







Linux设备驱动prebe过程(二)
上周整理了非热插拔设备驱动的probe过程,留了个小尾巴,这周先补上,共2个遗留课题:
- 热插拔设备驱动probe过程
- 以ko方式加载的driver如何实现probe
Linux设备驱动probe系列文章:
1. 热插拔设备驱动probe过程
链接如下:
Linux设备驱动probe过程(三)
2. 以ko方式加载driver的probe过程
将 Linux 驱动程序编译成内核模块(.ko 文件)有一些优势和适用场景:
- 动态加载和卸载:
内核模块可以在系统运行时动态加载和卸载,而不需要重新编译和重新启动整个内核。这使得系统管理更加灵活,可以根据需要添加或删除驱动程序,而不会影响系统的稳定性和运行。 - 节省内存:将驱动程序编译成内核模块可以节省内存,因为内核模块只在需要时加载到内存中。这对于系统资源受限的嵌入式系统或嵌入式设备尤为重要。
- 快速开发和调试:
内核模块的开发和调试相对于直接将驱动程序编译到内核中更为方便。您可以在不影响系统稳定性的情况下,快速加载、卸载和调试驱动程序。 - 模块化设计:将驱动程序编译成内核模块可以促使您采用模块化设计的思路,将功能模块化并独立开发,有助于提高代码的可维护性和可重用性。
- 定制化:使用内核模块可以实现对内核功能的定制化,您可以根据需要仅加载必要的模块,从而减小内核的体积,并降低系统的攻击面。
- 保密性:有些解决方案厂商会把一些知识产权保密性更高的模块以ko等方式对客户发布,而不release源码。如果客户需要源码来参考,需要支付额外的费用。
然而,将驱动程序编译到内核中也有其优势,例如性能方面可能会更好,因为编译到内核中的驱动程序不需要动态加载,但这通常会导致内核体积增加并且需要重新编译内核才能生效。因此,根据具体的应用场景和需求,选择将驱动程序编译成内核模块或编译到内核中是有所取舍的。
2.1 用户侧实现 - insmod
一般用户侧会在启动脚本、运行脚本和代码中进行ko的加载,最为常见的就是insmod命令。当下大部分Linux系统上,insmod命令通常为一个软链接:
$ ls -l /sbin/insmod lrwxrwxrwx 1 root root 9 Jul 28 2020
/sbin/insmod -> /bin/kmod
接下来看下它的实现,如何实现用户态到内核态的跳转,根据封装程度,拆成3个步骤来开:
- insmod命令到kmod_module_insert_module
- kmod_module_insert_module到syscall
- syscall到内核__do_sys_init_module
2.1.1 从执行insmod命令到kmod_module_insert_module
参考kmode代码:https://git.kernel.org/cgit/utils/kernel/kmod/kmod.git
这个阶段主要为加载ko做准备。
// insmod入口
int main(int argc, char *argv[])
{
int err;
/* program_invocation_short_name 为正在运行程序的文件名
比如: busybox, init, mkdir.
若insmod为软链接:/sbin/insmod -> /bin/kmod*
streq函数比较两个字符串,相等返回1
*/
if (streq(program_invocation_short_name, "kmod"))
err = handle_kmod_commands(argc, argv);
else
err = handle_kmod_compat_commands(argc, argv);
return err;
}
static int handle_kmod_commands(int argc, char *argv[])
{
...
for (i = 0, err = -EINVAL; i < ARRAY_SIZE(kmod_cmds); i++) {
if (streq(kmod_cmds[i]->name, cmd)) {
err = kmod_cmds[i]->cmd(--argc, ++argv);
break;
}
}
...
}
// 跳一些步骤,来到 do_insmod:
const struct kmod_cmd kmod_cmd_compat_insmod = {
.name = "insmod",
.cmd = do_insmod,
.help = "compat insmod command",
};
static int do_insmod(int argc, char *argv[])
{
...
// 1. 创建一个modules上下文ctx, 包含refcount, log配置, linux modules绝对路径..
ctx = kmod_new(NULL, &null_config);
...
// 2. 创建ko上下文mod, 递增ref, 提取hashkey ..
err = kmod_module_new_from_path(ctx, filename, &mod);
...
// 3. 将ko加载到kernel
err = kmod_module_insert_module(mod, flags, opts);
...
kmod_module_unref(mod);
...
kmod_unref(ctx);
...
