







文章目录
1. 硬件基础功能简介
首先要了解一个概念,DMAC是个独立的IP,通常集成在SOC芯片中,并不属于CPU的一部分。
DMA技术在音视频传输、网络通讯、数据存储领域有着广泛应用。
1.1 DMA技术简介
DMA(Direct Memory Access, 直接内存访问)是一种计算机系统中用于实现高效数据传输的技术。它允许数据在外设和内存之间直接传输,而无需CPU的干预和数据复制。DMA控制器是一种专用的硬件设备,它可以直接访问系统内存和外设,完成数据的传输。当需要进行数据传输时,CPU只需配置DMA控制器的参数,并将控制权交给DMA控制器,然后就可以继续执行其他任务,而不需要参与具体的数据传输过程。
2.1 DW_axi_dmac(示例)
DW_axi_dmac是一款高度可配置、可编程、高性能、多master、多通道的DMA控制器,以axi作为数据传输的总线接口。
具有如下特点:
- 仅支持单向数据传输
- 支持多种DMA传输模式,包括:M2M(Memory to Memory), M2P(Memory to Peripheral), P2M, P2P
结构图如下:
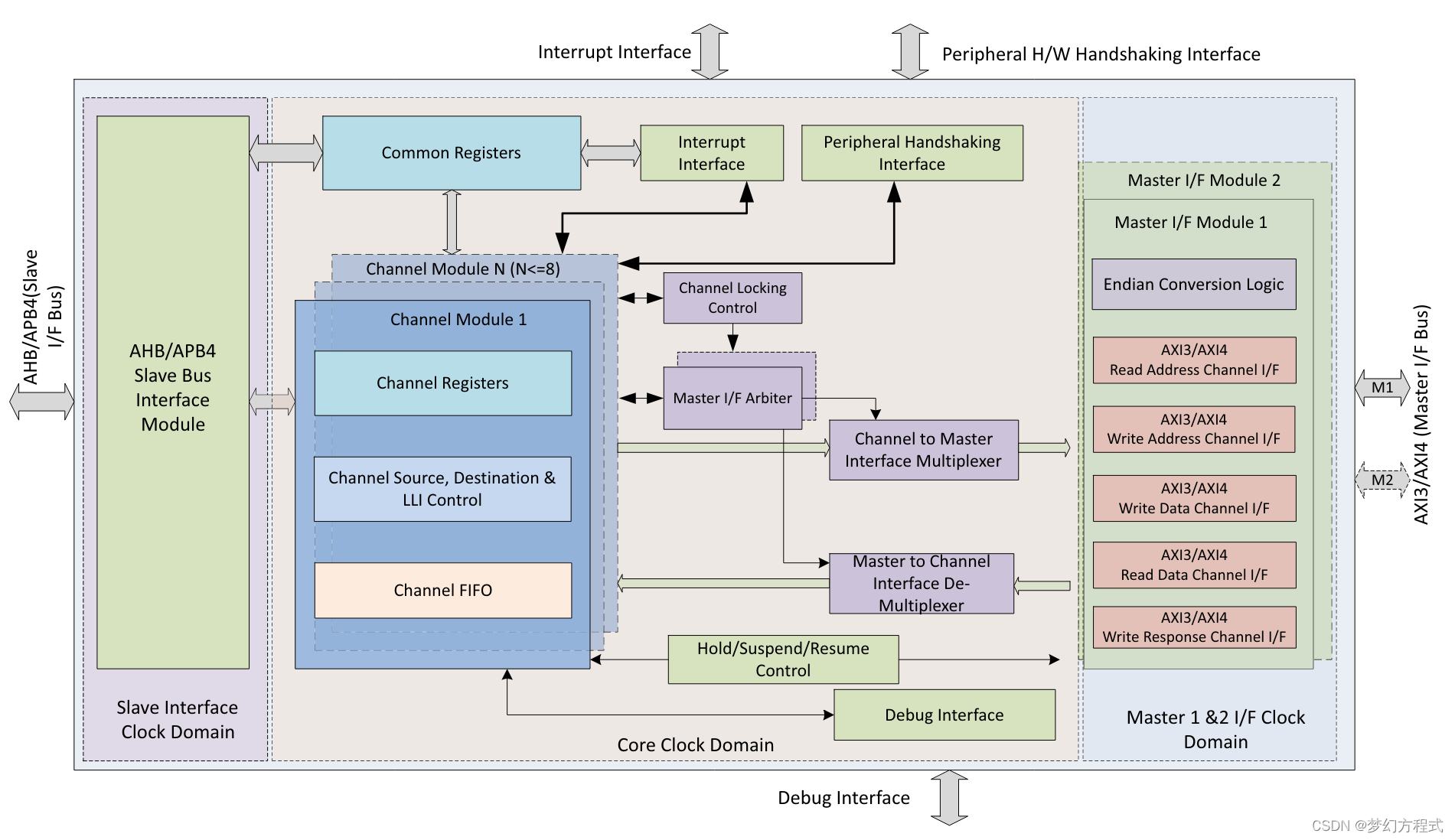
2.1.1 数据流
dmac工作流程为:通过axi从源设备读数据到FIFO,再写入目标设备中。当外设为memory情况,不需要使用握手接口。数据传输完成后,关闭通道并产生中断。
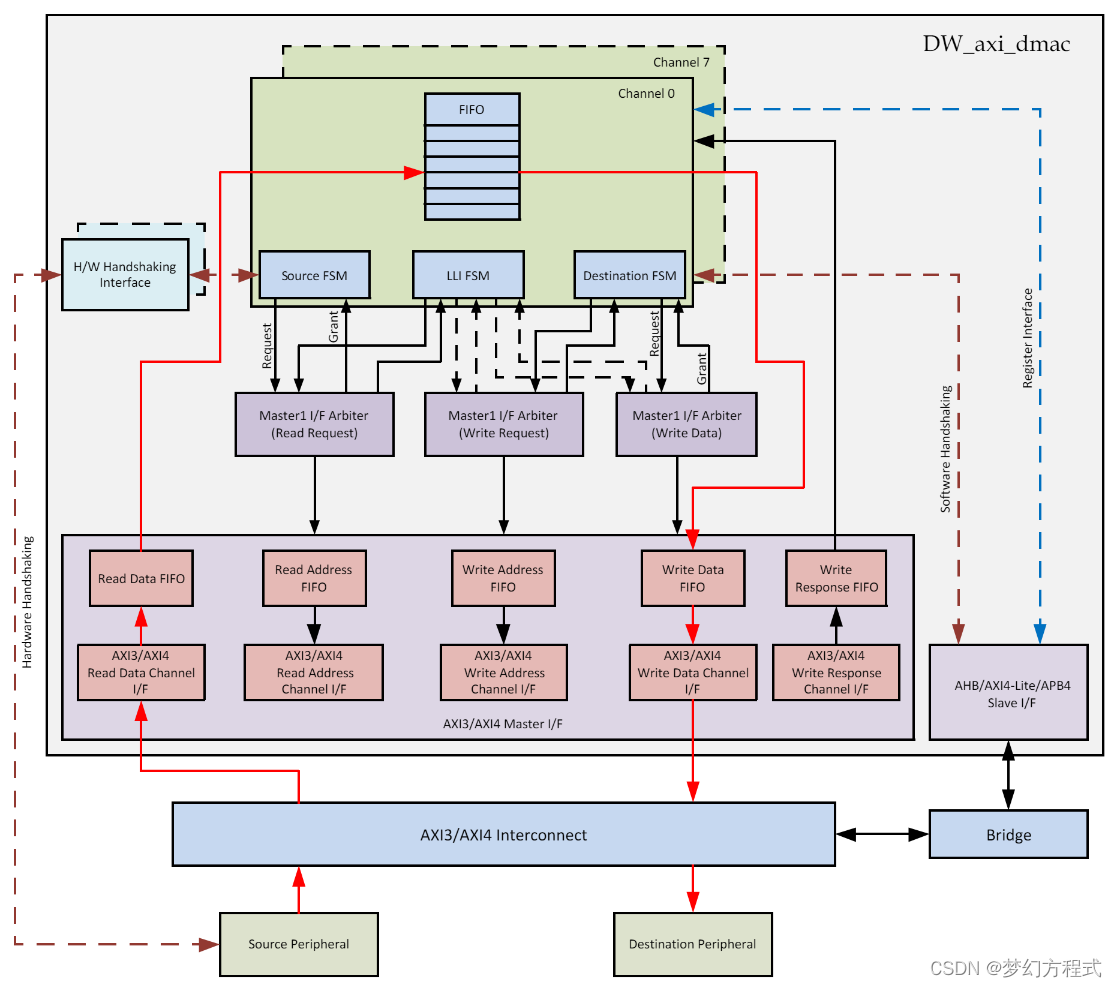
Slave I/F: 用于dmac内部寄存器的访问
Master I/F: 实现AXI总线上的数据传输
2. 驱动梳理
2.1 dmac 驱动框架
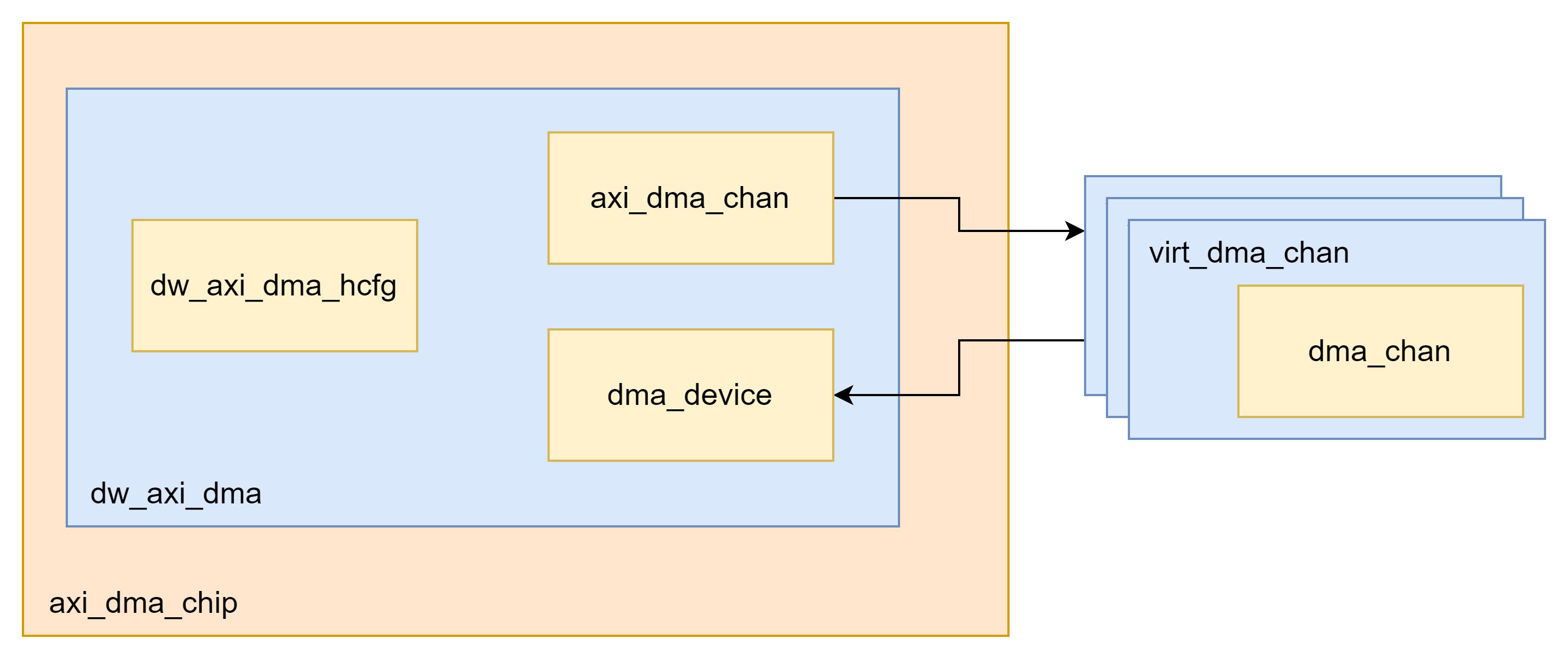
DW_axi_dmac 分为几个部分:
- axi_dma_chip:IP的抽象,包含寄存器映射、dts参数、中断注册
- dw_axi_dma:驱动抽象,包含dmac参数配置,dma设备抽象、dma channel抽象
- dw_axi_dma_hcfg:dmac参数配置,来自dts解析
- axi_dma_chan:当前提交处理的dma channel抽象
- dma_device:dma设备抽象,包含dma处理函数,配置,注册的dma channel列表
- dma_chan:所关联的slave设备dma通道
2.2 dma client 初始化
dma client初始化主要是进行dma chan的申请和配置,参考代码:
