







这里先了解for xml path与for json path这两个语法:
for xml path与for json path
通俗一点的讲,将数据转化为XML格式与JSON格式;可能你不理解,咱就上图。
我先创建了临时表 #table
select * into #table
from (
select 1 as autoID, '32167542' as id, '张三' as name, '唱' as hobby
union
select 4 as autoID, '48978925' as id, '李四' as name, '跳' as hobby
union
select 7 as autoID, '32167542' as id, '张三' as name, 'rap' as hobby
union
select 11 as autoID, '48978925' as id, '李四' as name, '篮球' as hobby
union
select 13 as autoID, '48978925' as id, '李四' as name, '时长两年半' as hobby
)x
select * from #table for xml path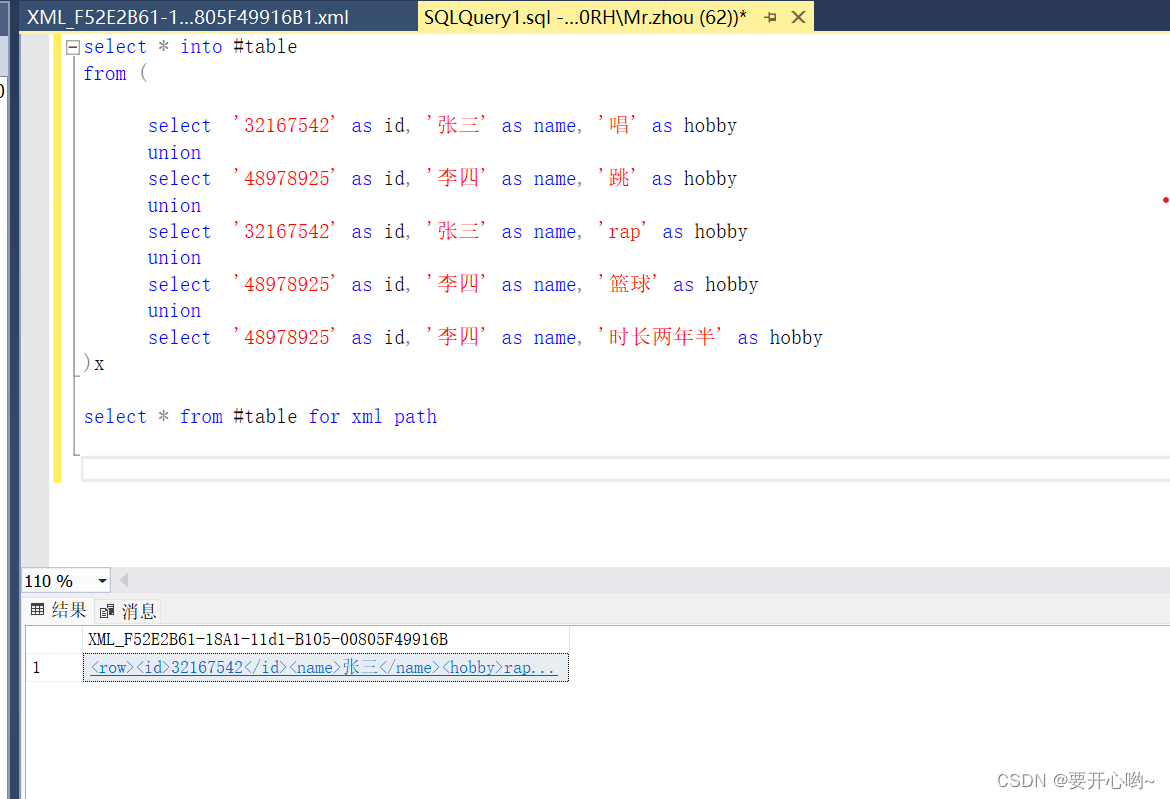
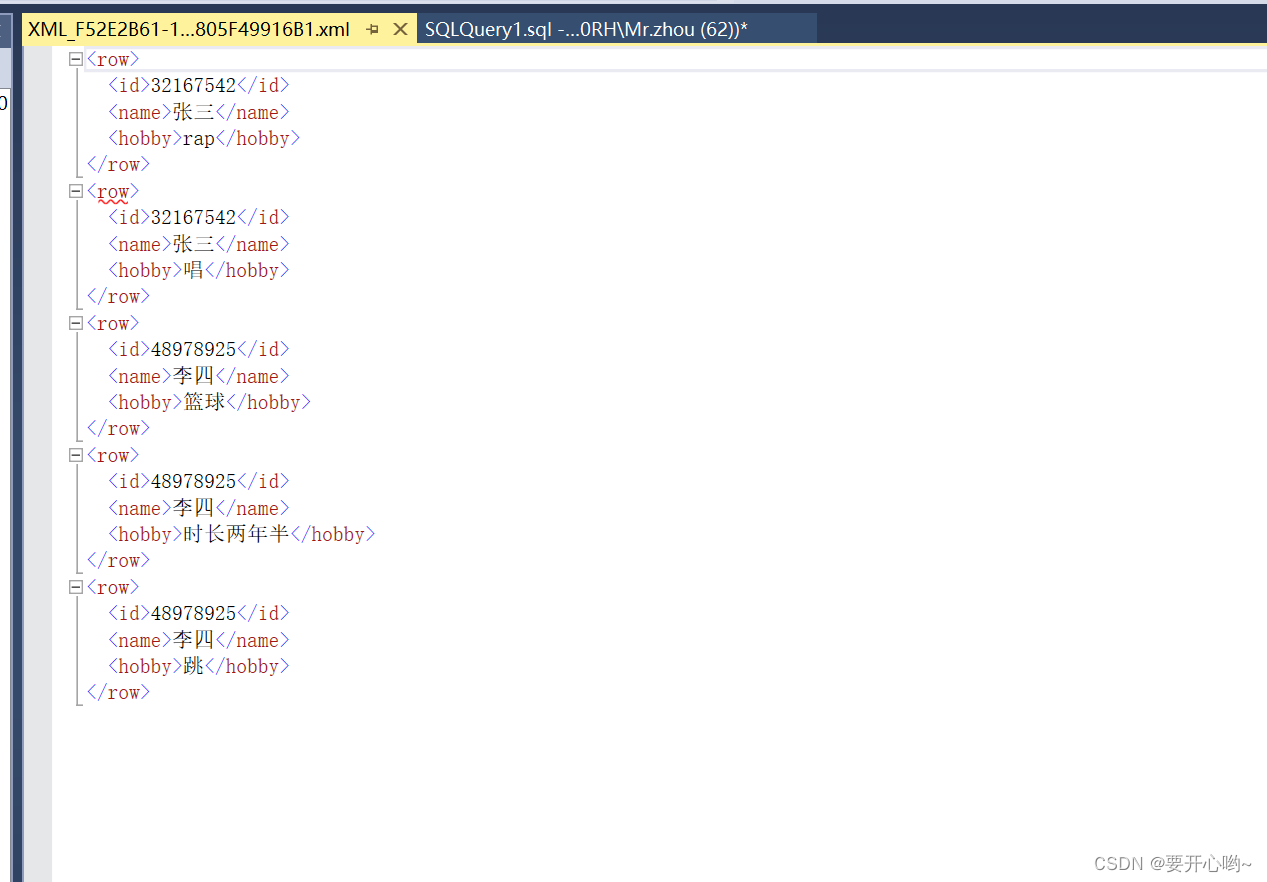
我们看到,转换成xml格式后,头标签为row,我们更改头标签的话就for xml path('标签名称'),不要头标签就for xml path(''),下面是结果
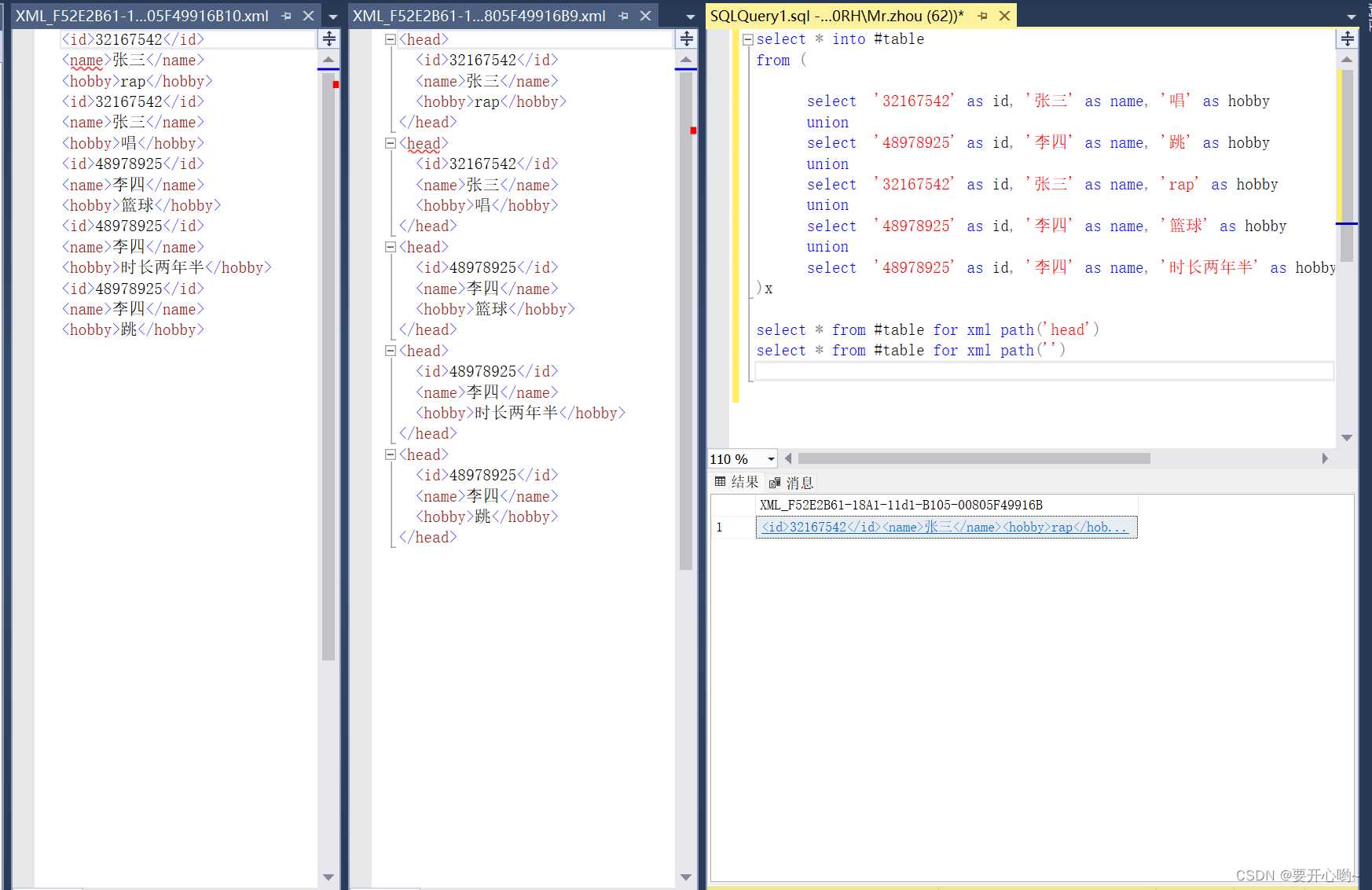
转json就用for json path,执行效果。
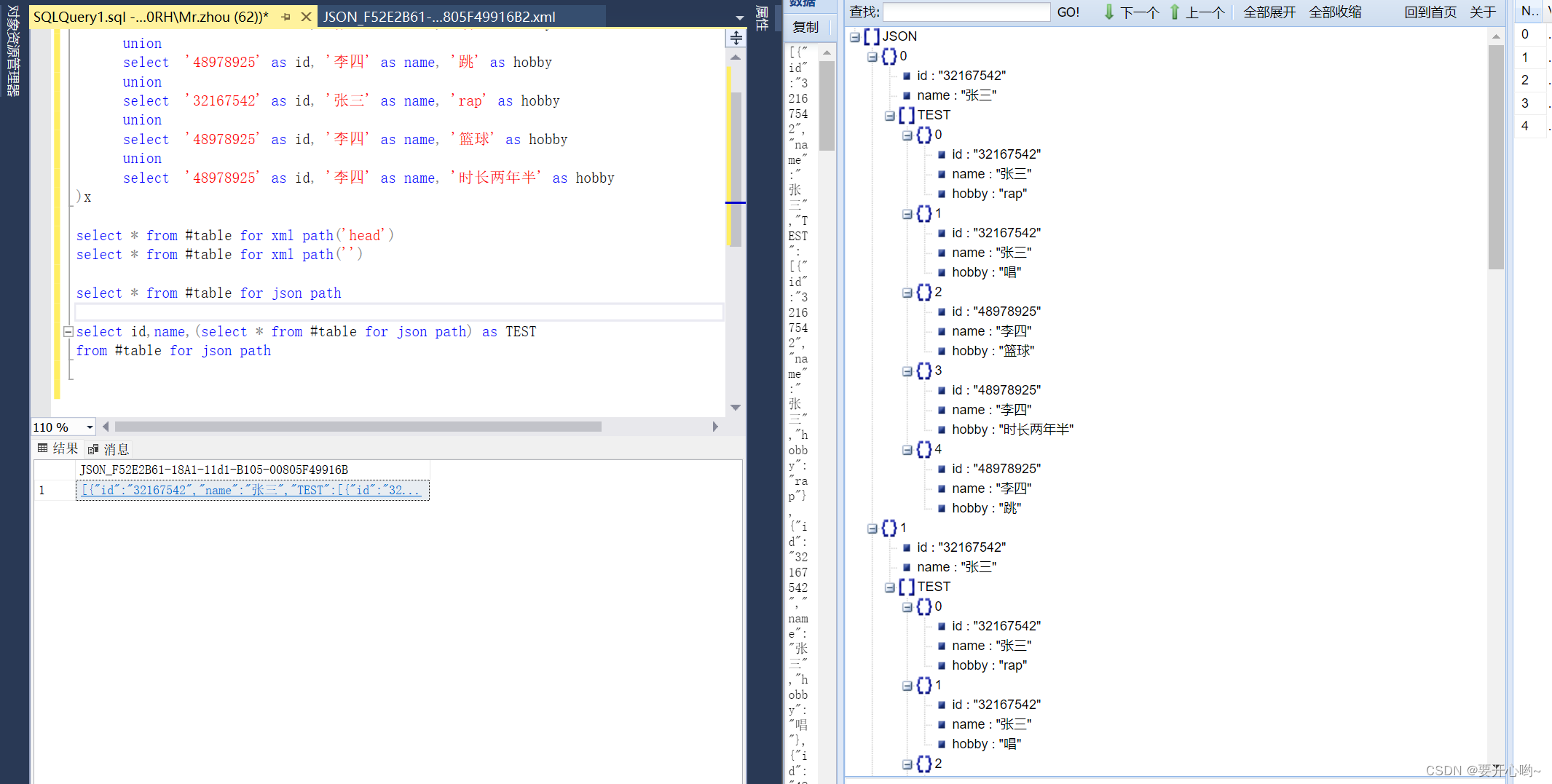
