







一 BERT简介
NLP:自然语言处理(NLP)是信息时代最重要的技术之一。理解复杂的语言也是人工智能的重要组成部分。Google AI 团队提出的预训练语言模型 BERT(Bidirectional Encoder Representations from Transformers)
BERT,全称是 Pre-training of Deep Bidirectional Transformers for Language Understanding。注意其中的每一个词都说明了 BERT 的一个特征。
- Pre-training 说明 BERT 是一个预训练模型,通过前期的大量语料的无监督训练,为下游任务学习大量的先验的语言、句法、词义等信息。
- Bidirectional 说明 BERT 采用的是双向语言模型的方式,能够更好的融合前后文的知识。
- Transformers 说明 BERT 采用 Transformers 作为特征抽取器。
在 11 项自然语言理解任务上刷新了最好指标,可以说是近年来 NLP 领域取得的最重大的进展之一。BERT 论文也斩获 NLP 领域顶会 NAACL 2019 的最佳论文奖,BERT 的成功也启发了大量的后续工作,不断刷新了 NLP 领域各个任务的最佳水平。有 NLP 学者宣称,属于 NLP 的 ImageNet 时代已经来临。
想象一下——你正在从事一个非常酷的数据科学项目,并且应用了最新的最先进的库来获得一个好的结果!几天后,一个新的最先进的框架出现了,它有可能进一步改进你的模型。
这不是一个假想的场景——这是在自然语言处理(NLP)领域工作的真正现实!过去的两年的突破是令人兴奋的。
谷歌的BERT就是这样一个NLP框架。我敢说它可能是近代最有影响力的一个(我们很快就会知道为什么)。
NLP常见的任务主要有:中文自动分词、句法分析、自动摘要、问答系统、文本分类、指代消解、情感分析等。
毫不夸张地说,BERT极大地改变了NLP的格局。想象一下,使用一个在大型未标记数据集上训练的单一模型,然后在11个单独的NLP任务上获得SOTA结果。所有这些任务都需要fine-tuning。BERT是我们设计NLP模型的一个结构性转变。
二 什么是BERT?
你可能大概听说过BERT,你看到过它是多么不可思议,它是如何潜在地改变了NLP的前景。但是BERT到底是什么呢?
BERT背后的研究团队是这样描述NLP框架的:
"BERT代表Transformers的双向编码器。它被设计为通过对左右的上下文的联合来预训练未标记文本得到深层的双向表示。因此,只需一个额外的输出层,就可以对预训练的BERT模型进行微调,从而为各种NLP任务创建SOTA结果。"
作为一开始,这听起来太复杂了。但是它确实总结了BERT的出色表现,因此让我们对其进行细分。
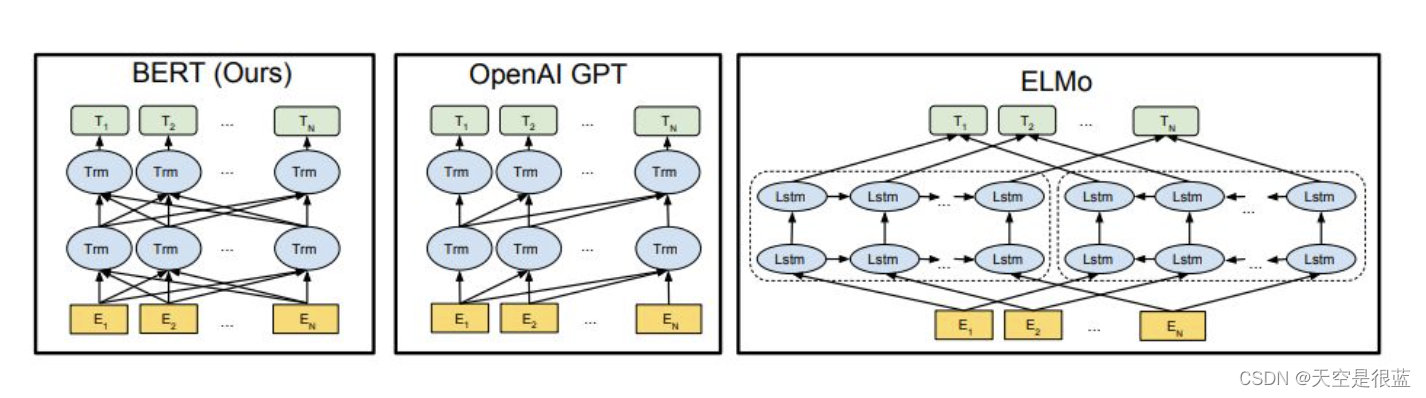
首先,很容易理解BERT是Transformers的双向编码器表示。这里的每个词都有其含义,我们将在本文中逐一讨论。这一行的关键是,BERT是基于Transformer架构的。
其次,BERT是在大量未标记文本的预训练,包括整个Wikipedia(有25亿个词!)和图书语料库(有8亿个单词)。
这个预训练步骤是BERT成功背后的一半。这是因为当我们在大型文本语料库上训练模型时,我们的模型开始获得对语言工作原理的更深入和深入的了解。这种知识几乎可用于所有NLP任务。
第三,BERT是"深度双向"模型。双向意味着BERT在训练阶段从目标词的左右两侧上下文来学习信息。
模型的双向性对于真正理解语言的意义很重要。让我们看一个例子来说明这一点。在此示例中,有两个句子,并且两个句子都包含单词"bank":
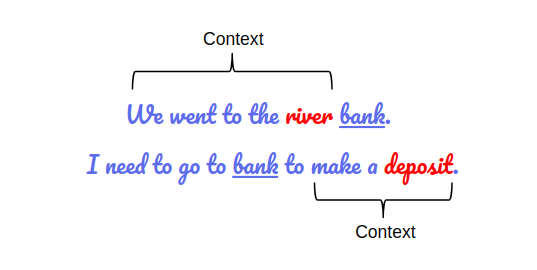
如果我们仅通过选择左侧或右侧上下文来预测"bank"一词的意义,那么在两个给定示例中至少有一个会出错。
解决此问题的一种方法是在进行预测之前考虑左右上下文。这正是BERT所做的!我们将在本文的后面看到如何实现这一目标。
最后,BERT最令人印象深刻的方面。我们可以通过仅添加几个其他输出层来微调它,以创建用于各种NLP任务的最新模型。
三 从Word2Vec到BERT
NLP的学习语言表示的探索
"自然语言处理中的最大挑战之一是训练数据的短缺。由于NLP是一个具有许多不同任务的多元化领域,因此大多数特定于任务的数据集仅包含数千或数十万个人标记的训练示例。" – Google AI
Word2Vec和GloVe
通过在大型未标记文本数据上进行预训练模型来学习语言表示的要求始于诸如Word2Vec和GloVe之类的Word Embedding。这些Embedding改变了我们执行NLP任务的方式。现在,我们有了Embedding,可以捕获单词之间的上下文关系。
这些Embedding被用来训练下游NLP任务的模型,并做出更好的预测。这可以通过利用来自Embedding本身的附加信息,甚至使用较少的特定于任务的数据来完成。
这些Embedding的一个限制是使用非常浅的语言模型。这意味着他们能够获取的信息的数量是有限的,这促使他们使用更深入、更复杂的语言模型(LSTMs和GRUs层)。
另一个关键的限制是,这些模型没有考虑单词的上下文。让我们以上面的“bank”为例。同一个单词在不同的上下文中有不同的意思。然而,像Word2Vec这样的Embedding将在这两个上下文中为“bank”提供相同的Word Embedding。
这是导致模型不准确的一个因素。
ELMO和ULMFiT
ELMo是NLP社区对一词多义问题的回应——相同的词在不同的语境中有不同的含义。从训练浅层前馈网络(Word2vec),逐步过渡到使用复杂的双向LSTM体系结构的层来训练Word Embedding。这意味着同一个单词可以根据它所在的上下文有多个ELMO Embedding。
那是我们开始看到预训练作为NLP的训练机制的优势。
ULMFiT则更进一步。这个框架可以训练语言模型,这些模型可以进行微调,从而在各种文档分类任务中,即使使用更少的数据(少于100个示例)也可以提供出色的结果。可以肯定地说,ULMFiT破解了NLP中迁移学习的密码。
这就是我们在NLP中建立迁移学习黄金法则的时候:
NLP中的迁移学习 =预训练和微调
ULMFIT之后的大多数NLP的突破调整了上述等式的组成部分,并获得了最先进的基准。
OpenAI的GPT
OpenAI的GPT扩展了ULMFiT和ELMo引入的预训练和微调方法。GPT本质上用基于转换的体系结构取代了基于LSTM的语言建模体系结构。
GPT模型可以微调到文档分类之外的多个NLP任务,如常识推理、语义相似性和阅读理解。
GPT还强调了Transformer框架的重要性,它具有更简单的体系结构,并且比基于LSTM的模型训练得更快。它还能够通过使用注意力机制来学习数据中的复杂模式。
OpenAI的GPT通过实现多个最先进的技术,验证了Transformer架构的健壮性和有用性。
这就是Transformer如何启发了BERT以及接下来在NLP领域的所有突破。
现在,还有一些其他的重要突破和研究成果我们还没有提到,比如半监督序列学习。这是因为它们稍微超出了本文的范围,但是你可以阅读相关的论文来了解更多信息。
BERT
因此,解决NLP任务的新方法变成了一个2步过程:
- 在大型无标签文本语料库(无监督或半监督)上训练语言模型
- 将这个大型模型微调到特定的NLP任务,以利用这个大型知识库训练模型(监督)
在这样的背景下,让我们来理解BERT是如何从这里开始建立一个模型,这个模型将在很长一段时间内成为NLP中优秀的基准。
四 BERT如何工作?
