







本文将用python三方包 FastMCP 2.0 实战讲解mcp
推荐您阅读本系列第一篇,MCP原理,不要错过: MCP与通讯模式:理论与实战体验(1)
体验MCP(若已尝试可跳过)
体验MCP只需要导入配置即可,不需要开发
配置MCP
准备配置MCP了
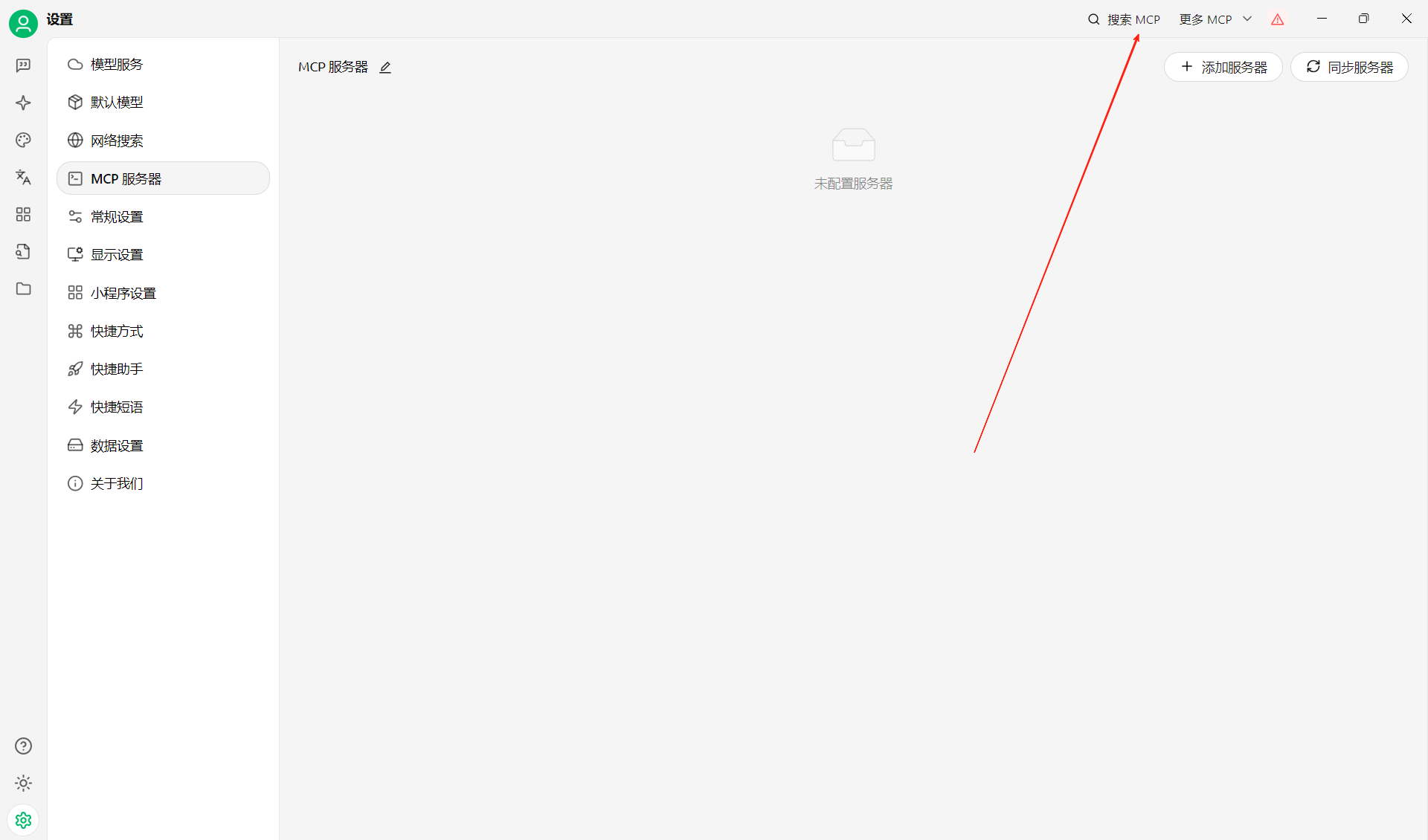
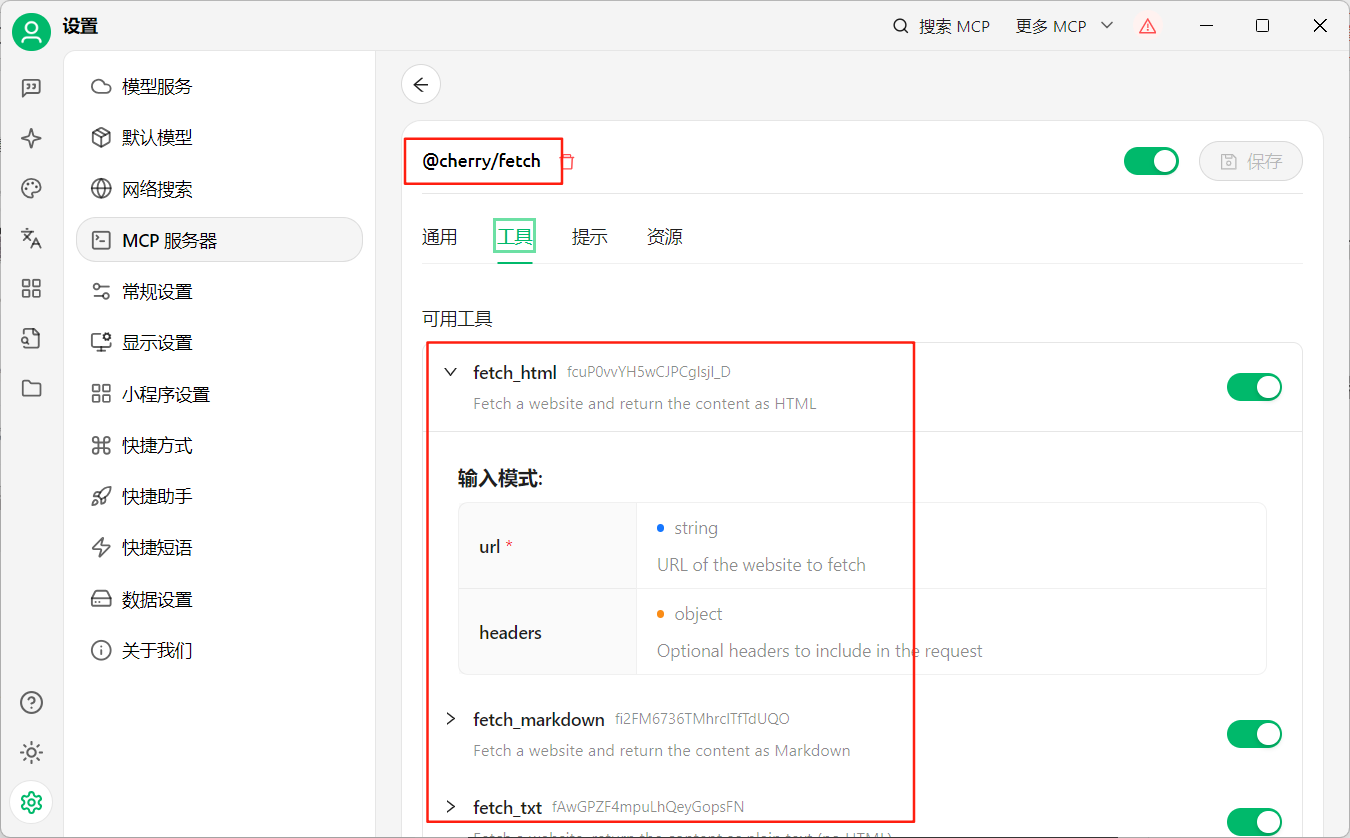