}
- program_invocation_short_name实现获取程序名(拓展阅读)
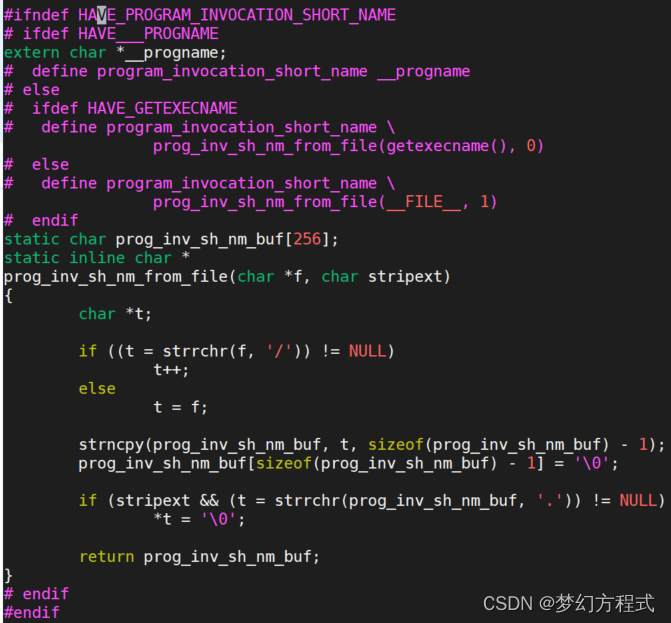
2.1.2 kmod_module_insert_module到syscall
之后流程就是开始加载ko了,可以通过"-f"配置flag决定是否开展ko校验:
- KMOD_INSERT_FORCE_VERMAGIC: ignore kernel version magic;
- KMOD_INSERT_FORCE_MODVERSION: ignore symbol version hashes.
KMOD_EXPORT int kmod_module_insert_module(struct kmod_module *mod,
unsigned int flags,
const char *options)
{
int err;
const void *mem;
off_t size;
struct kmod_elf *elf;
const char *path;
const char *args = options ? options : "";
...
// 1. 获取ko路径
path = kmod_module_get_path(mod);
...
// 2. open ko文件,mmap到内存
mod->file = kmod_file_open(mod->ctx, path);
if (kmod_file_get_direct(mod->file)) {
...
// 4. 检测ko elf有效性,在/sys/module/目录创建当前ko目录,尝试加载ko,注意若成功则不再执行下面流程!!
err = finit_module(kmod_file_get_fd(mod->file), args, kernel_flags);
...
}
// 5. 获取ko文件映射的mem
if (flags & (KMOD_INSERT_FORCE_VERMAGIC | KMOD_INSERT_FORCE_MODVERSION)) {
...
mem = kmod_elf_get_memory(elf);
} else {
mem = kmod_file_get_contents(mod->file);
}
// 6. 获取ko size
size = kmod_file_get_size(mod->file);
// 7. 调用init_module加载ko
err = init_module(mem, size, args);
...
}
// init_module 实现
#define init_module(mod, len, opts) syscall(__NR_init_module, mod, len, opts)
// finit_module 实现
static inline int finit_module(int fd, const char *uargs, int flags)
{
if (__NR_finit_module == -1) {
errno = ENOSYS;
return -1;
}
return syscall(__NR_finit_module, fd, uargs, flags);
}
可以看到ko加载最终是通过syscall调用到了内核接口,根据路径和参数不同,存在两种不同调用方式:finit_module 和 init_module
那么接下来我们再看下到内核部分的调用过程。
2.1.3 __NR_init_module (拓展阅读)
在 Linux 中,__NR 前缀通常用于系统调用(syscall)的定义。系统调用是用户空间程序与内核之间进行通信的一种方式,用于请求操作系统提供的服务或功能。每个系统调用都有一个唯一的整数标识符,而 __NR 前缀后跟着的整数就是系统调用的标识符。
例如,__NR_open 是打开文件的系统调用,__NR_read 是读取文件内容的系统调用。在使用这些系统调用时,可以直接使用它们的标识符,而不必记住具体的数字值。
系统调用的具体实现会在内核中定义,并与相应的标识符进行关联。在用户空间程序中调用系统调用时,通常会使用 C 语言提供的库函数(如 open()、read() 等),而这些库函数会最终调用相应的系统调用。
__NR 前缀是 Linux 中用于系统调用标识符的约定,使得系统调用在不同的内核版本中都能够保持一致性。
以上是GPT回答的,是不是有点啰嗦和模糊,不过当概括性理解是没问题的。再补充两句:
- __NR_init_module 其实是一个约定的数值,作为系统调用码。
- kernel侧实现位于
kernel/module.c中,一般用SYSCAL_DEFINEX宏来声明和定义,实现参考2.2章节。这里看下SYSSCALL_DEFINE3宏的实现:
SYSCALL_DEFINE3(finit_module, int, fd, const char __user *, uargs, int, flags)
...
