







 本文深入解析MapReduce的工作原理及其在Hadoop集群上的应用优势,通过具体实例展示如何使用Python结合Hadoop Streaming进行词频统计,同时探讨在MapReduce作业中引入第三方Python库的方法。
本文深入解析MapReduce的工作原理及其在Hadoop集群上的应用优势,通过具体实例展示如何使用Python结合Hadoop Streaming进行词频统计,同时探讨在MapReduce作业中引入第三方Python库的方法。
一 Map和Reduce
首先看下MR的工作原理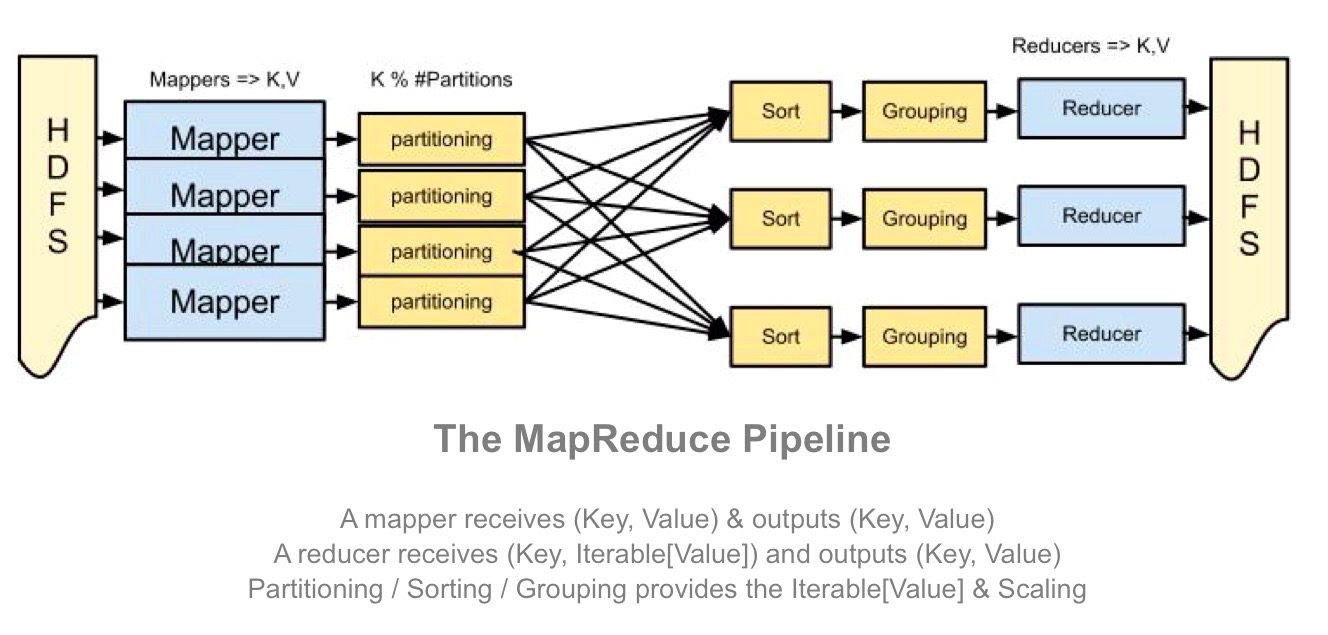
MapReduce的好处是它可以把在内存中不能完成的事转变成可以在硬盘上高效完成。
Map-‐Reduce 对于集群的好处:
1,在多节点上冗余地存储数据,以保证数据的持续性和一直可取性
2, 将计算移向数据端,以最大程度减少数据移动
3,简单的程序模型隐藏所有的复杂度
Map,Reduce一般的流程:
Map阶段:
a, 逐个文件逐行扫描
b, 扫描的同时抽取出我们感兴趣的内容 (Keys)
Group by key
排序和洗牌
(Group by key阶段会自动的运行,不需要自己写)
Reduce阶段:
a, 聚合 、 总结 、 过滤或转换
b, 写入结果
二 Hadoop Streaming原理
Hadoop 不仅可以使用Java进行MapReduce的编写,也通过Hadoop Streaming的方式提供了其他语言编写MR的接口。更重要的是,使用python来编写MR,比使用亲儿子Java编写MR要更简单和方便……所以在一些不非常复杂的任务中使用python来编写MR比起使用Java,是更加划算的。
Hadoop streaming是Hadoop的一个工具, 它帮助用户创建和运行一类特殊的map/reduce作业, 这些特殊的map/reduce作业是由一些可执行文件或脚本文件充当mapper或者reducer。
比如可以使用python语言来写map-reduce使用“Hadoop Streaming”来完成传统mapreduce的功能。
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \
-input myInputDirs \
-output myOutputDir \
-mapper mapper.py \
-reducer reducer.py
上述代码通过参数input,output,mapper,reducer来定义输入数据,输出数据,mapper文件,reducer文件。
在上面的代码中,mapper和reducer都是可执行文件,它们从标准输入读入数据(一行一行读), 并把计算结果发给标准输出。Streaming工具会创建一个Map/Reduce作业, 并把它发送给合适的集群,同时监视这个作业的整个执行过程。
如果一个可执行文件被用于mapper,则在mapper初始化时, 每一个mapper任务会把这个可执行文件作为一个单独的进程启动。 mapper任务运行时,它把输入切分成行并把每一行提供给可执行文件进程的标准输入。 同时,mapper收集可执行文件进程标准输出的内容,并把收到的每一行内容转化成key/value对,作为mapper的输出。 默认情况下,一行中第一个tab之前的部分作为key,之后的(不包括tab)作为value。 如果没有tab,整行作为key值,value值为null。
如果一个可执行文件被用于reducer,每个reducer任务会把这个可执行文件作为一个单独的进程启动。 Reducer任务运行时,它把输入切分成行并把每一行提供给可执行文件进程的标准输入。 同时,reducer收集可执行文件进程标准输出的内容,并把每一行内容转化成key/value对,作为reducer的输出。 默认情况下,一行中第一个tab之前的部分作为key,之后的(不包括tab)作为value。
三 词频统计的例子
Python实现Wordcount:
1. mapper.py
[root@vm wordcount]# vim mapper.py
写入
#!/usr/bin/python
import sys
word2count = {}
for line in sys.stdin:
line = line.strip()
words = filter(lambda word:word,line.split())
for word in words:
print("%s\t%s" % (word,1))
2. reducer.py
[root@vm wordcount]# vim reducer.py
写入
#!/usr/bin/python
from operator import itemgetter
import sys
word2count = {}
for line in sys.stdin:
line = line.strip()
word,count = line.split()
try:
count = int(count)
word2count[word] = word2count.get(word,0) + count
except ValueError as err:
print(err)