在内置广场选fetch,点击+安装,如下图
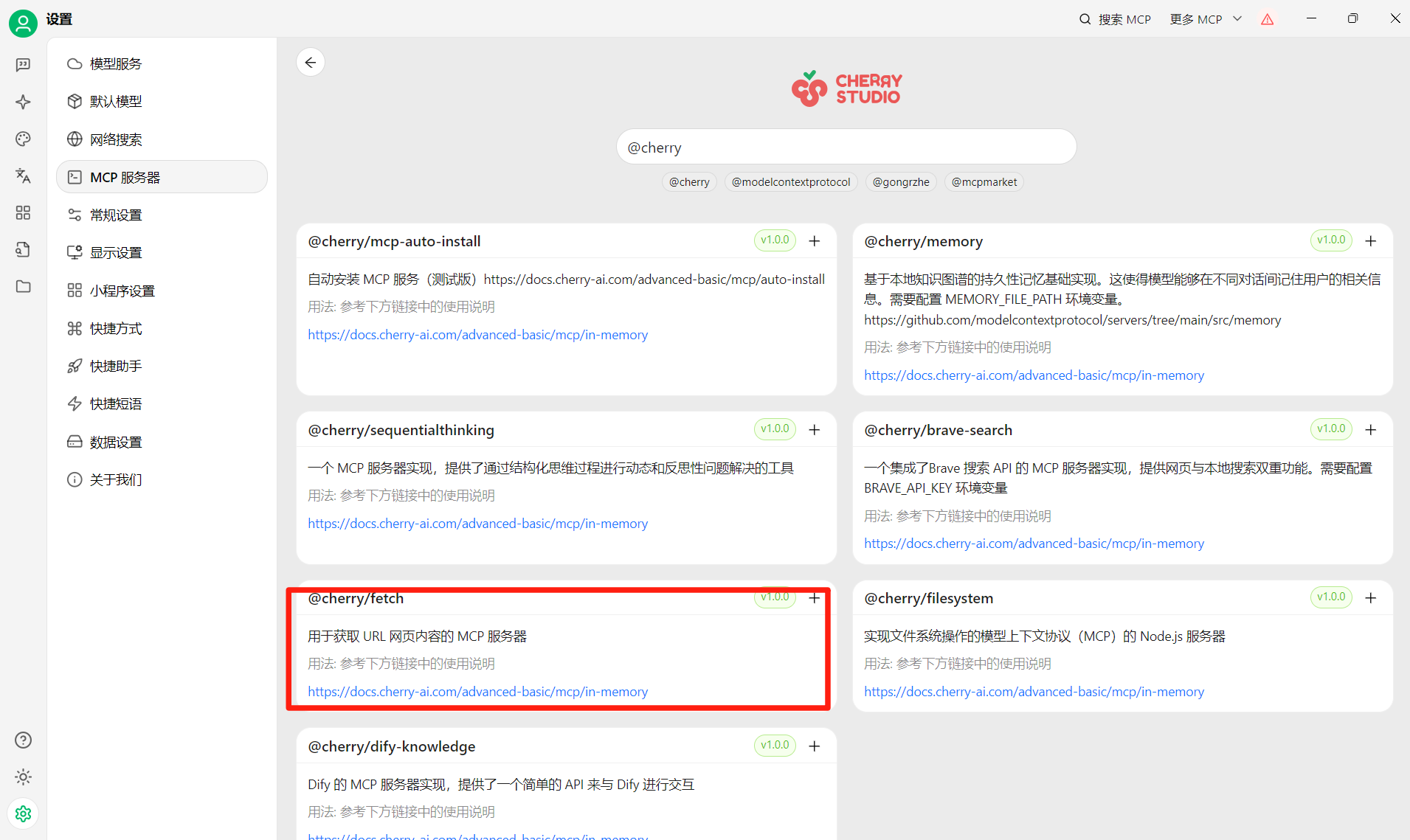
安装好了返回去会出现绿色电脑