让我们仔细看一下BERT,了解为什么它是一种有效的语言建模方法。我们已经知道BERT可以做什么,但是它是如何做到的?我们将在本节中回答这个相关问题。
bert从这几方面做了改进:
- Masked LM
- NSP Multi-task Learning
- Encoder again
bert为什么更好呢?
- 单向信息流的问题 ,只能看前面,不能看后面,其实预料里有后面的信息,只是训练语言模型任务特殊要求只能看后面的信息,这是最大的一个问题
- 其次是pretrain 和finetuning 几个句子不匹配
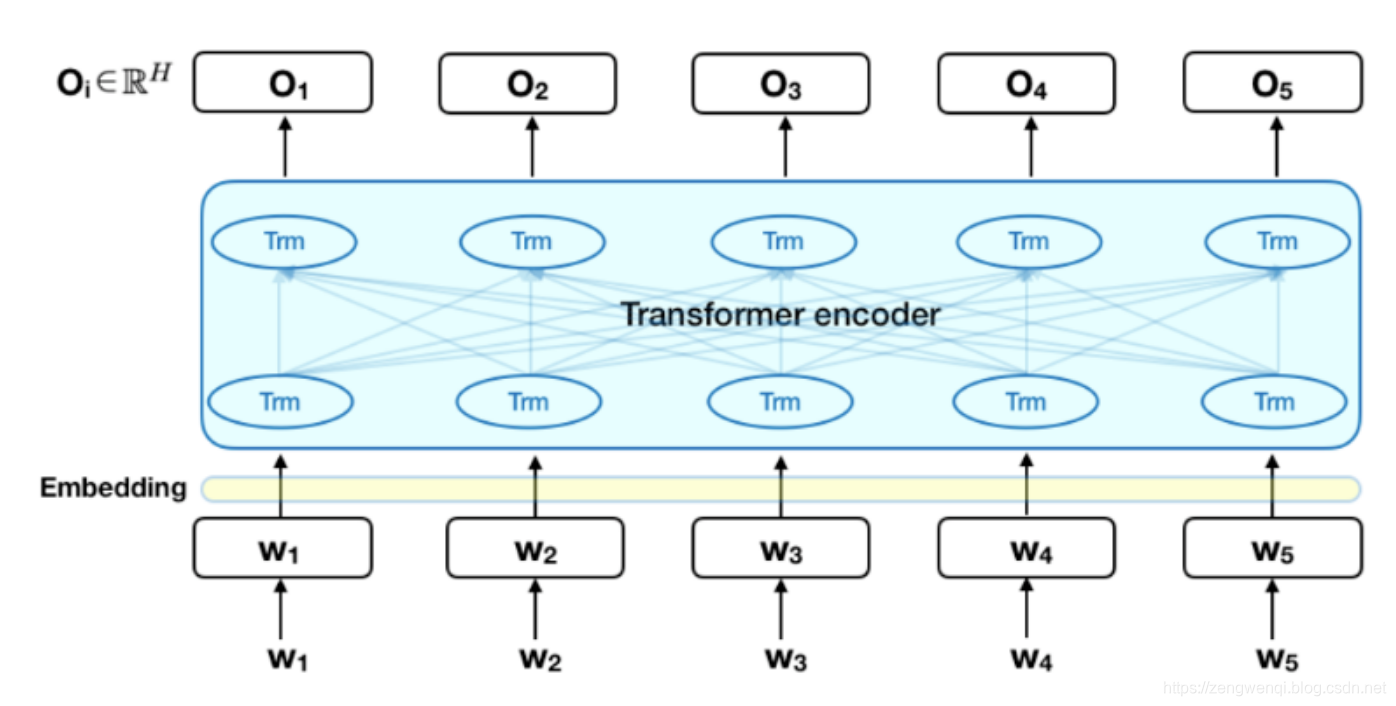
1. BERT的体系结构
下图是 Transformer 的 encoder 部分,输入是一个 token 序列,先对其进行 embedding 称为向量,然后输入给神经网络,输出是大小为 的向量序列,每个向量对应着具有相同索引的 token。
BERT架构建立在Transformer之上。我们目前有两个可用的版本:
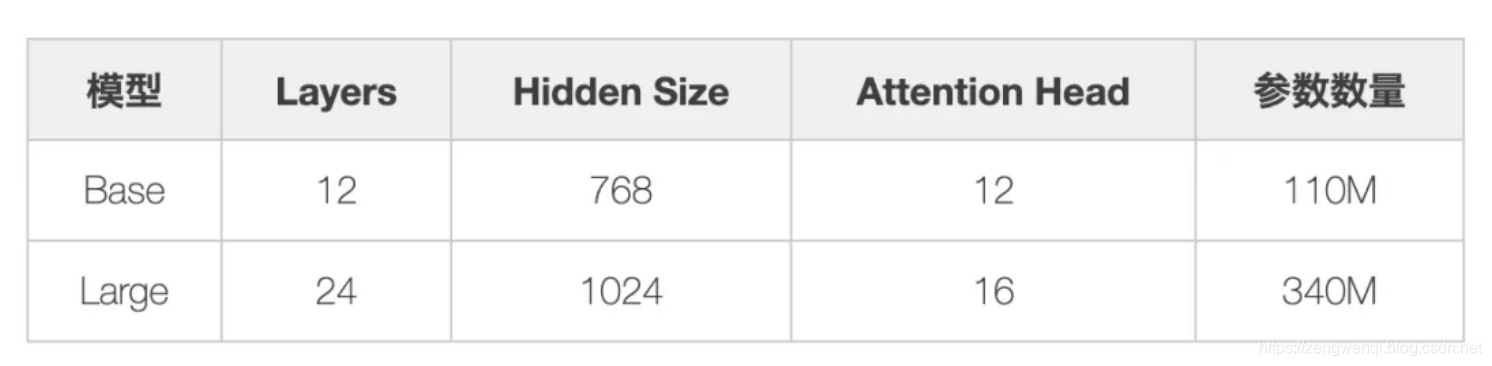
- BERT Base:12层transformer,12个attention heads和1.1亿个参数
- BERT Large:24层transformer,16个attention heads和3.4亿个参数
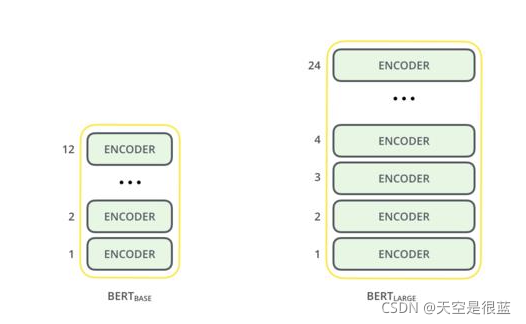
Bert base的网络结构: L(网络层数)=12, H(隐藏层维度)=768, A(Attention 多头个数)=12, Total Parameters= 12*768*12=110M 使用GPU内存:7G多
Bert large的网络结构 (L=24, H=1024, A=16, Total Parameters=340M). 使用GPU内存:32G多

出于比较的目的,BERT Base架构具有与OpenAI的GPT相同的模型大小。所有这些Transformer层都是只使用Transformer的编码器。
现在我们已经了解了BERT的总体架构,接下来让我们看看在进入模型构建阶段之前需要哪些文本处理步骤。
2.文本预处理
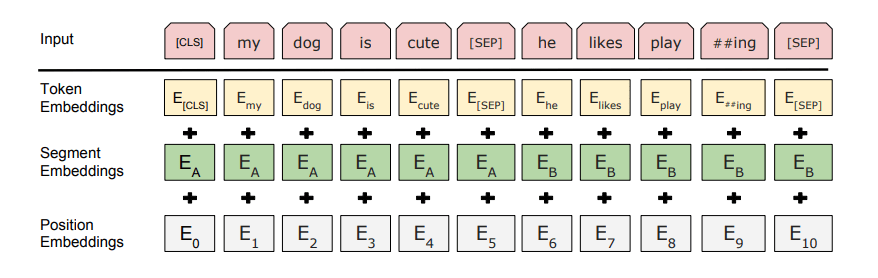
BERT背后的开发人员已经添加了一组特定规则来表示模型的输入文本。其中许多是创造性的设计选择,目的是使模型更好。
- 对于英文模型,使用了 Wordpiece 模型来产生 Subword 从而减小词表规模;对于中文模型,直接训练基于字的模型。
- 模型输入需要附加一个起始 Token,记为 [CLS],对应最终的 Hidden State(即 Transformer 的输出)可以用来表征整个句子,用于下游的分类任务。
- 模型能够处理句间关系。为区别两个句子,用一个特殊标记符 [SEP] 进行分隔,另外针对不同的句子,将学习到的 Segment Embeddings 加到每个 Token 的 Embedding 上。