static int shm_dma_init(struct shm_device *pmemory_dev)
{
struct dma_chan *chan = NULL;
struct dma_slave_config slave_config;
char *chn_name[2] = {"tx0", "tx1"};
int ret;
memset(&slave_config, 0, sizeof(slave_config));
slave_config.direction = DMA_MEM_TO_MEM;
chan = dma_request_slave_channel(pmemory_dev->dev, chn_name[0]);
if (!chan) {
printk("channel = %s request failed", chn_name[0]);
return -ENODEV;
}
ret = dmaengine_slave_config(chan, &slave_config);
if (ret) {
printk("channel %s config failed, ret:%d", chn_name[0], ret);
return ret;
}
pmemory_dev->chan = chan;
init_completion(&pmemory_dev->xfer_done);
return 0;
}
2.3 关键函数
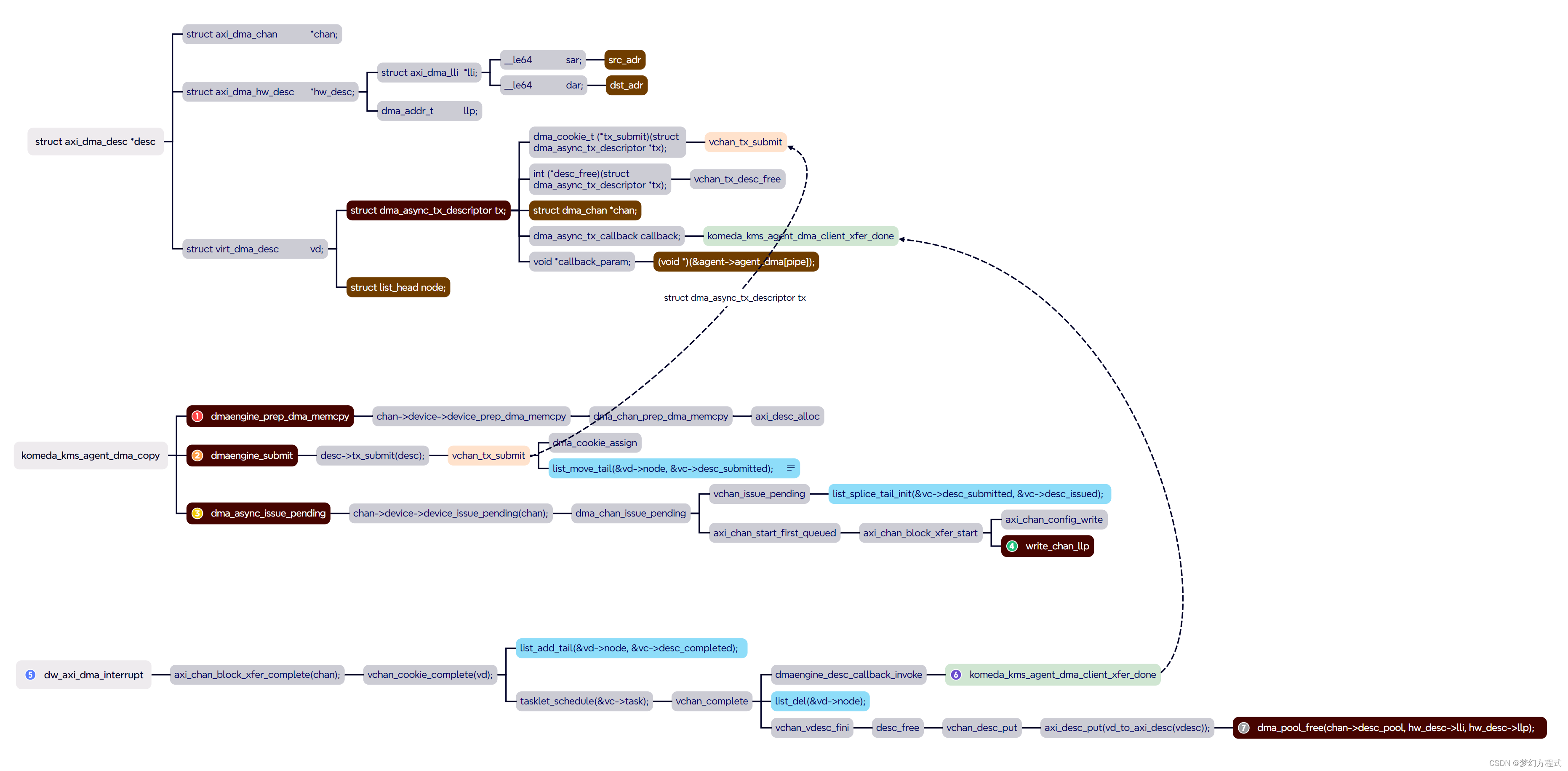
2.3.1 dmaengine_prep_dma_memcpy
调用dma_chan关联的dmac设备device_prep_dma_memcpy函数,创建并返回一个axi_dma_desc描述符,将要拷贝的src和dst addr按dmac位宽拆分成多个子包,完成后返回struct dma_async_tx_descriptor成员。
2.3.2 dmaengine_submit
调用axi_dma_desc提交函数tx_submit,将desc提交至virt_dma_chan的desc_submitted列表。
2.3.3 dma_async_issue_pending
调用dma_chan关联的dmac设备device_issue_pending函数,将desc提交至DMAC硬件处理。
2.3.4 write_chan_llp
将axi_dma_hw_desc提交至DMAC硬件处理。
2.3.5 dw_axi_dma_interrupt
