







Given a non-empty tree with root
R
R
R, and with weight
W
i
W_i
Wi assigned to each tree node
T
i
T_i
Ti. The weight of a path from
R
R
R to
L
L
L is defined to be the sum of the weights of all the nodes along the path from
R
R
R to any leaf node
L
L
L.
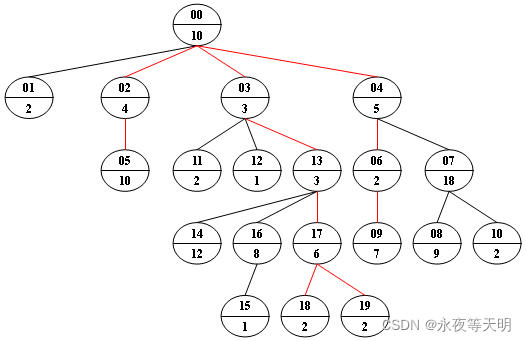
Now given any weighted tree, you are supposed to find all the paths with their weights equal to a given number. For example, let’s consider the tree showed in the following figure: for each node, the upper number is the node ID which is a two-digit number, and the lower number is the weight of that node. Suppose that the given number is 24, then there exists 4 different paths which have the same given weight: {10 5 2 7}, {10 4 10}, {10 3 3 6 2} and {10 3 3 6 2}, which correspond to the red edges in the figure.
Input Specification:
Each input file contains one test case. Each case starts with a line containing
0
<
N
≤
100
0<N≤100
0<N≤100, the number of nodes in a tree,
M
(
<
N
)
M (<N)
M(<N), the number of non-leaf nodes, and
0
<
S
<
2
30
0<S<2^{30}
0<S<230, the given weight number. The next line contains N positive numbers where
W
i
W_i
Wi (<1000) corresponds to the tree node
T
i
T_i
Ti. Then
M
M
M lines follow, each in the format:
ID K ID[1] ID[2] ... ID[K]
where ID is a two-digit number representing a given non-leaf node, K is the number of its children, followed by a sequence of two-digit ID’s of its children. For the sake of simplicity, let us fix the root ID to be 00.
Output Specification:
For each test case, print all the paths with weight S in non-increasing order. Each path occupies a line with printed weights from the root to the leaf in order. All the numbers must be separated by a space with no extra space at the end of the line.
Note: sequence { A 1 , A 2 , ⋯ , A n A_1,A_2 ,⋯,A_n A1,A2,⋯,An} is said to be greater than sequence { B 1 , B 2 , ⋯ , B m B_1,B_2,⋯,B_m B1,B2,⋯,Bm} if there exists 1 ≤ k < m i n { n , m } 1≤k<min\{n,m\} 1≤k<min{n,m} such that A i = B i A_i=B_i Ai=Bi for i = 1 , ⋯ , k , i=1,⋯,k, i=1,⋯,k, and A k + 1 > B k + 1 A_{k+1}>B_{k+1} Ak+1>Bk+1.
Sample Input:
20 9 24
10 2 4 3 5 10 2 18 9 7 2 2 1 3 12 1 8 6 2 2
00 4 01 02 03 04
02 1 05
04 2 06 07
03 3 11 12 13
06 1 09
07 2 08 10
16 1 15
13 3 14 16 17
17 2 18 19
Sample Output:
10 5 2 7
10 4 10
10 3 3 6 2
10 3 3 6 2
思路:深度优先遍历。记录所有情况的路径,最后对路径按字典序大小排序。有关《算法笔记》答案和最后一个测试点的问题见最后。
正确解法:
#include <cstdio>
#include <iostream> // 不知道为什么不用这个头文件PAT会对greater报错
#include <vector>
#include <algorithm>
using namespace std;
const int maxn = 110;
struct node {
int weight;
vector<int> child;
} Node[maxn];
int n, m, s;
vector<int> path; //路径
vector<vector<int>> ans; //存放所有路径
void DFS(int index, vector<int> path, int sum) {
if (sum > s) return;
if (sum == s) {
if (Node[index].child.size() != 0) return; //还未到叶子结点
ans.push_back(path);
return;
}
for (int i = 0; i < Node[index].child.size(); i++) {
int child = Node[index].child[i];
path.push_back(Node[child].weight);
DFS(child, path, sum + Node[child].weight);
path.pop_back();
}
}
int main() {
scanf("%d %d %d", &n, &m, &s);
for (int i = 0; i < n; i++) {
scanf("%d", &Node[i].weight);
}
int id, k, child;
for (int i = 0; i < m; i++) {
scanf("%d %d", &id, &k);
for (int j = 0; j < k; j++) {
scanf("%d", &child);
Node[id].child.push_back(child);
}
}
path.push_back(Node[0].weight);
DFS(0, path, Node[0].weight);
//对每种情况按字典序从大到小排序
sort(ans.begin(), ans.end(), greater<vector<int>>());
for (int i = 0; i < ans.size(); i++) {
printf("%d", ans[i][0]);
for (int j = 1; j < ans[i].size(); j++) {
printf(" %d", ans[i][j]);
}
printf("\n");
}
return 0;
}
《算法笔记》给的代码以及网上常见代码为:
(注意下面的代码存在问题)
#include <cstdio>
#include <vector>
#include <algorithm>
using namespace std;
const int maxn = 110;
struct node {
int weight;
vector<int> child;
} Node[maxn];
bool cmp(int a, int b) {
return Node[a].weight > Node[b].weight;
}
int n, m, s;
int path[maxn];
void DFS(int index, int numNode, int sum) {
if (sum > s) return;
if (sum == s) {
if (Node[index].child.size() != 0) return;
for (int i = 0; i < numNode; i++) {
printf("%d", Node[path[i]].weight);
if (i < numNode - 1) {
printf(" ");
} else {
printf("\n");
}
}
return;
}
for (int i = 0; i < Node[index].child.size(); i++) {
int child = Node[index].child[i];
path[numNode] = child;
DFS(child, numNode + 1, sum + Node[child].weight);
}
}
int main() {
scanf("%d %d %d", &n, &m, &s);
for (int i = 0; i < n; i++) {
scanf("%d", &Node[i].weight);
}
int id, k, child;
for (int i = 0; i < m; i++) {
scanf("%d %d", &id, &k);
for (int j = 0; j < k; j++) {
scanf("%d", &child);
Node[id].child.push_back(child);
}
//排序存在问题
sort(Node[id].child.begin(), Node[id].child.end(), cmp);
}
path[0] = 0;
DFS(0, 1, Node[0].weight);
return 0;
}
坑:《算法笔记》的排序只能保证每个结点的所有子节点是按照顺序排序的,这在所有子节点的值不同时并不会产生问题。但是如果子节点有相同值就会遇到问题。比如下面的输入。
7 5 8
1 2 2 2 3 3 2
00 2 01 02
01 1 03
02 1 04
03 1 05
04 1 06
对应的树为:
1
/ \
2 2
/ \
2 3
/ \
3 2
按照有问题的解法来处理最后保存得到的树形状和上面的形状会一样,这样就会导致输出为:
1 2 2 3
1 2 3 2
而实际上期望的正确输出为:
1 2 3 2
1 2 2 3
这应该就是最后一个测试点为什么不能通过的原因了(因为看不见测试点的值我也只是猜测,如果有其他想法欢迎在评论区讨论)。总而言之,在处理子节点的值可能相同时,会遇到很多意外情况。














 112
112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