- 对于单句输入,只有一种 Segment Embedding;对于句对输入,会有两种 Segment Embedding。
对于初学者,每个输入的Embedding是3个嵌入的组合:
- 位置嵌入(Position Embeddings):BERT学习并使用位置嵌入来表达句子中单词的位置。这些是为了克服Transformer的限制而添加的,Transformer与RNN不同,它不能捕获“序列”或“顺序”信息
- 段嵌入(Segment Embeddings):BERT还可以将句子对作为任务的输入(可用于问答)。这就是为什么它学习第一和第二句话的独特嵌入,以帮助模型区分它们。在上面的例子中,所有标记为EA的标记都属于句子A(对于EB也是一样)
- 目标词嵌入(Token Embeddings):这些是从WordPiece词汇表中对特定词汇学习到的嵌入
对于给定的目标词,其输入表示是通过对相应的目标词、段和位置的Embedding进行求和来构造的。
这样一个综合的Embedding方案包含了很多对模型有用的信息。
这些预处理步骤的组合使BERT如此多才多艺。这意味着,不需要对模型的体系结构进行任何重大更改,我们就可以轻松地对它进行多种NLP任务的训练。
3.预训练任务
BERT已接受两项NLP任务的预训练:
- 屏蔽语言建模 Masked Language Model
- 下一句预测 Next Sentence Prediction
让我们更详细地了解这两个任务!
1. Masked Language Model(MLM)
A. 双向性
BERT被设计成一个深度双向模型。网络有效地从第一层本身一直到最后一层捕获来自目标词的左右上下文的信息。
传统上,我们要么训练语言模型预测句子中的下一个单词(GPT中使用的从右到左的上下文),要么训练语言模型预测从左到右的上下文。这使得我们的模型容易由于信息丢失而产生错误。
ELMo试图通过在左到右和从右到左的上下文中训练两个LSTM语言模型并对其进行浅级连接来解决此问题。即使它在现有技术上有了很大的改进,但这还不够。
"凭直觉,我们有理由相信,深层双向模型比左向右模型或从左至右和从右至左模型的浅级连接严格更强大。" – BERT
这就是BERT在GPT和ELMo上都大大改进的地方。看下图:
![]()
箭头指示从一层到下一层的信息流。顶部的绿色框表示每个输入单词的最终上下文表示。
从上图可以明显看出:BERT是双向的,GPT是单向的(信息仅从左向右流动),而ELMO是浅双向的。
B. 屏蔽语言模型
假设我们有一句话——“我喜欢阅读关于分析数据科学的博客”。我们想要训练一个双向的语言模型。与其试图预测序列中的下一个单词,不如构建一个模型,从序列本身预测缺失的单词。
让我们把“分析”替换成“[MASK]”。这是表示被屏蔽的单词。然后,我们将以这样一种方式训练该模型,使它能够预测“分析”这个词语,所以句子变为:“我喜欢阅读关于[MASK]数据科学的博客”
这是掩蔽语言模型的关键所在。BERT的作者还提出了一些注意事项,以进一步改进这项技术:
- 为了防止模型过于关注一个特定的位置或被掩盖的标记,研究人员随机掩盖了15%的单词
