







本文包括:
- 最大熵模型简介
- 最大熵的原理
- 最大熵模型的定义
- 最大熵模型的学习
1.最大熵模型简介:
最大熵原理认为,学习概率模型时,在所有可能的概率模型(分布)中,熵最大的模型是最好的模型。通常用约束条件来确定概率模型的集合,所以,最大熵原理也可以表述为在满足约束条件的模型集合中选取熵最大的模型。
离散随机变量X的概率分布是P(X),则其熵是:
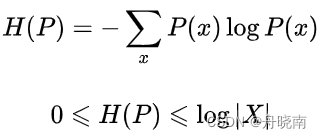
式中,|X|是X的取值个数,当且仅当X的分布是均匀分布时右边的等号成立。这就是说,当X服从均匀分布时,熵最大。
2.最大熵的原理:
假设X有5个取值,满足以下约束条件(先验信息):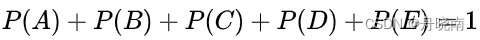
满足这个约束条件的概率分布有无穷多个。在没有任何其他信息的情况下,我们还是需要对概率分布进行估计,此时我们可以认为这个分布中取各个值的概率是相等的,即P(A)=P(B)=P(C)=P(D)=P(E)=1/5,同样也是因为没有其它的信息(约束条件),因此等概率的判断是合理的。
有时,能从一些先验知识中得到一些对概率值的约束条件,例如: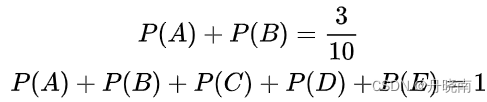
满足这两个约束条件的概率分布仍然有无穷多个。在缺少其他信息的情况下,可以认为A与B是等概率的,C,D与E是等概率的。
3.最大熵模型的定义:
我们可以首先考虑模型应该满足的条件,即约束条件。给定训练数据集,可以确定联合分布P(X,Y)的经验分布和边缘分布P(X)的经验分布,两者都可以通过训练集算出来。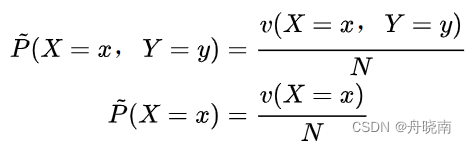
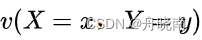 表示训练数据中样本(x,y)出现的频数,
表示训练数据中样本(x,y)出现的频数,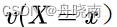 表示训练数据中输入x出现的频数,N表示样本容量。在P上面加一个小波浪(一些文章中是加一个小横杠),代表这个分布是我们根据已有的训练集信息得到的,是经验分布,但不是真实分布。
表示训练数据中输入x出现的频数,N表示样本容量。在P上面加一个小波浪(一些文章中是加一个小横杠),代表这个分布是我们根据已有的训练集信息得到的,是经验分布,但不是真实分布。
用特征函数描述输入x和输出y之间的某一个事实: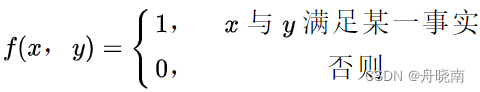
特征函数f(x,y)在训练集上关于联合经验分布的期望值: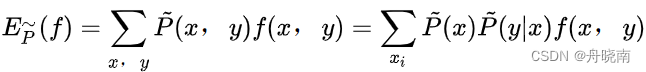
上式中出现的分布都是经验分布,说明 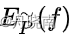 仅与训练集有关,并不是真实情况。