很强大有木有?有的扣1,没有的扣眼珠子。
好了,那要怎么才能把列数据用,分割呢?下面为大家实现。
select id,name,(select ','+hobby from #table for xml path('')) as hobby from #table
下面图片可以看到,hobby列已经用,分割好了
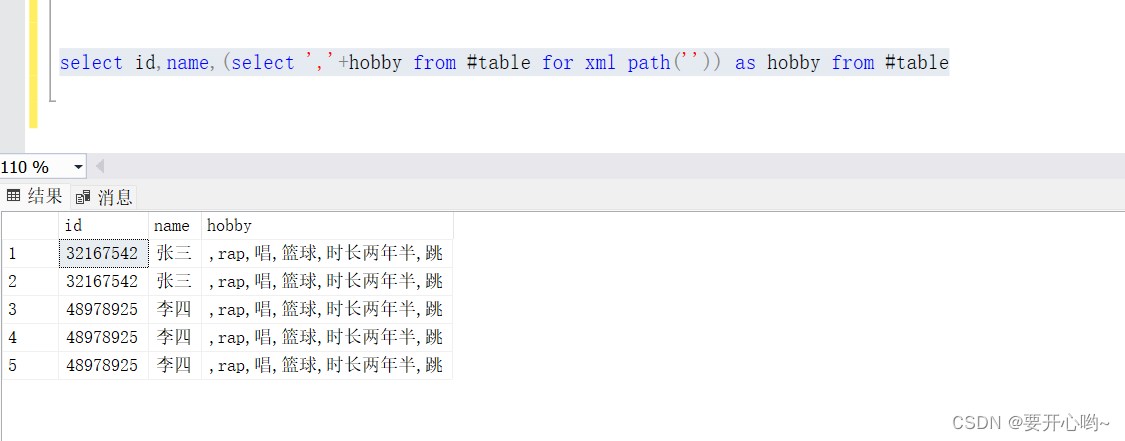
但是,张三和李四的爱好重复在一起了。哎,不是所有人都喜欢,唱,跳,rap,打篮球啊,所以,我们要让张三李四找到自己的爱好。就要进行下面操作。