- 掩码字并不总是被掩码令牌[掩码]替换,因为[掩码]令牌在调优期间不会出现
训练过程大量看到 [MASK] 标记,但是真正后面用的时候是不会有这个标记的,这会引导模型认为输出是针对 [MASK] 这个标记的,但是实际使用又见不到这个标记。
因此,研究人员采用了以下方法:
- 80%的情况下,单词被替换成带Mask的令牌[Mask] my dog is hairy → my dog is [MASK]
- 10%的情况下,这些单词被随机替换 my dog is hairy -> my dog is apple
- 有10%的时间单词是保持不变的 my dog is hairy -> my dog is hairy
那么为啥要以一定的概率使用随机词呢?这是因为transformer要保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是"hairy"。至于使用随机词带来的负面影响,文章中解释说,所有其他的token(即非"hairy"的token)共享15%*10% = 1.5%的概率,其影响是可以忽略不计的。Transformer全局的可视,又增加了信息的获取,但是不让模型获取全量信息。
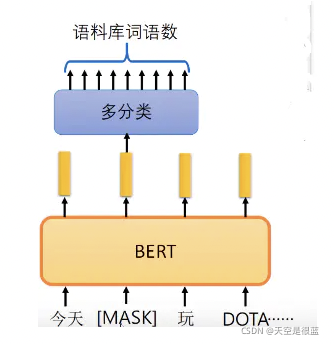
在将单词序列输入给 BERT 之前,每个序列中有 15% 的单词被 [MASK] token 替换。 然后模型尝试基于序列中其他未被 mask 的单词的上下文来预测被掩盖的原单词。
这样就需要:
- 在 encoder 的输出上添加一个分类层
- 用嵌入矩阵乘以输出向量,将其转换为词汇的维度
- 用 softmax 计算词汇表中每个单词的概率
BERT 的损失函数只考虑了 mask 的预测值,忽略了没有掩蔽的字的预测。这样的话,模型要比单向模型收敛得慢,不过结果的情境意识增加了。
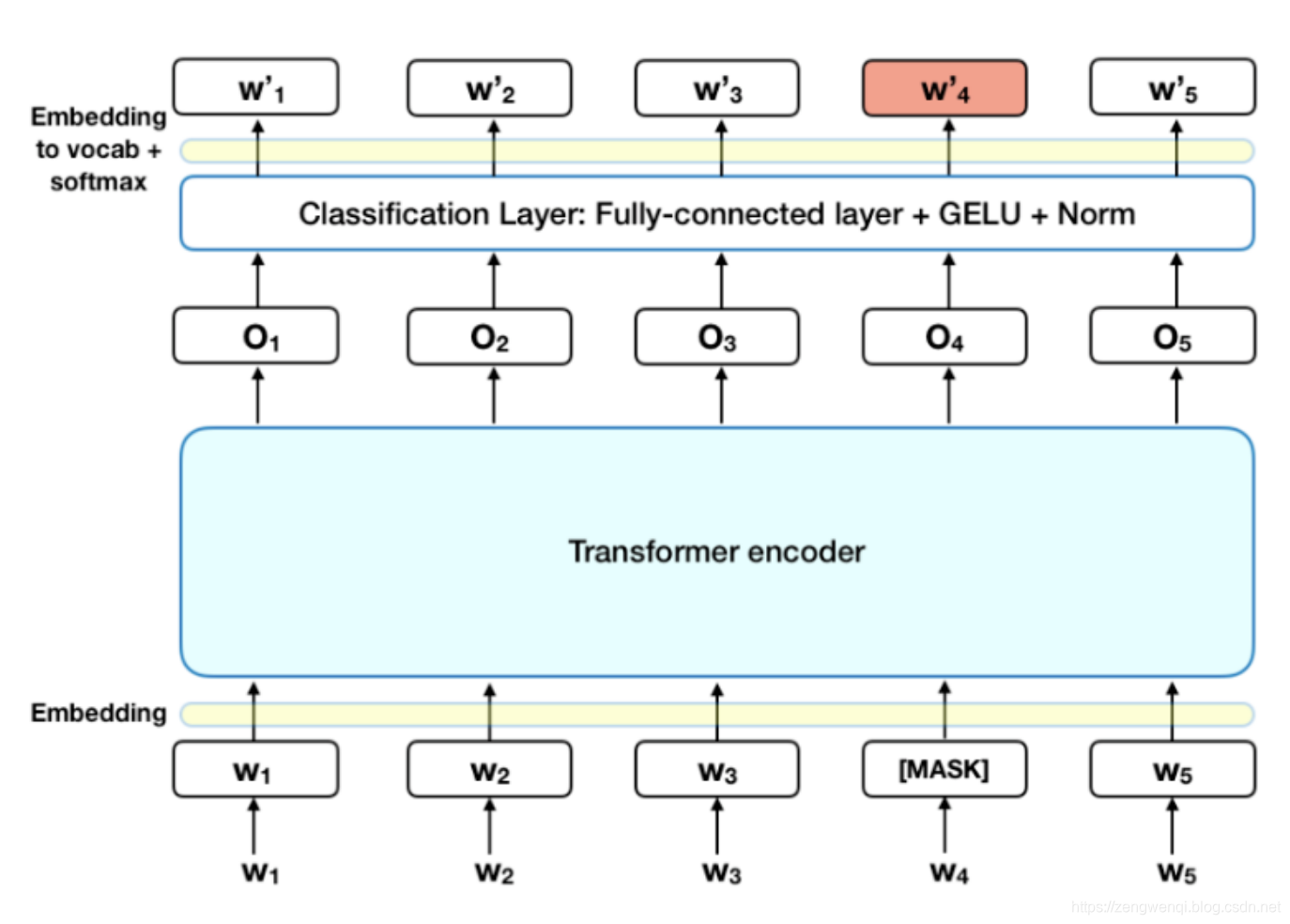
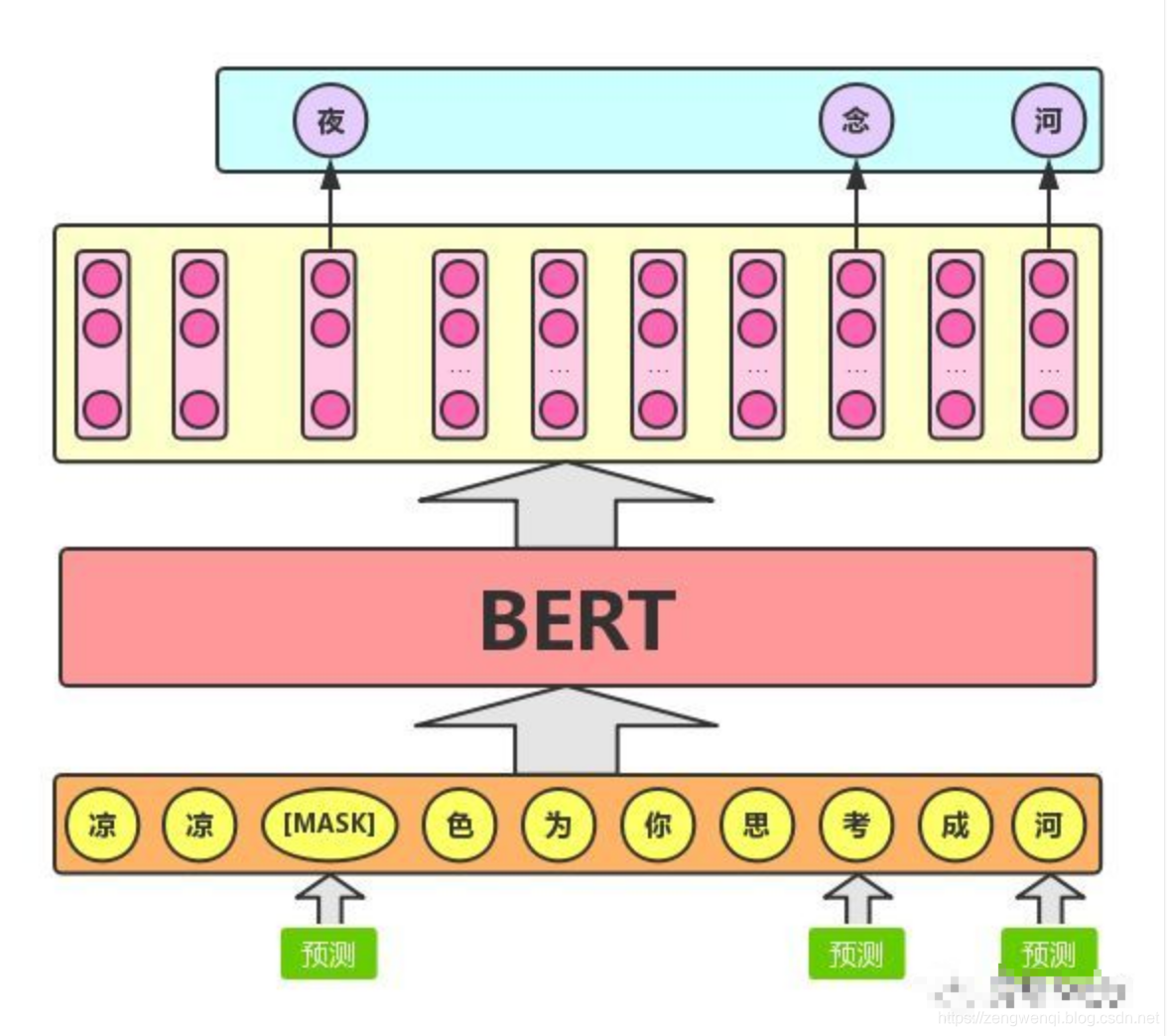
这不就是我们高中英语常做的完形填空么!所以说,BERT模型的预训练过程其实就是在模仿我们学语言的过程。
具体来说,文章作者在一句话中随机选择15%的词汇用于预测。对于在原句中被抹去的词汇,80%情况下采用一个特殊符号[MASK]替换,10%情况下采用一个任意词替换,剩余10%情况下保持原词汇不变。这么做的主要原因是:在后续微调任务中语句中并不会出现[MASK]标记,而且这么做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇(10%概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。
2. 下一句预测 Next Sentence Prediction
掩蔽语言模型(MLMs)学习理解单词之间的关系。此外,BERT还接受了下一个句子预测任务的训练,这些任务需要理解句子之间的关系。
此类任务的一个很好的例子是问题回答系统。
任务很简单。给定两个句子——A和B, B是语料库中A后面的下一个句子,还是一个随机的句子?