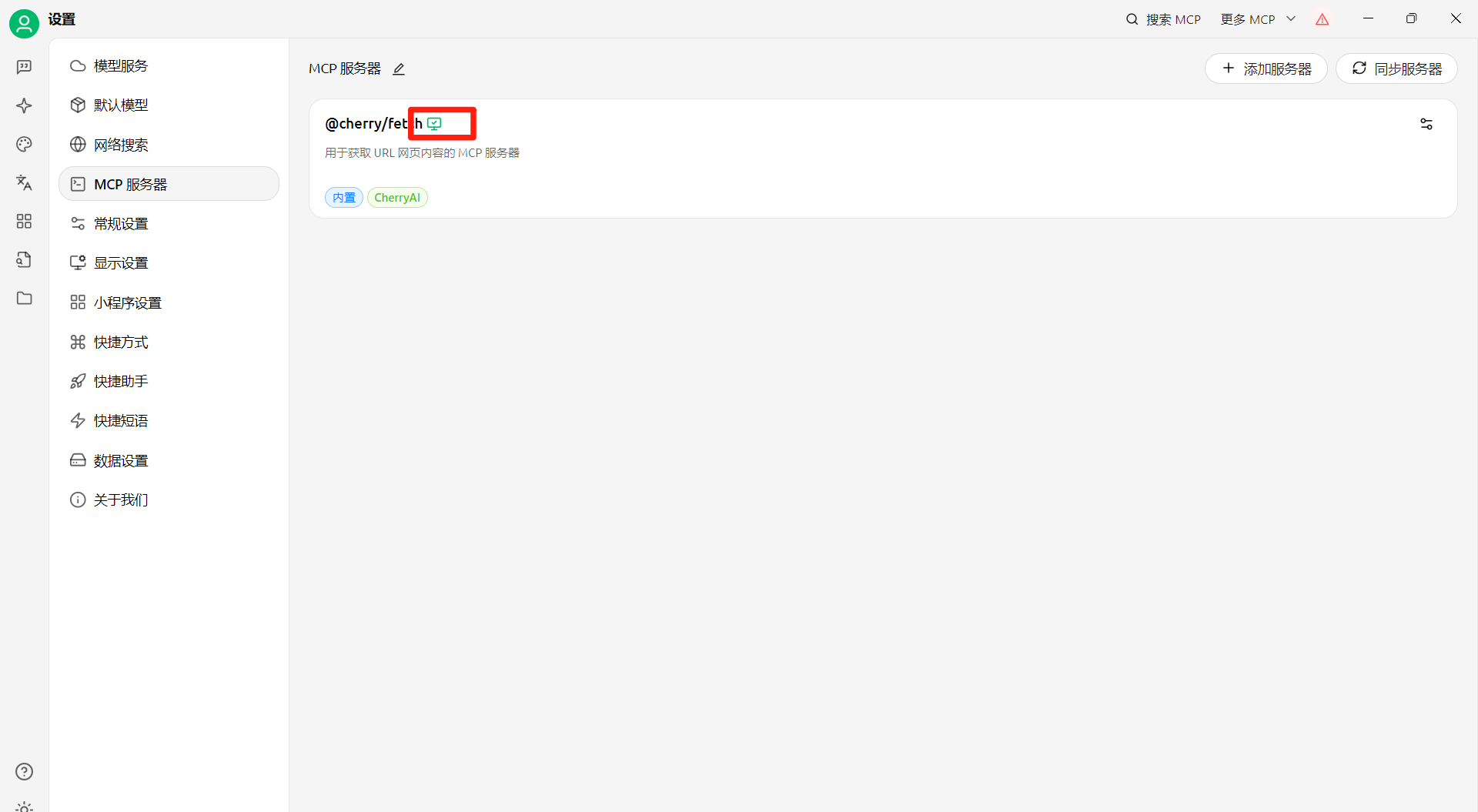
在聊天中使用
需要选中要不然用不了工具
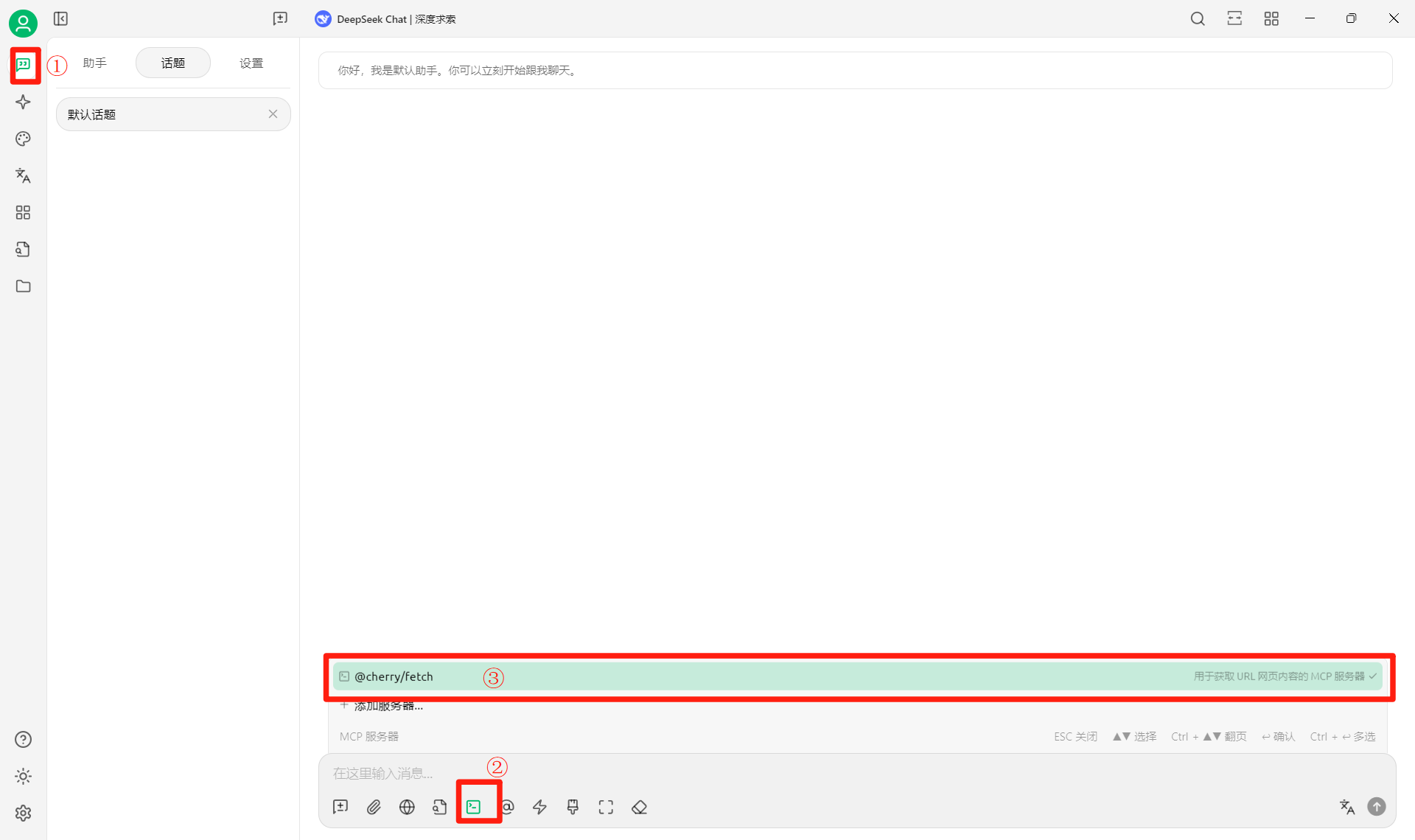
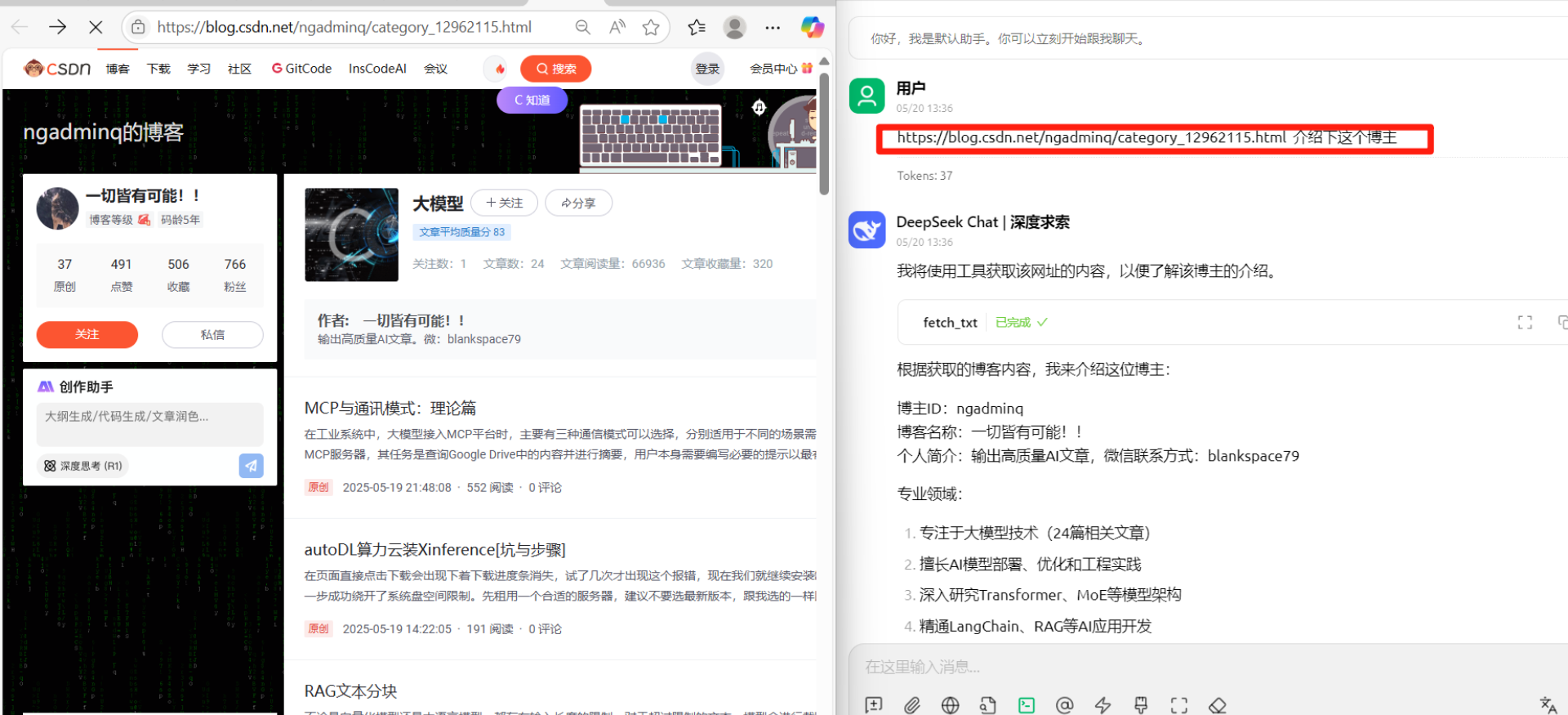
使用语句尝试
https://blog.csdn.net/ngadminq/category_12962115.html 介绍下这个博主
可以看到确实调用了工具,恭喜!