仅与训练集有关,并不是真实情况。
那么真实情况应该是什么样的呢?其实只需要将经验分布转变成真实的分布就行了: 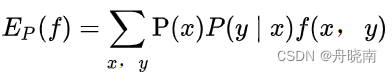
上式是特征函数f(x,y)在模型上关于模型P(YIX)与P(x)的期望值,我们需要求的模型即P(YIX),但是其中还存在着一个未知分布P(x)。由于我们并不知道真实情况的P(x)是什么,我们可以使用P(x)的经验分布代替真实的P(x)来对真实情况进行近似表示,于是上式转变为: 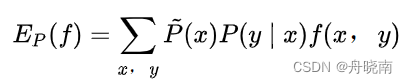
现在我们有了一个针对训练集的期望 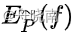
,和针对模型的期望 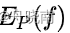 ,此时,只需要让两式相等(使在总体中出现的概率等于在样本中出现的概率),就能够让模型拟合训练集,并最终求得我们的模型:
,此时,只需要让两式相等(使在总体中出现的概率等于在样本中出现的概率),就能够让模型拟合训练集,并最终求得我们的模型:

即:
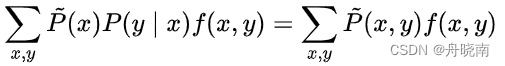
上式中P(y|x)为模型,两个经验分布可以从训练集中得到,f(x, y)是特征函数。
上式即为一个约束条件,假如有n个特征函数fi(x,y),i=1,2,…,n,那么就有n个约束条件。除此之外还有一个必定存在的约束,即模型概率之和等于1: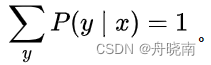 。
。
现在我们有了所有的约束条件,接着写出模型的熵的公式,就可以根据最大熵规则,在约束条件下得到模型。
定义在条件概率分布P(YIX)上的条件熵为: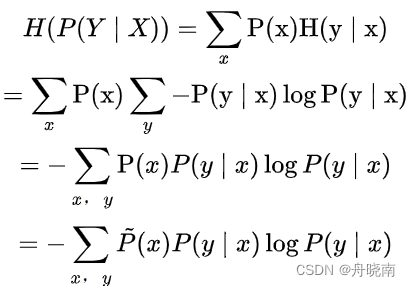
条件熵中依然使用了x的经验分布代替真实分布,式中的对数为自然对数(以e为底)。那么求解模型的问题转换为求得最大化的条件熵问题。
4.最大熵模型的学习:
最大熵模型的学习过程就是求解最大熵模型的过程。最大熵模型的学习可以形式化为约束最优化问题。最大熵模型的约束条件为: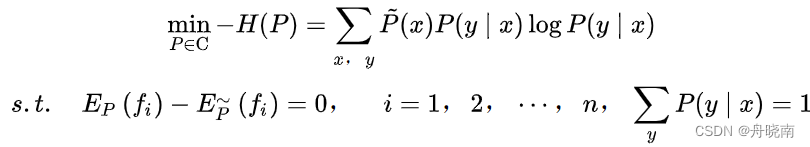
求解最大熵的方法可以使用拉格朗日乘数法,定义拉格朗日函数为: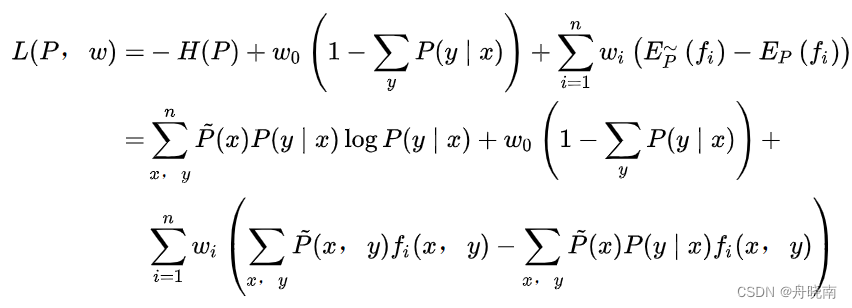
其中w0和wi都是拉格朗日乘数法中引入的未知参数。原始的最优化问题为: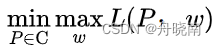
其中C是所有符合要求的模型的集合。上式认为P为常数并求得最优的参数w,再依此最小化L,实际上就是最小化-H(P),也就是最大化H(P),求得最大熵模型P(Y|X)。
这里有一个疑问,就是为什么要首先最大化L呢?