由于它是一个二分类任务,因此可以通过将任何语料库分成句子对来轻松生成数据。就像mlm一样,作者在这里也添加了一些注意事项。让我们举个例子:
假设我们有一个包含100,000个句子的文本数据集。因此,将有50,000个训练例子或句子对作为训练数据。
- 对于50%的对来说,第二个句子实际上是第一个句子的下一个句子
- 对于剩下的50%,第二句是语料库中的一个随机句子
- 第一种情况的标签是“IsNext”,而第二种情况的标签是“NotNext”
这就是为什么BERT能够成为一个真正的任务不可知的模型。它结合了掩蔽语言模型(MLM)和下一个句子预测(NSP)的预训练任务。
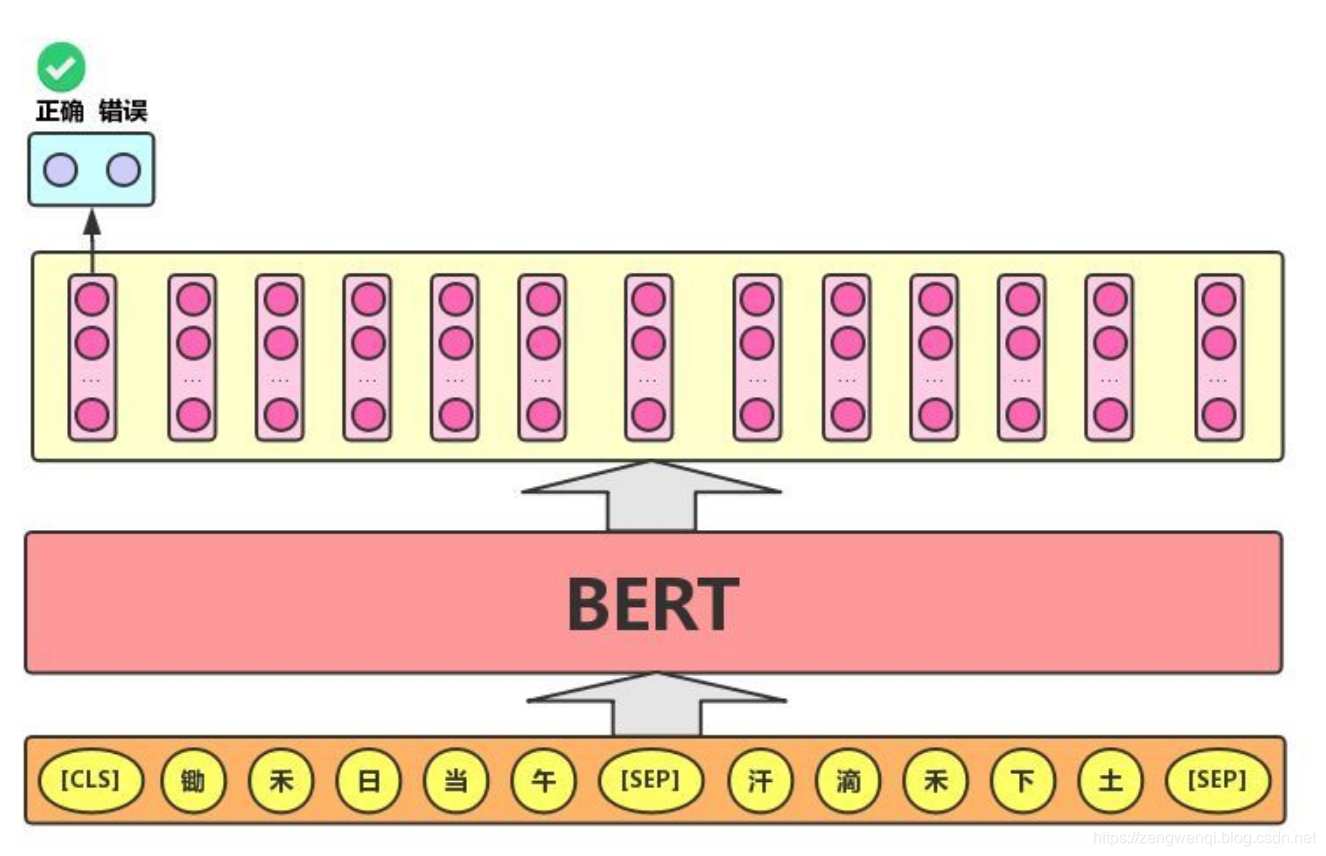
当年大学考英语四六级的时候,大家应该都做过段落重排序,即:将一篇文章的各段打乱,让我们通过重新排序把原文还原出来,这其实需要我们对全文大意有充分、准确的理解。
Next Sentence Prediction任务实际上就是段落重排序的简化版:只考虑两句话,判断是否是一篇文章中的前后句。在实际预训练过程中,文章作者从文本语料库中随机选择50%正确语句对和50%错误语句对进行训练,与Masked LM任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。
BERT模型通过对Masked LM任务和Next Sentence Prediction任务进行联合训练,使模型输出的每个字/词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。

五 BERT使用场景
BERT 可以用于各种NLP任务,只需在核心模型中添加一个层,例如:
- 在分类任务中,例如情感分析等,只需要在 Transformer 的输出之上加一个分类层
- 在问答任务(例如SQUAD v1.1)中,问答系统需要接收有关文本序列的 question,并且需要在序列中标记 answer。 可以使用 BERT 学习两个标记 answer 开始和结尾的向量来训练Q&A模型。
- 在命名实体识别(NER)中,系统需要接收文本序列,标记文本中的各种类型的实体(人员,组织,日期等)。 可以用 BERT 将每个 token 的输出向量送到预测 NER 标签的分类层。
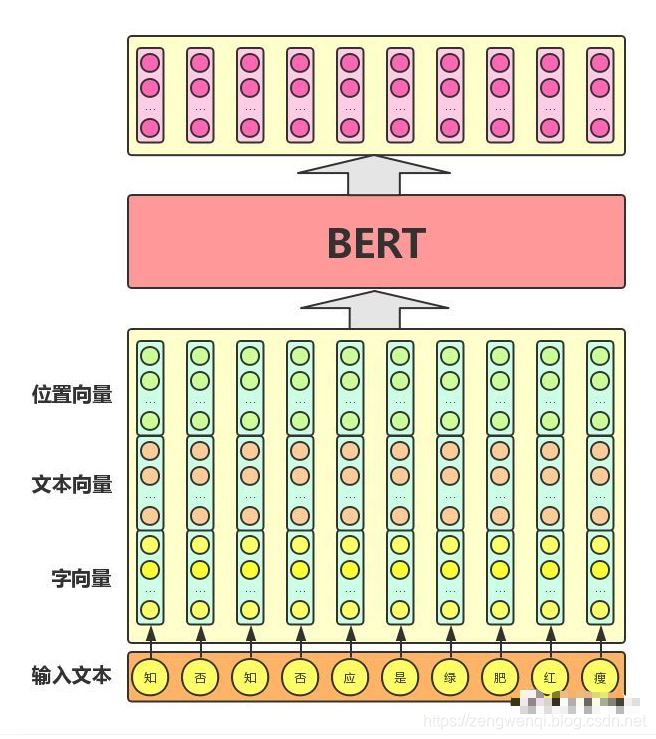
从上图中可以看出
1 字向量:BERT模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入;模型输出则是输入各字对应的融合全文语义信息后的向量表示。
2. 文本向量:该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合
3. 位置向量:由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:“我爱你”和“你爱我”),因此,BERT模型对不同位置的字/词分别附加一个不同的向量以作区分
最后,BERT模型将字向量、文本向量和位置向量的加和作为模型输入。特别地,在目前的BERT模型中,文章作者还将英文词汇作进一步切割,划分为更细粒度的语义单位(WordPiece),例如:将playing分割为play和##ing;此外,对于中文,目前作者尚未对输入文本进行分词,而是直接将单字作为构成文本的基本单位。
对于不同的NLP任务,模型输入会有微调,对模型输出的利用也有差异:
1. 单文本分类任务:
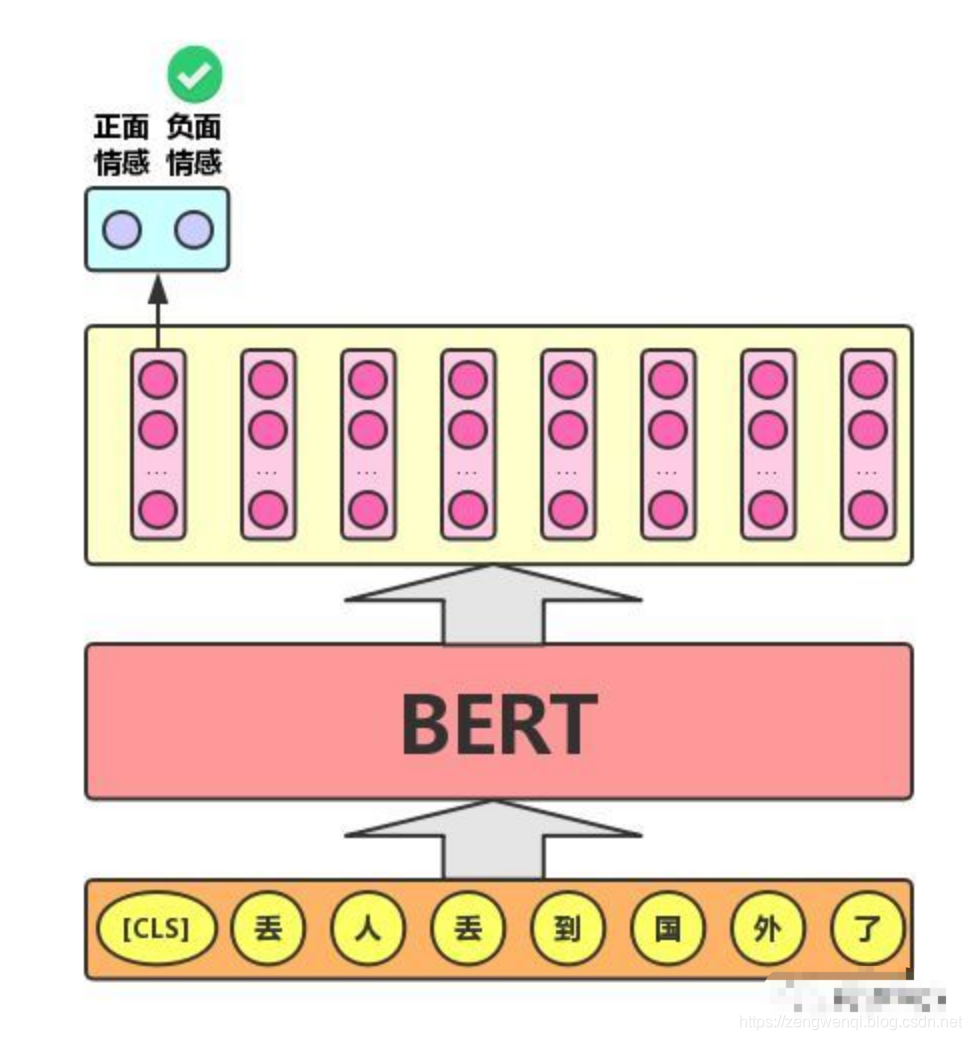
对于文本分类任务,BERT模型在文本前插入一个[CLS]符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类,如下图所示。可以理解为:与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息。