开发MCP服务器以及客户端
我们可以看到cherry的fetch实现了几个工具(可以理解为功能函数API接口),现在我们来实现其中一个工具:fetch_html
在开始实战前,让我们复习下MCP的基本术语,以便您可以顺利理解到以下实战:
- MCP (Model Context Protocol): 模型上下文协议,是一种标准化的通信协议,使AI模型能够更容易地与外部服务和数据源交互。
- MCP服务器: 暴露功能和数据的程序,可以被AI模型访问。
- MCP客户端: 能够访问MCP服务器的程序,通常是大模型或其宿主环境。
- 工具 (Tools): MCP中的可调用函数,用于执行特定任务如数据检索、信息搜索等。
- 传输层 (Transport Layer): MCP通信方式,主要有本地STDIO和远程传输(SSE或HTTP流)。
- FastMCP: 一个Python库,简化MCP服务器和工具的开发,让我们可以用装饰器轻松将函数转为MCP工具。
安装环境
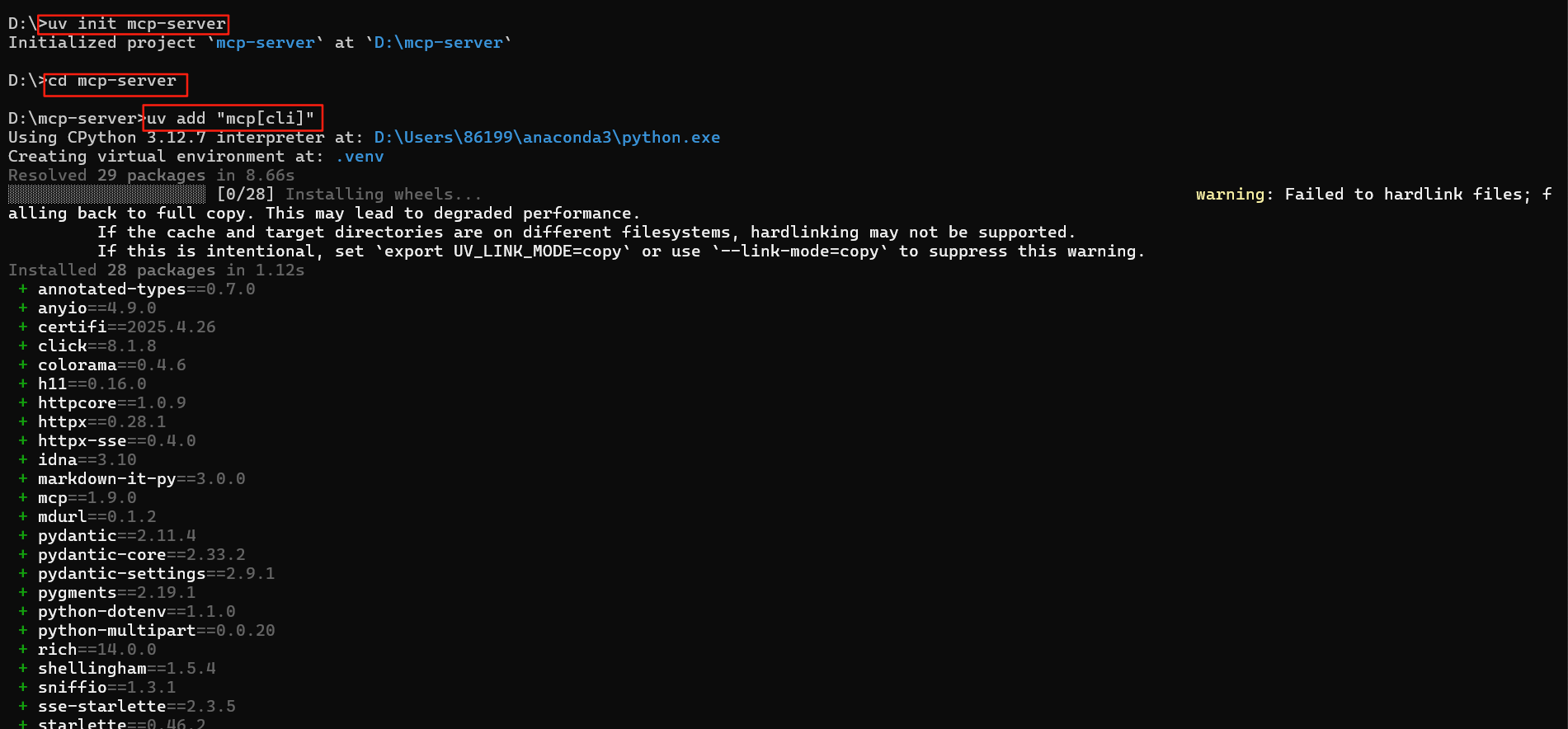
请先安装uv
pip install uv
使用以下命令
uv init mcp-server
cd mcp-server
uv add "mcp[cli]"
初始化环境
安装我们后续代码需要的三方包
.venv/Scripts/activate.bat
uv add BeautifulSoup4 requests langchain-deepseek langchain-mcp-adapters langgraph
开发tools
我们写个fetch_html函数,这里简化功能直接对网页的html提取所有文本,这段代码是测试功能的(您可以不尝试,后面会集成到正式代码)
import requests
from bs4 import BeautifulSoup
def fetch_html(url,headers= {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}):
"""
抓取指定 URL 的 HTML 文本内容
参数:
url (str): 要抓取的网页 URL
返回:
dict: 包含状态码、HTML 文本和提取的纯文本
"""
try:
# 发送 HTTP 请求
response = requests.get(url, headers=headers, timeout=10)
# 检查状态码
response.raise_for_status()
# 获取 HTML 内容
html_content = response.text
# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 提取纯文本 (去除 HTML 标签)
text_content = soup.get_text(separator='\n', strip=True)
return text_content
except requests.exceptions.RequestException as e:
return '抓取失败'
# 使用示例
if __name__ == "__main__":
url = "https://blog.csdn.net/ngadminq/category_12962115.html"
result = fetch_html(url)
print(result)
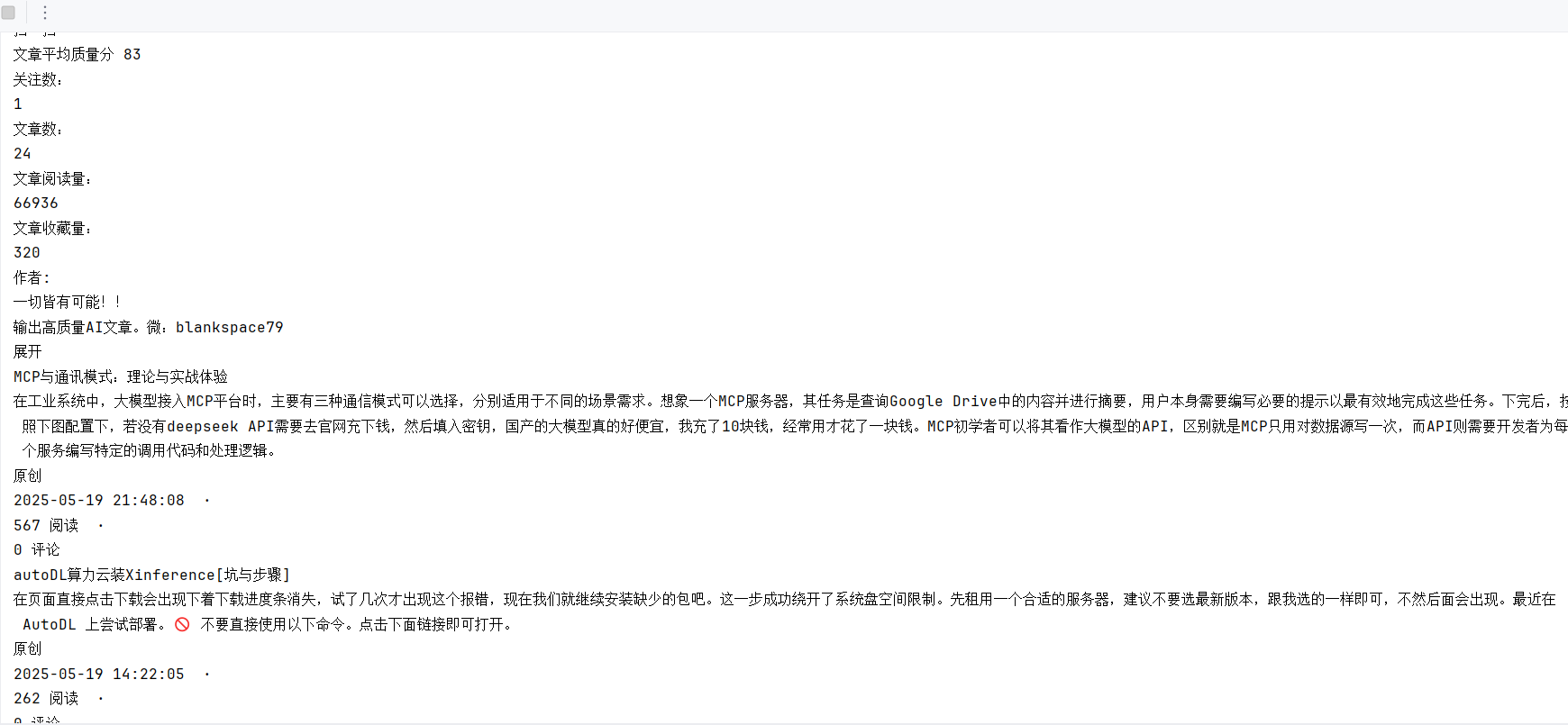
可以看到都是爬取我的博客相关信息
定义服务端
现在我们定义一个server.py代码,使用了fastmcp对我们的函数进行包装,即一个MCP服务。
from mcp.server.fastmcp import FastMCP
import requests
from bs4 import BeautifulSoup
mcp = FastMCP("MCPserver")
@mcp.tool()
def fetch_html(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}):
"""
抓取指定 URL 的 HTML 文本内容
参数:
url (str): 要抓取的网页 URL
返回:
dict: 包含状态码、HTML 文本和提取的纯文本
"""
try:
# 发送 HTTP 请求
response = requests.get(url, headers=headers, timeout=10)
# 检查状态码
response.raise_for_status()
# 获取 HTML 内容
html_content = response.text
# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 提取纯文本 (去除 HTML 标签)
text_content = soup.get_text(separator='\n', strip=True)
return text_content
except requests.exceptions.RequestException as e:
return '抓取失败'
if __name__ == '__main__':
