







拟合模型的任务分解为两个关键问题
在深度学习中,我们“训练”模型,不断更新它们,使它们在看到越来越多的数据时变得越来越好。通常情况下,变得更好意味着最小化一个损失函数(loss function),即一个衡量“模型有多糟糕”这个问题的分数。最终,我们真正关心的是生成一个模型,它能够在从未见过的数据上表现良好。但“训练”模型只能将模型与我们实际能看到的数据相拟合。我们可以将拟合模型的任务分解为两个关键问题:
• 优化(optimization):用模型拟合观测数据的过程。
• 泛化(generalization):数学原理和实践者的智慧,能够指导我们生成出有效性超出用于训练的数据集本身的模型。
导数和微分
导数的计算,这是几乎所有深度学习优化算法的关键步骤。在深度学习中,我们通常选择对于模型参数可微的损失函数。简而言之,对于每个参数,如果我们把这个参数增加或减少一个无穷小的量,可以知道损失会以多快的速度增加或减少
假设我们有一个函数f : R → R,其输入和输出都是标量。如果f的导数存在,这个极限被定义为
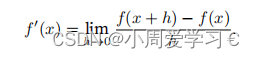
如果f′(a)存存在,则称f在a处是可微(differentiable)的。如果f在一个区间内的每个数上都是可微的,则此函数在此区间中是可微的。我们可以将 导数f′(x)解释为f(x)相对于x的(instantaneous)瞬时变化率。所谓的瞬时变化率是基于x中的变化h,且h接近0。
为了更好地解释导数,让我们做一个实验。定义u = f(x) = 5x^2 − 4x如下
def f(x):
return 5*x**2-4*x
def calculus(x,h):
return (f(x+h)-f(x))/h
h = 0.1
for i in range(5):
# 打印在x=1处,步长为h的近似导数
print(f"当h={h}时,近似导数为:{calculus(1,h)}")
# 减小步长h
h = h * 0.1
6.5000000000000036
6.050000000000021
6.004999999999148
6.00050000000074
6.000050000043442
可见当h越小,越精确
自动微分 梯度
求导是几乎所有深度学习优化算法的关键步骤。虽然求导的计算很简单,只需要一些基本的微积分。但对于复杂的模型,手工进行更新是一件很痛苦的事情(而且经常容易出错)。
深度学习框架通过自动计算导数,即自动微分(automatic differentiation)来加快求导。实际中,根据设计好的模型,系统会构建一个计算图(computational graph),来跟踪计算是哪些数据通过哪些操作组合起来产生输出。自动微分使系统能够随后反向传播梯度。这里,反向传播(backpropagate)意味着跟踪整个计算图,填充关于每个参数的偏导数。
import torch
# 创建一个一维张量x,包含从0到3的浮点数(包括0和3),步长为1
x = torch.arange(4.0)
# 使用就地操作设置x的requires_grad属性为True,这样PyTorch就会跟踪与x相关的所有操作
x.requires_grad_()
# 计算y,它是x与自身点积的2倍。这里,x是一个一维张量,所以torch.dot(x, x)计算的是x中所有元素的平方和
y = 2 * torch.dot(x, x)
# 调用y.backward()计算y关于x的梯度,并将结果存储在x.grad中
y.backward()
# 打印x的梯度,这将是2倍于x中每个元素的对应平方(因为y是x的平方和的2倍)
print(x.grad) # 输出应该是 tensor([0., 2., 4., 6.])
# 使用x.grad.zero_()将x的梯度归零,因为在后续的梯度计算中,PyTorch会累积梯度
x.grad.zero_()
# 重新定义一个操作y,它是x中所有元素的和
y = x.sum()
# 再次调用y.backward()计算新的y关于x的梯度,这次应该是全为1的向量(因为对每个元素求导都是1)
y.backward()
# 打印x的梯度,这次应该是全为1的向量
print(x.grad) # 输出应该是 tensor([1., 1., 1., 1.])
分离计算
有时,我们希望将某些计算移动到记录的计算图之外。例如,假设y是作为x的函数计算的,而z则是作为y和x的函数计算的。想象一下,我们想计算z关于x的梯度,但由于某种原因,希望将y视为一个常数,并且只考虑到x在y被计算后发挥的作用。这里可以分离y来返回一个新变量u,该变量与y具有相同的值,但丢弃计算图中如何计算y的任何信息。换句话说,梯度不会向后流经u到x。
因此,下面的反向传播函数计算z=ux关于x的偏导数,同时将u作为常数处理,而不是z=xx*x关于x的偏导数。
# 创建一个新的操作 y = x * x
y = x * x # y will be tensor([0., 1., 4., 9.])
# 使用detach()来阻止PyTorch跟踪u与x之间的计算图关系
# 这意味着当我们对u或u的后续操作进行反向传播时,它不会影响到x的梯度
u = y.detach() # u is now a tensor with the same data as y but detached from the graph
# 创建一个新的操作 z = u * x
z = u * x # z is a new tensor, but because of detach(), its gradient will not flow back to x
# 计算z的和,并对它进行反向传播
z.sum().backward() # Computes the gradient of the sum of z with respect to x
# 注意:这里打印x.grad == u是没有意义的,因为x.grad是一个梯度张量,而u是一个数据张量
# 我们不能直接比较它们是否相等。但我们可以检查x.grad的每个元素是否等于u的对应元素
print(x.grad == u) # 这将比较x的梯度张量和u张量,但结果是一个布尔张量
# 将x的梯度归零
x.grad.zero_()
# 对y进行求和,并对它进行反向传播
y.sum().backward() # Computes the gradient of the sum of y (which is x squared) with respect to x
# 打印x的梯度,这次应该是每个元素的2倍(因为y是x的平方)
print(x.grad) # 输出应该是 tensor([0., 2., 4., 6.])















 1528
1528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