2 语句对分类任务
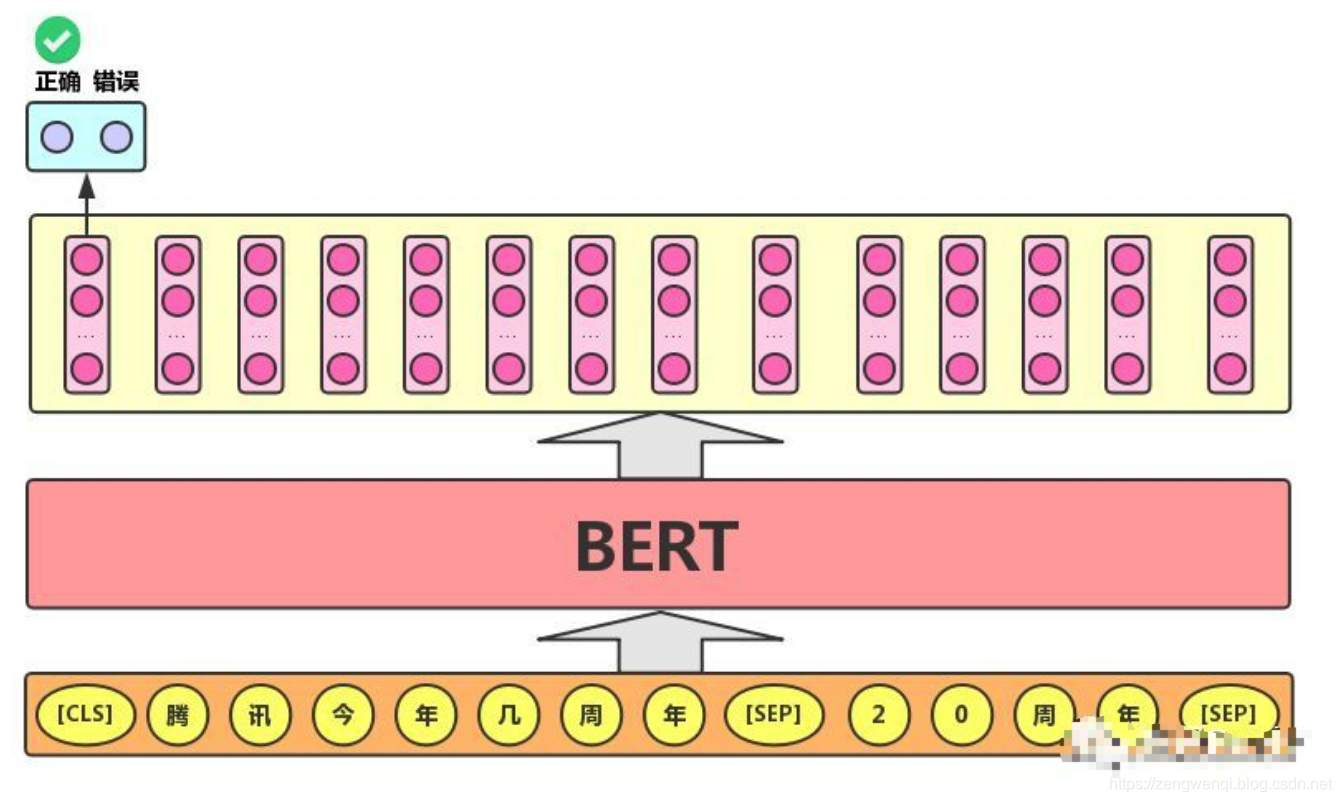
该任务的实际应用场景包括:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等。对于该任务,BERT模型除了添加[CLS]符号并将对应的输出作为文本的语义表示,还对输入的两句话用一个[SEP]符号作分割,并分别对两句话附加两个不同的文本向量以作区分,如下图所示。
3. 序列标注任务:
该任务的实际应用场景包括:中文分词&新词发现(标注每个字是词的首字、中间字或末字)、答案抽取(答案的起止位置)等。对于该任务,BERT模型利用文本中每个字对应的输出向量对该字进行标注(分类),如下图所示(B、I、E分别表示一个词的第一个字、中间字和最后一个字)。
六 BERT的评价
总结下BERT的主要贡献:
- 引入了Masked LM,使用双向LM做模型预训练。
- 为预训练引入了新目标NSP,它可以学习句子与句子间的关系。
- 进一步验证了更大的模型效果更好: 12 --> 24 层。
- 为下游任务引入了很通用的求解框架,不再为任务做模型定制。
- 刷新了多项NLP任务的记录,引爆了NLP无监督预训练技术。
BERT优点
- Transformer Encoder因为有Self-attention机制,因此BERT自带双向功能。
- 因为双向功能以及多层Self-attention机制的影响,使得BERT必须使用Cloze版的语言模型Masked-LM来完成token级别的预训练。
- 为了获取比词更高级别的句子级别的语义表征,BERT加入了Next Sentence Prediction来和Masked-LM一起做联合训练。
- 为了适配多任务下的迁移学习,BERT设计了更通用的输入层和输出层。
- 微调成本小。
BERT缺点
- task1的随机遮挡策略略显粗犷,推荐阅读《Data Nosing As Smoothing In Neural Network Language Models》。
- [MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现。每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)。
- BERT对硬件资源的消耗巨大(大模型需要16个tpu,历时四天;更大的模型需要64个tpu,历时四天。
七 实现BERT以进行文本分类
你的头脑一定被BERT所开辟的各种可能性搅得团团转。我们有许多方法可以利用BERT的大量知识来开发我们的NLP应用程序。
最有效的方法之一是根据你自己的任务和特定于任务的数据对其进行微调。然后我们可以使用BERT中的Embedding作为文本文档的Embedding。
在本节中,我们将学习如何在NLP任务中使用BERT的Embedding。我们将在以后的文章中讨论对整个BERT模型进行微调的概念。
为了从BERT中提取Embedding,我们将使用一个非常有用的开源项目: https://github.com/hanxiao/bert-as-service
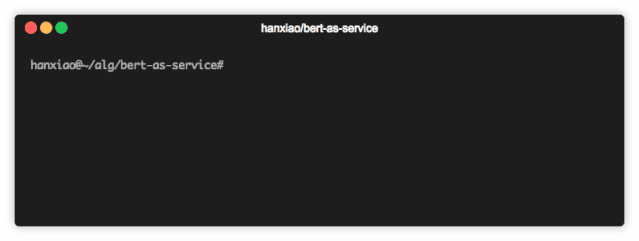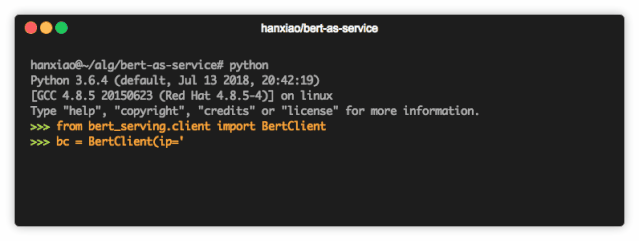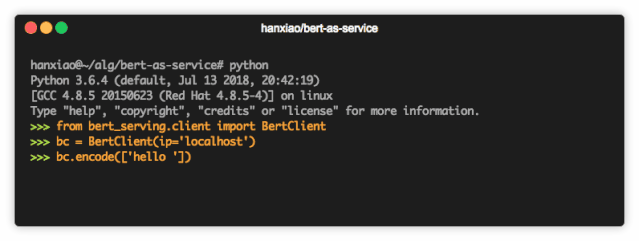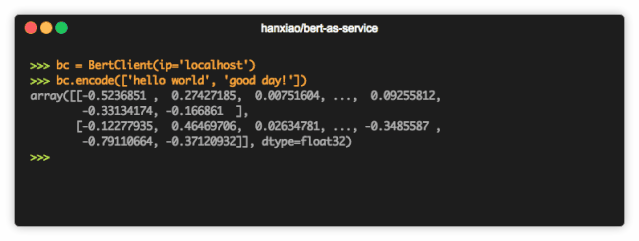
这个开源项目如此有用的原因是它允许我们只需两行代码使用BERT获取每个句子的Embedding。
安装BERT-As-Service
服务以一种简单的方式工作。它创建了一个BERT服务器。每次我们将一个句子列表发送给它时,它将发送所有句子的Embedding。