DMAC中断处理函数,DMAC硬件处理完成后,通知CPU处理完成。
2.3.6 komeda_kms_agent_dma_client_xfer_done
client侧回调函数,调用其通知slave设备dma拷贝完成。
2.3.7 dma_pool_free
释放dma内存,将其归还至dma内存池。
2.4 dma transfer work flow
流程为:
- 调用
dmaengine_prep_dma_memcpy创建dma desc描述符 - 提交dma desc至virt_dma_chan的desc_submitted列表
- 调用dma_async_issue_pending将dma desc合并至desc_issued列表,发起dma事物
- 将dma desc提交至DMAC硬件。
- DMAC处理完成,触发中断回调函数
- 通过tasklet进一步处理,通知slave设备dma传输完成
3. 性能分析
3.1 测试结果
这里对比A55、A76、DMAC对于不同size数据的拷贝效率:
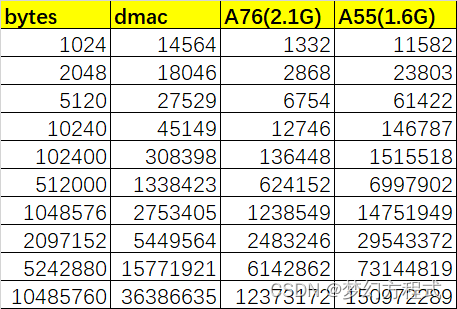
以上是1k、2k、5k、10k、100k、500k、1m、2m、5m、10m大小数据的处理时间对比,单位为ns。
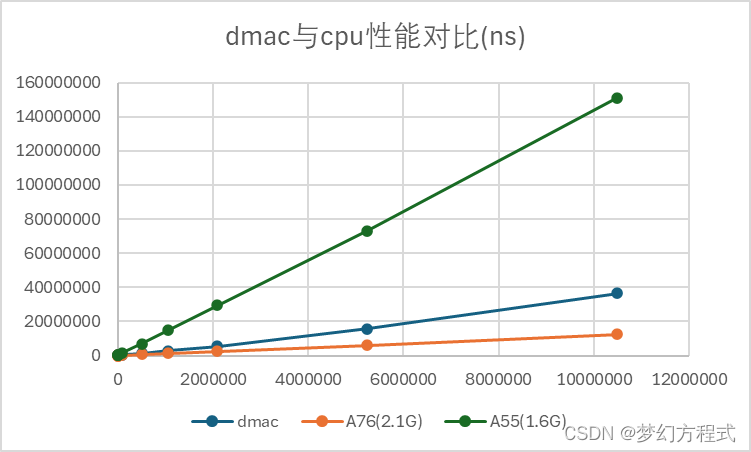
上图可以看到,数据拷贝时间与数据量正相关,基本是线性的:A76性能 > dmac > A55。
尽管A76性能要由于dmac,但是dmac在跨系统拷贝和节省cpu负载上仍有非常重要的意义。
3.2 测试程序示例
3.1 dma client 初始化
static int shm_dma_init(struct shm_device *pmemory_dev)
{
struct dma_chan *chan = NULL;
struct dma_slave_config slave_config;
char *chn_name[2] = {"tx0", "tx1"};
int ret;
memset(&slave_config, 0, sizeof(slave_config));
slave_config.direction = DMA_MEM_TO_MEM;
chan = dma_request_slave_channel(pmemory_dev->dev, chn_name[0]);
if (!chan) {
printk("channel = %s request failed", chn_name[0]);
