







最近在学习Hadoop的过程中,在网上看到很多关于如何在单机上搭建伪分布式模式Hadoop 的教程。发现大多教程都只给出了执行步骤,但是却很少解释这些步骤背后的原因。这让本来就是初学者的我产生了很多困惑。俗话说得好,学而不思则枉为人,在阅读各路牛人博客以及在窗台45度角仰望天空数小时之后,遂觉有所悟,分享如下。
首先解释一下什么是伪分布式模式。伪分布模式是指在单机环境下模拟Hadoop 集群,每一个hadoop daemon 都运行在独立的Java 进程里。
文中的步骤主要来源于 http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html#Pseudo-Distributed_Operation。
一、 安装Java
Hadoop 是由Java 编写的,所以Java 环境是Hadoop 运行的必要条件。可以从 http://wiki.apache.org/hadoop/HadoopJavaVersions 获取支持Hadoop 的JDK 版本。建议尽量不要通过 “sudo apt-get install”安装JDK,因为从Ubuntu 程序库中直接安装的是OpenJDK,而不是Oracle JDK。截至写本文为止,Hadoop官网上唯一测试过的OpenJDK版本为openjdk 1.7.0_09-icedtea,出于保险起见,还是推荐使用Oracle JDK。
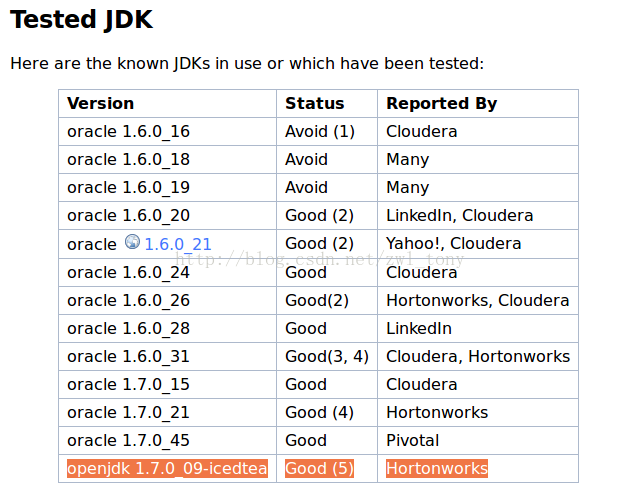
关于如何在Ubuntu 中安装JDK,可以参考网上博文,例如 http://www.cnblogs.com/bluestorm/archive/2012/05/10/2493592.html。
二、 安装Hadoop
- 访问http://www.apache.org/dyn/closer.cgi/hadoop/common/,获取最新Hadoop 版本。
- 下载hadoop 包至本地。

- $ sudo tar zxfv ~/Downloads/hadoop-2.6.0.tar.gz -C /usr/local
解压 hadoop 包到 /usr/local 路径下。
- $ sudo mv /usr/local/hadoop-2.6.0/ /usr/local/hadoop/
重命名 hadoop 根目录,这一步只是为了让路径更短一些。。
- 打开hadoop/conf/hadoop-env.sh文件,修改 JAVA_HOME 配置。Hadoop通过该项配置找到JDK 所在的路径。
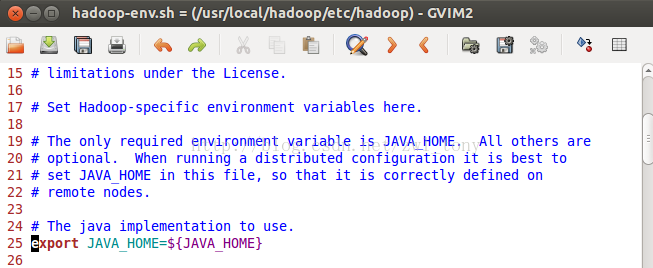
- 验证hadoop 是否安装成功
- $ cd /usr/local/hadoop
- $ bin/hadoop
运行以上命令,若看到以下 hadoop 命令行帮助信息,说明安装成功。
。
三、 安装SSH, 设置无密码登陆
SSH 全称是 Secure Shell,可以参考维基百科 http://zh.wikipedia.org/wiki/Secure_Shell 获取更多信息。
之所以需要安装SSH,是因为 Hadoop 中的 Namenode 需要通过 SSH 管理datanode 上的各个守护进程 (关于Namenode 和datanode 详情,请参考HDFS 相应教程)。为了避免每次启动Hadoop 的时候,都要输入 datanode 密码的麻烦,在安装SSH 后,需要进一步设置无密码登录。
- $ sudo apt-get install ssh
在Ubuntu 上安装SSH。
- $ sudo apt-get install rsync
安装 rsync。 rsync 是一款用来同步两个计算机文件与目录的应用软件,它利用差分编码以减少数据传输(详见http://zh.wikipedia.org/wiki/Rsync )。当Hadoop namenode 上的配置被改变时,需要使用 rsync 同步配置到所有节点上。
接下来就开始设置无密码登录。
- $ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
该命令用来生成 DSA 非对称密钥对。"-t dsa" 表示密钥类型为DSA, " -P '' " 表示不设密码, “-f ~/.ssh/id_dsa” 表示将密钥对生成在~/.ssh目录下并且以 id_dsa 命名。运行完该命令,在 ~/.ssh 目录下会生成两个新文件 id_dsa (私钥文件) 以及 id_dsa.pub (公钥文件)。