// SYSCALL_DEFINE3 宏实现
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
// 进一步
#define SYSCALL_DEFINEx(x, sname, ...) \
SYSCALL_METADATA(sname, x, __VA_ARGS__) \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
// 最终到__SYSCALL_DEFINEx
#ifndef __SYSCALL_DEFINEx
#define __SYSCALL_DEFINEx(x, name, ...) \
__diag_push(); \
__diag_ignore(GCC, 8, "-Wattribute-alias", \
"Type aliasing is used to sanitize syscall arguments");\
asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) \
__attribute__((alias(__stringify(__se_sys##name)))); \
ALLOW_ERROR_INJECTION(sys##name, ERRNO); \
static inline long __do_sys##name(__MAP(x,__SC_DECL,__VA_ARGS__));\
asmlinkage long __se_sys##name(__MAP(x,__SC_LONG,__VA_ARGS__)); \
asmlinkage long __se_sys##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \
{ \
long ret = __do_sys##name(__MAP(x,__SC_CAST,__VA_ARGS__));\
__MAP(x,__SC_TEST,__VA_ARGS__); \
__PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \
return ret; \
} \
__diag_pop(); \
static inline long __do_sys##name(__MAP(x,__SC_DECL,__VA_ARGS__))
#endif /* __SYSCALL_DEFINEx */
经过预处理符连接符,拼接成了__do_sys_init_module函数。
所以用户侧执行 syscall(__NR_init_module, mod, len, opts) 后,最终会调用到kernel中的 __do_sys_init_module 函数。
2.1.4 用户侧syscall 到内核__do_sys_init_module 过程
按照2.1.1~2.1.3章节说明,知道了如何从insmod xxx.ko到syscall(__NR_init_module, mod, len, opts)过程,也知道了kernel后面会使用__do_sys_init_module 来响应。那么中间就只差一环了:syscall如何跳转到__do_sys_init_module 呢?
syscall实现
syscall的实现根据不同体系架构区分有很多版本,位于glibc中,使用汇编语言实现。参考glibc-2.35 aarch64版本(sysdeps/unix/sysv/linux/aarch64/syscall.S)如下:
ENTRY (syscall)
uxtw x8, w0 // 系统调用号存入x8寄存器
mov x0, x1
mov x1, x2
mov x2, x3
mov x3, x4
mov x4, x5
mov x5, x6
mov x6, x7
svc 0x0 // 触发系统调用
cmn x0, #4095
b.cs 1f
RET
1:
b SYSCALL_ERROR
PSEUDO_END (syscall)
以上代码主要实现了3个功能:
- 将系统调用号和参数放入寄存器
- 执行svc 0触发系统调用,触发CPU从用户态切换至内核态。
- 比对执行结果并返回
内核处理
在arm64体系架构中,svc 0 会出触发处理器异常同步EL 0处理,调用内核异常向量表对应处理函数,声明位于kernel entry.S中:
“kernel_ventry 0, sync // Synchronous 64-bit EL0”
SYM_CODE_START(vectors)
kernel_ventry 1, sync_invalid // Synchronous EL1t
kernel_ventry 1, irq_invalid // IRQ EL1t
kernel_ventry 1, fiq_invalid // FIQ EL1t
kernel_ventry 1, error_invalid // Error EL1t
kernel_ventry 1, sync // Synchronous EL1h
kernel_ventry 1, irq // IRQ EL1h
kernel_ventry 1, fiq_invalid // FIQ EL1h
kernel_ventry 1, error // Error EL1h
kernel_ventry 0, sync // Synchronous 64-bit EL0
kernel_ventry 0, irq // IRQ 64-bit EL0
kernel_ventry 0, fiq_invalid // FIQ 64-bit EL0
kernel_ventry 0, error // Error 64-bit EL0
#ifdef CONFIG_COMPAT
kernel_ventry 0, sync_compat, 32 // Synchronous 32-bit EL0
kernel_ventry 0, irq_compat, 32 // IRQ 32-bit EL0
kernel_ventry 0, fiq_invalid_compat, 32 // FIQ 32-bit EL0
kernel_ventry 0, error_compat, 32 // Error 32-bit EL0
#else
kernel_ventry 0, sync_invalid, 32 // Synchronous 32-bit EL0
kernel_ventry 0, irq_invalid, 32 // IRQ 32-bit EL0
kernel_ventry 0, fiq_invalid, 32 // FIQ 32-bit EL0
kernel_ventry 0, error_invalid, 32 // Error 32-bit EL0
#endif
SYM_CODE_END(vectors)
kernel_ventry为汇编宏,各kernel版本也存在差异,5.10 实现如下
.macro kernel_ventry, el, label, regsize = 64
.align 7
.Lventry_start\@:
.if \el == 0
/*
* This must be the first instruction of the EL0 vector entries. It is
* skipped by the trampoline vectors, to trigger the cleanup.