return -ENODEV;
}
ret = dmaengine_slave_config(chan, &slave_config);
if (ret) {
printk("channel %s config failed, ret:%d", chn_name[0], ret);
return ret;
}
pmemory_dev->chan = chan;
init_completion(&pmemory_dev->xfer_done);
return 0;
}
3.2 提交dma请求
static void shm_dma_client_xfer_done(void *args)
{
struct shm_device *pmemory_dev = (struct shm_device *)args;
complete(&pmemory_dev->xfer_done);
// printk("dma chan copy done");
}
static void *
dma_alloc_continue(struct device *dev, size_t size,
dma_addr_t *dma_addr, gfp_t gfp)
{
unsigned long attrs = DMA_ATTR_WRITE_COMBINE |
DMA_ATTR_FORCE_CONTIGUOUS;
if (gfp & __GFP_NOWARN)
attrs |= DMA_ATTR_NO_WARN;
return dma_alloc_attrs(dev, size, dma_addr, gfp, attrs);
}
static int shm_dma_test(struct shm_device *pmemory_dev)
{
struct dma_async_tx_descriptor *desc = NULL;
dma_cookie_t cookie;
__u64 start_ns;
__u64 end_ns;
__u64 t0, t1;
int ret;
int i;
/* 1. alloc src */
pmemory_dev->src_vaddr = dma_alloc_continue(pmemory_dev->dev, DMA_TEST_SIZE, &pmemory_dev->src_paddr,
GFP_KERNEL | __GFP_NOWARN);
if (!pmemory_dev->src_vaddr) {