- $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
将 id_dsa.pub 公钥文件的内容写入 ~/.ssh/authorized_key 文件。
authorized_key文件用来在SSH 远程登陆时验证登陆用户的合法性。 在伪分布式模式的Hadoop集群中,localhost 即是client 又是Server。SSH 远程登陆时,作为client 的 localhost 将私钥 id_dsa 的内容发送到 作为server的localhost,作为server 的localhost 在远程登陆用户名 (本文中依然为 tonyz)home下的 .ssh 目录寻找 authorized_keys 文件,并验证私钥与 authorized_keys 中存储的公钥是否对应,最后根据验证结果判断是否让用户登陆。
ssh-add~/.ssh/id_dsa
将私钥加入ssh 搜索路径。否则,当你重新启动一个 Terminal,再进行 SSH 连接时会遇到如下问题:
Agent admitted failure to sign using the key.
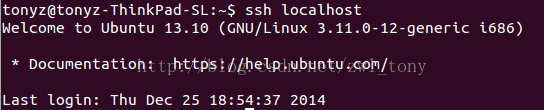
- $ ssh localhost
第一次运行该命令会遇到如下 warning:
The authenticity of host 'localhost (127.0.0.1)' can't be established.
选择 yes, localhost 会被加入 ~/.ssh/known_hosts 文件中。
ECDSA key fingerprint is 4f:26:10:82:3e:45:c6:a0:1b:d7:9e:86:ff:3c:20:35.
Are you sure you want to continue connecting (yes/no)?
若该命令返回如下结果,则说明 SSH 无密码登陆设置成功。
四、 设置 Hadoop 配置文件
假设 ${HADOOP_PREFIX} 是 Hadoop 安装的根目录。
- 设置 ${HADOOP_PREFIX}/etc/hadoop/core-site.xml
HDFS Daemon 通过 fs.defaultFS 属性来确定HDFS namenode 的主机及端口。这里将其设为 localhost 和 9000 端口。<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
- 设置 ${HADOOP_PREFIX}/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/tonyz/test_hadoop/dfs/name</value> </property> </configuration>dfs.replication 设置 HDFS 中文件块的副本数量。由于一个datanode 只能存储一个副本,所以在伪分布式模式中一定要将此值设为 1.
dfs.namenode.name.dir 设置 命名空间镜像文件 与 修改日志 的路径。其默认值为 file://${hadoop.tmp.dir}/dfs/name,这里我将其改为 /home/tonyz/test_hadoop/dfs/name。
五、 测试伪分布式 Hadoop 集群
- $ bin/hdfs namenode -format
格式化文件系统。该命令在 ${dfs.namenode.name.dir} 指定的路径下初始化 命名空间镜像文件(FSImage)、修改日志(Edit logs)等一系列文件。该命令执行完后,/home/tonyz/test_hadoop/dfs/name 内的文件如下:

- $ sbin/start-dfs.sh
启动 守护进程。该脚本详情可以参阅 http://www.cnblogs.com/hujunfei/p/3617964.html。
此步骤需要保证对 Hadoop 文件夹有写权限,否则会报 permission denied 错误。
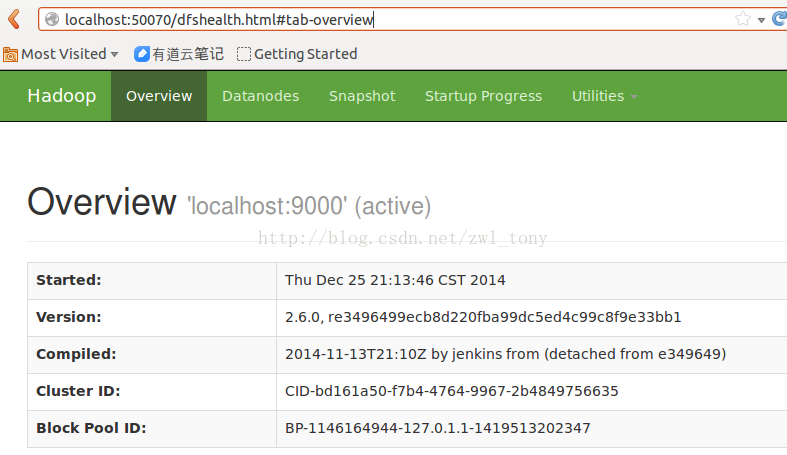
- 检查 namenode 是否可以访问。
通过浏览器访问 http://localhost:50070,是否可以加载如下页面。
下面运行一个MapReduce job 验证Hadoop 环境。
- 创建执行 MapReduce job 的目录,运行如下命令:
$ bin/hdfs dfs -mkdir /user $ bin/hdfs dfs -mkdir /user/tonyz
- 拷贝输入文件到分布式系统
$ bin/hdfs dfs -put etc/hadoop input
- 运行 MapReduce Job Sample
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep input output 'dfs[a-z.]+'
- 检查运行结果
$ bin/hdfs dfs -get output output $ cat output/*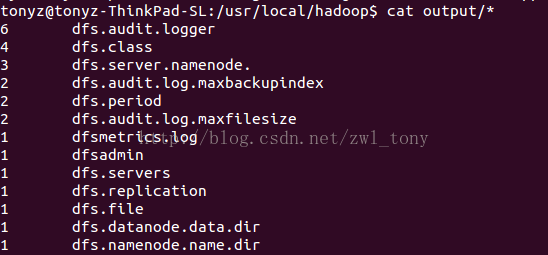
- 最后不要忘记关掉 守护进程
$ sbin/stop-dfs.sh















 522
522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