pass
sorted_word2count = sorted(word2count.items(),key=itemgetter(0))
for word,count in sorted_word2count:
print("%s\t%s" % (word, count))
3. 准备一个测试文件test.txt
[root@vm wordcount]# vim test.txt
写入
this is a test
this is a test
this is a test
this is a test
4. 本地测试
[root@vm wordcount]# cat test.txt |python mapper.py |sort|python reducer.py
a 4
is 4
test 4
this 4
[root@vm wordcount]#
5. 集群运行
集群运行前要将本地的测试文件上传到hdfs
[root@vm wordcount]# hadoop fs -mkdir /user/root/wordcount
[root@vm wordcount]# hadoop fs -put test.txt /user/root/wordcount/
[root@vm wordcount]# hadoop fs -ls /user/root/wordcount/
Found 1 items
-rw-r--r-- 3 root root 60 2018-05-14 09:58 /user/root/wordcount/test.txt
[root@vm wordcount]#
运行mapreduce
[root@vm wordcount]# hadoop jar /opt/cloudera/parcels/CDH-5.13.1-1.cdh5.13.1.p0.2/jars/hadoop-streaming-2.6.0-cdh5.13.1.jar -D mapred.reduce.tasks=1 -mapper "python mapper.py" -reducer "python reducer.py" -file mapper.py -file reducer.py -input /user/root/wordcount/test.txt -output /user/root/wordcount/out
命令行查看结果
[root@vm wordcount]# hadoop fs -cat /user/root/wordcount/out/part-00000
a 4
is 4
test 4
this 4
[root@vm wordcount]# 四 使用第三方的Python库
$HADOOP_HOME/bin/hadoop streaming -D mapred.job.priority='VERY_HIGH' -D mared.job.map.capacity=500 -D mapred.reduce.tasks=0 -D mapred.map.tasks=500 -input myInputDirs(你得HDFS路径) -output myOutputDir(你的HDFS路径) -mapper "python yourpythonfile.py" -reducer "python yourpythonfile.py" -file yourpythonfile.py(需要几个就添加几个-file) -cacheArchive "/xx/xx/xx/myvp.tar.gz#myvp"(此处是一个HDFS路径,稍后用到)
使用第三方库
需要使用第三方库如bs4,numpy等时,需要用到虚拟环境virtualenv
virtualenv的使用
安装
pip install virtualenv
新建虚拟环境
virtualenv myvp
使得虚拟环境的路径为相对路径
virtualenv --relocatable myvp
激活虚拟环境
source myvp/bin/activate
如果想退出,可以使用下面的命令
deactivate
激活后直接安装各种需要的包
pip install XXX
压缩环境包
tar -czf myvp.tar.gz myvp
在mapreduce上使用
在上面的脚本中可以看到使用了-catchArchive,但是路径是HDFS的路径,因此需要提前将本地的myvp.tai.gz包上传到HDFS上。
同时#后面的myvp是文件的文件夹,解压后还有一个myvp(因为压缩的时候把文件夹本身也压缩进去了),所有map中使用的时候的路径就是myvp/myvp/bin/…
在map的python脚本中加入如下的代码,会把第三方库加入到python 路径
import sys
sys.path.append("myvp/myvp/lib/python2.7")
参考:
https://blog.csdn.net/wawa8899/article/details/80305720
https://blog.csdn.net/wh357589873/article/details/70049088

















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