*/
b .Lskip_tramp_vectors_cleanup\@
.if \regsize == 64
mrs x30, tpidrro_el0
msr tpidrro_el0, xzr
.else
mov x30, xzr
.endif
.Lskip_tramp_vectors_cleanup\@:
.endif
sub sp, sp, #S_FRAME_SIZE
#ifdef CONFIG_VMAP_STACK
/*
* Test whether the SP has overflowed, without corrupting a GPR.
* Task and IRQ stacks are aligned so that SP & (1 << THREAD_SHIFT)
* should always be zero.
*/
add sp, sp, x0 // sp' = sp + x0
sub x0, sp, x0 // x0' = sp' - x0 = (sp + x0) - x0 = sp
tbnz x0, #THREAD_SHIFT, 0f
sub x0, sp, x0 // x0'' = sp' - x0' = (sp + x0) - sp = x0
sub sp, sp, x0 // sp'' = sp' - x0 = (sp + x0) - x0 = sp
b el\()\el\()_\label
0:
/*
* Either we've just detected an overflow, or we've taken an exception
* while on the overflow stack. Either way, we won't return to
* userspace, and can clobber EL0 registers to free up GPRs.
*/
/* Stash the original SP (minus S_FRAME_SIZE) in tpidr_el0. */
msr tpidr_el0, x0
/* Recover the original x0 value and stash it in tpidrro_el0 */
sub x0, sp, x0
msr tpidrro_el0, x0
/* Switch to the overflow stack */
adr_this_cpu sp, overflow_stack + OVERFLOW_STACK_SIZE, x0
/*
* Check whether we were already on the overflow stack. This may happen
* after panic() re-enables interrupts.
*/
mrs x0, tpidr_el0 // sp of interrupted context
sub x0, sp, x0 // delta with top of overflow stack
tst x0, #~(OVERFLOW_STACK_SIZE - 1) // within range?
b.ne __bad_stack // no? -> bad stack pointer
/* We were already on the overflow stack. Restore sp/x0 and carry on. */
sub sp, sp, x0
mrs x0, tpidrro_el0
#endif
b el\()\el\()_\label
.org .Lventry_start\@ + 128 // Did we overflow the ventry slot?
.endm
此处便不再赘述了,以上代码经过一系列地址,寄存器和堆栈指针处理后,进入函数跳转,其中el=0, label=sync:
b el()\el()_\label === > 对应el0_sync
查看el0_sync实现,进一步执行el0_sync_handle后返回用户空间,如下:
SYM_CODE_START_LOCAL_NOALIGN(el0_sync)
kernel_entry 0
mov x0, sp
bl el0_sync_handler
b ret_to_user
SYM_CODE_END(el0_sync)
从el0_sync_handler开始调用就为C语言函数了,相对比较容易阅读了,这个过程参考小结部分。
小结
用户侧syscall 到内核__do_sys_init_module 过程有点复杂,涉及汇编、指令集、体系架构,不再赘述了。调用流程为:
syscall -> svc 0 -> cpu el0 sync -> “kernel_ventry 0, sync” -> el0_sync -> el0_sync_handler -> do_el0_svc -> el0_svc_common -> invoke_syscall -> __invoke_syscall -> syscall_table[array_index_nospec(scno, __NR_syscalls)] -> __arm64_sys_finit_module -> __do_sys_finit_module
最后,__do_sys_finit_module定义在 "2.2 内核侧实现"章节中再进一步展开。
2.2 内核侧实现
内核侧insmod syscall 对应处理函数为__do_sys_init_module和__do_sys_finit_module(kernel/module.c),那么又是如何进一步调用到ko driver probe呢?