我们可以通过pip安装服务器和客户机。它们可以单独安装,甚至可以安装在不同的机器上:
pip install bert-serving-server # server
pip install bert-serving-client # client, independent of `bert-serving-server`
注意,服务器必须在Python >= 3.5上运行,而TensorFlow >= 1.10。
此外,由于运行BERT是一个GPU密集型任务,我建议在基于云的GPU或其他具有高计算能力的机器上安装BERT服务器。
现在,回到你的终端并下载下面列出的模型。然后,将zip文件解压缩到某个文件夹中,比如/tmp/english_L-12_H-768_A-12/。
以下是发布的预训练BERT模型列表:
BERT-Base, Uncased 12-layer, 768-hidden, 12-heads, 110M parameters https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip
BERT-Large, Uncased 24-layer, 1024-hidden, 16-heads, 340M parameters https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-24_H-1024_A-16.zip
BERT-Base, Cased 12-layer, 768-hidden, 12-heads, 110M parameters https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip
BERT-Large, Cased 24-layer, 1024-hidden, 16-heads, 340M parameters https://storage.googleapis.com/bert_models/2018_10_18/cased_L-24_H-1024_A-16.zip
BERT-Base, Multilingual Cased (New) 104 languages, 12-layer, 768-hidden, 12-heads, 110M parameters https://storage.googleapis.com/bert_models/2018_11_23/multi_cased_L-12_H-768_A-12.zip
BERT-Base, Multilingual Cased (Old) 102 languages, 12-layer, 768-hidden, 12-heads, 110M parameters https://storage.googleapis.com/bert_models/2018_11_03/multilingual_L-12_H-768_A-12.zip
BERT-Base, Chinese Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip我们将下载BERT Uncased,然后解压缩zip文件:
wget https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip && unzip uncased_L-12_H-768_A-12.zip
将所有文件提取到一个文件夹中之后,就可以启动BERT服务了:
bert-serving-start -model_dir uncased_L-12_H-768_A-12/ -num_worker=2 -max_seq_len 50
现在,你可以从Python代码(使用客户端库)简单地调用BERT-As-Service。让我们直接进入代码!