printk("failed to allocate buffer with size %zu", DMA_TEST_SIZE);
return -ENOMEM;
}
memset(pmemory_dev->src_vaddr, 0x11, DMA_TEST_SIZE);
/* 2. alloc dst */
pmemory_dev->dst_vaddr = dma_alloc_continue(pmemory_dev->dev, DMA_TEST_SIZE, &pmemory_dev->dst_paddr,
GFP_KERNEL | __GFP_NOWARN);
if (!pmemory_dev->dst_vaddr) {
printk("failed to allocate buffer with size %zu", DMA_TEST_SIZE);
return -ENOMEM;
}
memset(pmemory_dev->dst_vaddr, 0x22, DMA_TEST_SIZE);
start_ns = ktime_get_ns();
for (i = 0; i < DMA_TEST_COUNT; i++)
{
/* 3. prepare dma memcpy */
desc = dmaengine_prep_dma_memcpy(pmemory_dev->chan,
pmemory_dev->dst_paddr,
pmemory_dev->src_paddr,
DMA_TEST_SIZE,
DMA_PREP_INTERRUPT);
// t0 = ktime_get_ns();
// printk("stage 0 cost: %llu ns\n", t0 - start_ns);//stage 0 cost: 5461 ns
desc->callback = shm_dma_client_xfer_done;
desc->callback_param = (void *)(pmemory_dev);
cookie = dmaengine_submit(desc);
ret = dma_submit_error(cookie);
if (ret) {
printk("channel submit failed");
return ret;
}
// t1 = ktime_get_ns();
// printk("stage 1 cost: %llu ns\n", t1 - t0);//stage 1 cost: 7424 ns
dma_async_issue_pending(pmemory_dev->chan);
