查询的条数
SHOW STATUS LIKE 'slow_queries';
#记录慢查询的sql的位置
SHOW VARIABLES LIKE 'slow_query_log_file';
索引会会对增删改的执行减缓速度,所以,若是这张表增删改多而查询较少的话,就不要创建索引了。更新太频繁地字段不适合创建索引。
如果存储的数据重复度很低(也就是说基数很大),对该列数据以等值查询为主,没有范围查询、没有排序的时候,特别适合采用哈希索引
例如这种SQL:
SELECT … FROM t WHERE C1 = ?; — 仅等值查询在大多数场景下,都会有范围查询、排序、分组等查询特征,用B+树索引就可以了。















 2733
2733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