mcp.run(transport='stdio')
定义客户端
这里我们设置了两个问题,第一个问题与AI闲聊,我们预期的是它不会调用工具。第二个问题我们期望它调用工具
import asyncio
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
from langchain.chat_models import init_chat_model
api_key = "X"
api_base = "https://api.deepseek.com/"
model = init_chat_model(
model="deepseek-chat",
api_key=api_key,
api_base=api_base,
temperature=0,
model_provider="deepseek",
)
server_params = StdioServerParameters(
command="python",
args=["server.py"],
)
async def run_agent(messages):
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# 初始化连接
await session.initialize()
# 通信
tools = await load_mcp_tools(session)
# 生成对话
agent = create_react_agent(model, tools)
agent_response = await agent.ainvoke({"messages": messages})
return agent_response
if __name__ == "__main__":
result = asyncio.run(run_agent("你是谁"))
print(result)
result = asyncio.run(run_agent("https://blog.csdn.net/ngadminq/category_12962115.html 介绍一下这个博主"))
print(result)
这是问题1,你是谁,不调用工具,符合期望√

问题2,访问链接介绍博主,调用工具,符合期望√
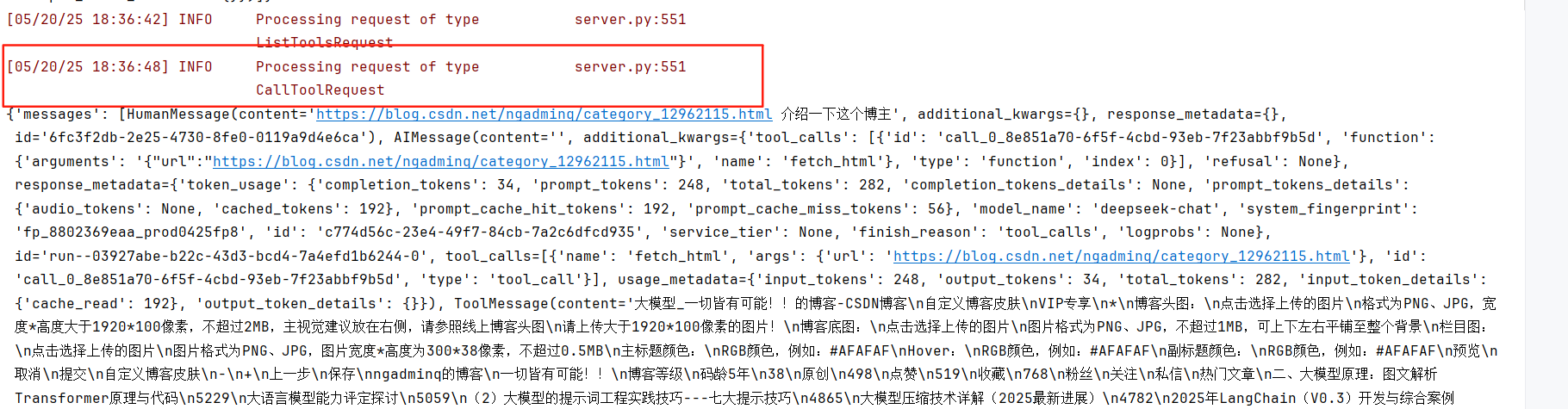
这是AI的回答,可以看到是工具调用后作为上下文的



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