// t0 = ktime_get_ns();
// printk("stage 2 cost: %llu ns\n", t0 - t1);//stage 2 cost: 7595 ns
/* 4. wait for dma memcpy */
ret = wait_for_completion_timeout(&pmemory_dev->xfer_done, HZ);
if (ret == 0) {
printk("dma chan timed out");
}
}
end_ns = ktime_get_ns();
printk("%s: dma copy %zu bytes cost: %llu ns\n", __func__,
DMA_TEST_SIZE, (end_ns - start_ns)/DMA_TEST_COUNT);
// dma copy 1024 bytes cost: 59733 ns
return 0;
}
3.3 cpu memcpy处理
int shm_a55_memcpy_test(void *data)
{
struct shm_device *pmemory_dev = data;
__u64 start_ns;
__u64 end_ns;
int i;
printk("%s: start running\n", __func__);
start_ns = ktime_get_ns();
for (i = 0; i < DMA_TEST_COUNT; i++)
{
memcpy(pmemory_dev->src_vaddr, pmemory_dev->dst_vaddr, DMA_TEST_SIZE);
}
end_ns = ktime_get_ns();
printk("%s: a55 cpu memcpy copy %zu bytes cost: %llu ns\n", __func__,
DMA_TEST_SIZE, (end_ns - start_ns)/DMA_TEST_COUNT);
return 0;
}
int shm_a76_memcpy_test(void *data)
{
struct shm_device *pmemory_dev = data;
__u64 start_ns;
__u64 end_ns;
int i;
printk("%s: start running\n", __func__);
start_ns = ktime_get_ns();
for (i = 0; i < DMA_TEST_COUNT; i++)