select id,name,stuff((select ','+hobby from #table as a where a.id=b.id for xml path('')),1,1,'') as hobby
from #table as b
group by id,name
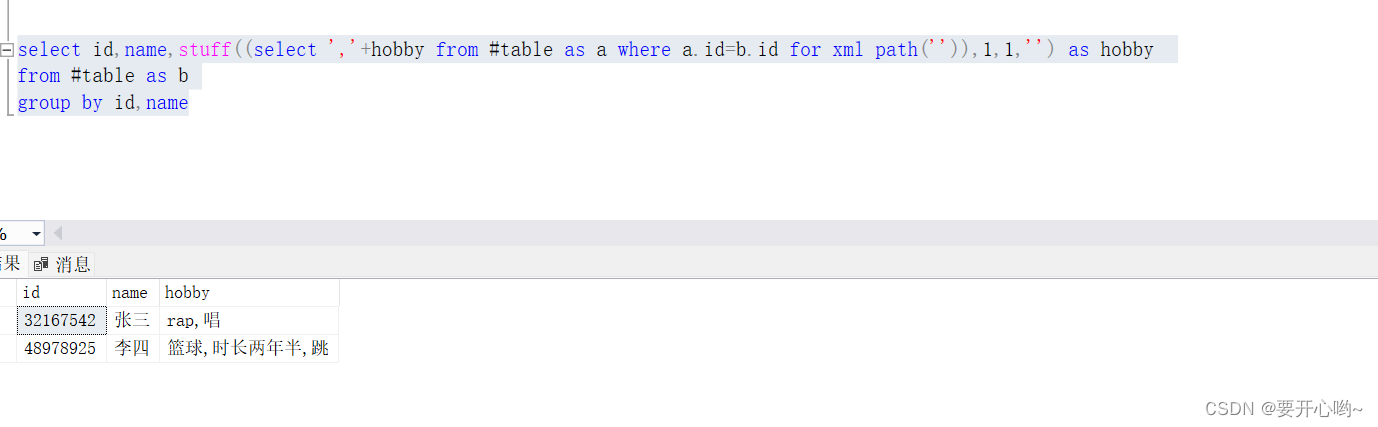
分好了,到此结束。

















 2294
2294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