打开一个新的Jupyter notebook,试着获取以下句子的Embedding:“I love data science and analytics vidhya”。
from bert_serving.client import BertClient
# 使用BERT服务器的ip地址与它建立连接;如果是同一台电脑,不用填写IP
bc = BertClient(ip="SERVER_IP_HERE")
# 获取embedding
embedding = bc.encode(["I love data science and analytics vidhya."])
# 检查embedding的形状,应该是 1x768
print(embedding.shape)
这里,IP地址是你的服务器或云的IP。如果在同一台计算机上使用,则不需要此字段。
返回的embedding形状为(1,768),因为BERT的架构中一个句子由768个隐藏单元表示。
问题: 在Twitter上对不良言论进行分类
让我们拿一个真实世界的数据集来看看BERT有多有效。我们将使用一个数据集,该数据集由一系列推文组成,这些推文被归类为“不良言论”或非“不良言论”。
为了简单起见,如果一条推文带有种族主义或性别歧视的情绪,我们就说它包含不良言论。因此,我们的任务是将种族主义或性别歧视的推文与其他推文进行分类。
数据集链接
https://datahack.analyticsvidhya.com/contest/practice-problem-twitter-sentiment-analysis/?utm_source=blog&utm_medium=demystifying-bert-groundbreaking-nlp-framework。
我们将使用BERT从数据集中的每个推特中提取Embedding,然后使用这些Embedding来训练文本分类模型。
以下是该项目的整体结构:
现在让我们看一下代码:
import pandas as pd
import numpy as np
# 加载数据
train = pd.read_csv('BERT_proj/train_E6oV3lV.csv', encoding='iso-8859-1')
train.shape你会熟悉大多数人是如何发推特的。有许多随机的符号和数字(又名聊天语言!)我们的数据集也一样。我们需要在通过BERT之前对它进行预处理:
import re
# 清理噪声
def clean_text(text):
# 只剩字符
text = re.sub(r'[^a-zA-Z\']', ' ', text)
# 去除unicode字符
text = re.sub(r'[^\x00-\x7F]+', '', text)
# 转换成小写
text = text.lower()
return text
train['clean_text'] = train.tweet.apply(clean_text)现在数据集是干净的,它被分割成训练集和验证集:
from sklearn.model_selection import train_test_split
# 分割成训练集和验证集
X_tr, X_val, y_tr, y_val = train_test_split(train.clean_text, train.label, test_size=0.25, random_state=42)
print('X_tr shape:',X_tr.shape)
让我们在训练和验证集中获得所有推特的Embedding:
from bert_serving.client import BertClient
# 连接BERT服务器
bc = BertClient(ip="YOUR_SERVER_IP")
# 编码训练集和验证集
X_tr_bert = bc.encode(X_tr.tolist())
X_val_bert = bc.encode(X_val.tolist())
现在是建模时间!我们来训练分类模型:
from sklearn.linear_model import LogisticRegression
# 使用LR模型
model_bert = LogisticRegression()
# 训练
model_bert = model_bert.fit(X_tr_bert, y_tr)
# 预测
pred_bert = model_bert.predict(X_val_bert)
检查分类精度:
from sklearn.metrics import accuracy_score
print(accuracy_score(y_val, pred_bert))即使使用如此小的数据集,我们也可以轻松获得大约95%的分类精度,这真的非常棒。
我鼓励你继续尝试BERT对不同问题进行尝试
超越BERT:目前最先进的NLP
BERT激发了人们对NLP领域的极大兴趣,特别是NLP任务中Transformer的应用。这导致了研究实验室和组织的数量激增,他们开始研究预训练、BERT和fine-tuning的不同方面。
许多这样的项目在多个NLP任务上都比BERT做得好。其中最有趣的是RoBERTa,这是Facebook人工智能对BERT和DistilBERT的改进,而DistilBERT是BERT的精简版和快速版。
BERT相关论文、文章和代码资源汇总
1、Google官方:
1) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
一切始于10月Google祭出的这篇Paper, 瞬间引爆整个AI圈包括自媒体圈: https://arxiv.org/abs/1810.04805
2) Github: https://github.com/google-research/bert
11月Google推出了代码和预训练模型,再次引起群体亢奋。
3) Google AI Blog: Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing
2、第三方解读:
1) 张俊林博士的解读, 知乎专栏:从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
我们在AINLP微信公众号上转载了这篇文章和张俊林博士分享的PPT,欢迎关注:
5) BERT Explained: State of the art language model for NLP
6) BERT介绍
9) 干货 | BERT fine-tune 终极实践教程: 奇点智能BERT实战教程,在AI Challenger 2018阅读理解任务中训练一个79+的模型。
10) 【BERT详解】《Dissecting BERT》by Miguel Romero Calvo
Dissecting BERT Part 1: The Encoder
Understanding BERT Part 2: BERT Specifics
Dissecting BERT Appendix: The Decoder
11)BERT+BiLSTM-CRF-NER用于做ner识别
12)AI赋能法律 | NLP最强之谷歌BERT模型在智能司法领域的实践浅谈
3 第三方代码:
1) pytorch-pretrained-BERT: https://github.com/huggingface/pytorch-pretrained-BERT
Google官方推荐的PyTorch BERB版本实现,可加载Google预训练的模型:PyTorch version of Google AI's BERT model with script to load Google's pre-trained models
2) BERT-pytorch: https://github.com/codertimo/BERT-pytorch
另一个Pytorch版本实现:Google AI 2018 BERT pytorch implementation
3) BERT-tensorflow: https://github.com/guotong1988/BERT-tensorflow
Tensorflow版本:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
4) bert-chainer: https://github.com/soskek/bert-chainer
Chanier版本: Chainer implementation of "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"
5) bert-as-service: https://github.com/hanxiao/bert-as-service
将不同长度的句子用BERT预训练模型编码,映射到一个固定长度的向量上:Mapping a variable-length sentence to a fixed-length vector using pretrained BERT model
这个很有意思,在这个基础上稍进一步是否可以做一个句子相似度计算服务?有没有同学一试?
6) bert_language_understanding: https://github.com/brightmart/bert_language_understanding
BERT实战:Pre-training of Deep Bidirectional Transformers for Language Understanding: pre-train TextCNN
7) sentiment_analysis_fine_grain: https://github.com/brightmart/sentiment_analysis_fine_grain
BERT实战,多标签文本分类,在 AI Challenger 2018 细粒度情感分析任务上的尝试:Multi-label Classification with BERT; Fine Grained Sentiment Analysis from AI challenger
8) BERT-NER: https://github.com/kyzhouhzau/BERT-NER
BERT实战,命名实体识别: Use google BERT to do CoNLL-2003 NER !
9) BERT-keras: https://github.com/Separius/BERT-keras
Keras版: Keras implementation of BERT with pre-trained weights
BERT的非官方实现,可以加载官方的预训练模型进行特征提取和预测。
https://github.com/CyberZHG/keras-bert
已经基本实现bert,并且能成功加载官方权重,经验证模型输出跟keras-bert一致,大家可以放心使用
https://github.com/bojone/bert4keras
10) tbert: https://github.com/innodatalabs/tbert
PyTorch port of BERT ML model
11) BERT-Classification-Tutorial: https://github.com/Socialbird-AILab/BERT-Classification-Tutorial
12) BERT-BiLSMT-CRF-NER: https://github.com/macanv/BERT-BiLSMT-CRF-NER
Tensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuning
13) bert-Chinese-classification-task
bert中文分类实践
14) bert-chinese-ner: https://github.com/ProHiryu/bert-chinese-ner
使用预训练语言模型BERT做中文NER
15)BERT-BiLSTM-CRF-NER
Tensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuning
16) bert-sequence-tagging: https://github.com/zhpmatrix/bert-sequence-tagging
基于BERT的中文序列标注
参考:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