{
memcpy(pmemory_dev->src_vaddr, pmemory_dev->dst_vaddr, DMA_TEST_SIZE);
}
end_ns = ktime_get_ns();
printk("%s: a76 cpu memcpy copy %zu bytes cost: %llu ns\n", __func__,
DMA_TEST_SIZE, (end_ns - start_ns)/DMA_TEST_COUNT);
return 0;
}
int cpu_memcpy_test()
{
...
shm_dma_test(pmemory_dev);
pmemory_dev->a55_thread = kthread_create(shm_a55_memcpy_test, pmemory_dev, "shm-%d", 0);
pmemory_dev->a76_thread = kthread_create(shm_a76_memcpy_test, pmemory_dev, "shm-%d", 1);
/*A76:0,1,2,3 A55:4,5*/
memset(&mask, 0, sizeof(mask));
cpumask_set_cpu(4, &mask);
cpumask_set_cpu(5, &mask);
kthread_bind_mask(pmemory_dev->a55_thread, &mask);
dev_info(dev, "%s set a55 cpu mask done", __func__);
memset(&mask, 0, sizeof(mask));
cpumask_set_cpu(0, &mask);
cpumask_set_cpu(1, &mask);
cpumask_set_cpu(2, &mask);
cpumask_set_cpu(3, &mask);
kthread_bind_mask(pmemory_dev->a76_thread, &mask);
dev_info(dev, "%s set a76 cpu mask done", __func__);
wake_up_process(pmemory_dev->a55_thread);
wake_up_process(pmemory_dev->a76_thread);
...
}















 942
942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