虽然存在init_module和finit_module两个入口,但再此处之后又都汇聚到了load_module函数,如下:
SYSCALL_DEFINE3(init_module, void __user *, umod,
unsigned long, len, const char __user *, uargs)
{
int err;
struct load_info info = { };
err = may_init_module();
if (err)
return err;
pr_debug("init_module: umod=%p, len=%lu, uargs=%p\n",
umod, len, uargs);
err = copy_module_from_user(umod, len, &info);
if (err)
return err;
return load_module(&info, uargs, 0);
}
SYSCALL_DEFINE3(finit_module, int, fd, const char __user *, uargs, int, flags)
{
struct load_info info = { };
void *hdr = NULL;
int err;
err = may_init_module();
if (err)
return err;
pr_debug("finit_module: fd=%d, uargs=%p, flags=%i\n", fd, uargs, flags);
if (flags & ~(MODULE_INIT_IGNORE_MODVERSIONS
|MODULE_INIT_IGNORE_VERMAGIC))
return -EINVAL;
err = kernel_read_file_from_fd(fd, 0, &hdr, INT_MAX, NULL,
READING_MODULE);
if (err < 0)
return err;
info.hdr = hdr;
info.len = err;
return load_module(&info, uargs, flags);
}
load_module进一步调用do_init_module和do_one_initcall:
/*
* Allocate and load the module: note that size of section 0 is always
* zero, and we rely on this for optional sections.
*/
static int load_module(struct load_info *info, const char __user *uargs,
int flags)
{
...
/*
* Now we've got everything in the final locations, we can
* find optional sections.
*/
err = find_module_sections(mod, info);
if (err)
goto free_unload;
err = check_module_license_and_versions(mod);
if (err)
goto free_unload;
/* Set up MODINFO_ATTR fields */
setup_modinfo(mod, info);
/* Fix up syms, so that st_value is a pointer to location. */
err = simplify_symbols(mod, info);
if (err < 0)
goto free_modinfo;
err = apply_relocations(mod, info);
if (err < 0)
goto free_modinfo;
err = post_relocation(mod, info);
if (err < 0)
goto free_modinfo;
flush_module_icache(mod);
/* Setup CFI for the module. */
cfi_init(mod);
...
err = prepare_coming_module(mod);
if (err)
goto bug_cleanup;
/* Module is ready to execute: parsing args may do that. */
after_dashes = parse_args(mod->name, mod->args, mod->kp, mod->num_kp,
-32768, 32767, mod,
unknown_module_param_cb);
...
/* Link in to sysfs. */
err = mod_sysfs_setup(mod, info, mod->kp, mod->num_kp);
if (err < 0)
goto coming_cleanup;
...
return do_init_module(mod);
}
static noinline int do_init_module(struct module *mod)
{
...
/* Start the module */
if (mod->init != NULL)
ret = do_one_initcall(mod->init);
if (ret < 0) {
goto fail_free_freeinit;
}
...
}
int __init_or_module do_one_initcall(initcall_t fn)
{
...
ret = fn();
...
}
可以看到最终将mod->init传入do_one_initcall()函数并调用,mod->init是ko driver中通过module_init(xxx_init)声明的函数。之后的流程就和标准驱动注册一样了,便不再赘述,完整的调用关系放在总结部分。
2.3 总结
insmod完整流程涉及到了应用程序,glibc,汇编,CPU指令集和体系结构,中断向量表,汇编宏,SYSCALL_DEFINE宏,kernel处理。其中碍于篇幅没有详细展开SYSCALL_DEFINE0和SYSCALL_DEFINE3如何把kernel函数链接为 __arm64_sys_finit_module和__do_sys_finit_module,这部分在syscalls.h和syscal_wrappler.h中。
做个总结,insmod xxx.ko完整调用关系过程如下(有空再补张图吧):
insmod xxx.ko ->
kmod xxx.ko ->
kmod main() ->
handle_kmod_commands ->
do_insmod ->
kmod_module_insert_module ->
finit_module ->
syscall(__NR_finit_module, fd, uargs, flags) ->
svc 0 ->
cpu el0 sync ->
“kernel_ventry 0, sync” ->
el0_sync ->
el0_sync_handler ->
do_el0_svc ->
el0_svc_common ->
invoke_syscall ->
__invoke_syscall ->
syscall_table[array_index_nospec(scno, __NR_syscalls)] ->
__arm64_sys_finit_module ->
__do_sys_finit_module ->
load_module ->
do_init_module ->
do_one_initcall ->
mod->init ->
xxx_init(driver module_init注册函数) ->
__platform_driver_register ->
driver_register ->
bus_add_driver ->
driver_attach ->
bus_for_each_dev ->
__driver_attach ->
device_driver_attach ->
driver_probe_device ->
really_probe ->
platform_drv_probe ->
xxx_probe
至此ko方式打包和使用driver完整probe过程就讲完了,欢迎交流。















 2168
2168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