拉格朗日乘数法的本质是将原本的约束通过在L之中引入未知参数来去除,既然在L中已经去除了约束,那么在上式中,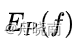 可能不等于
可能不等于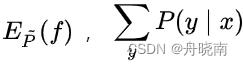 , 也有可能不等于1。如果是这样的话,我们可以通过直接调整引入的未知参数w0和wi来使L等于无穷小,那么
, 也有可能不等于1。如果是这样的话,我们可以通过直接调整引入的未知参数w0和wi来使L等于无穷小,那么
小化问题就没有必要解了,也就不存在最优的模型P(Y|X)了。
所以我们首先需要最大化来规避这个问题。
这里非常感谢这篇博文:https://blog.csdn.net/resume_f/article/details/104754865。
接下来,由于L(P,w)是P的凸函数(关于凸函数优化,可自行查阅资料),为了计算方便,我们可以将最优化问题转换为它的对偶问题:
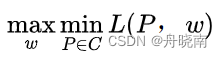
现在,我们可以对 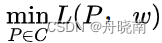 进行计算了。
进行计算了。
具体地,求L(P,w)对P(y|x)的偏导数:
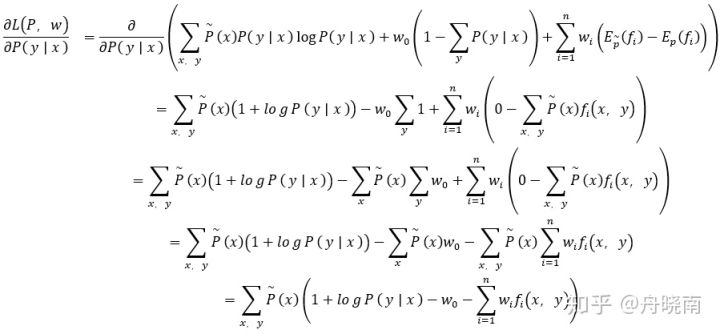
在上式的第三个等式中,运用到 
现在令导数为0,又因为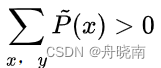 ,可得:
,可得: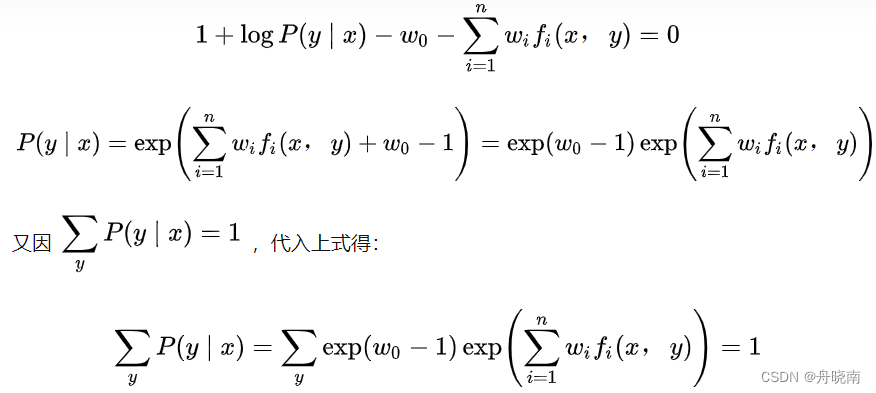
又因 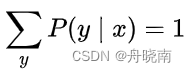 ,代入上式得:
,代入上式得: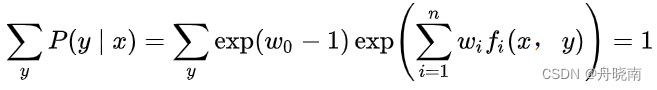
则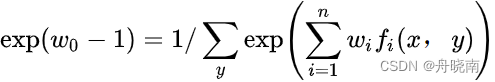 ,并设其分母为
,并设其分母为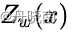 ,称为规范化因子。
,称为规范化因子。
于是: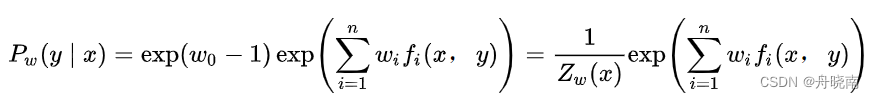
这就是对偶问题的内部最小化问题的解,也是我们需要的模型的估计。现在,将上式带回至拉格朗日函数,求解对偶问题外部的极大化问题:
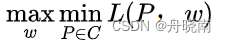
因为 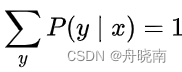 ,所以拉格朗日函数的推导为:
,所以拉格朗日函数的推导为:
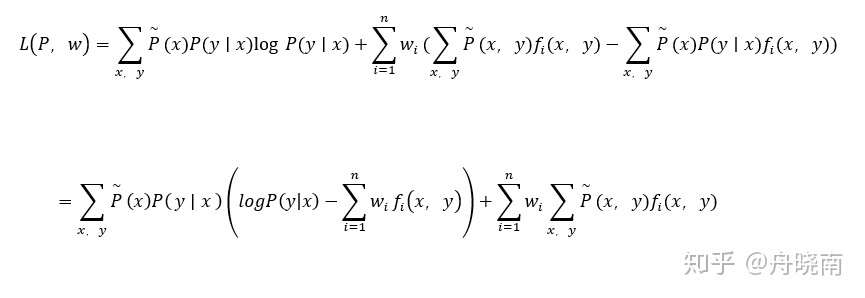
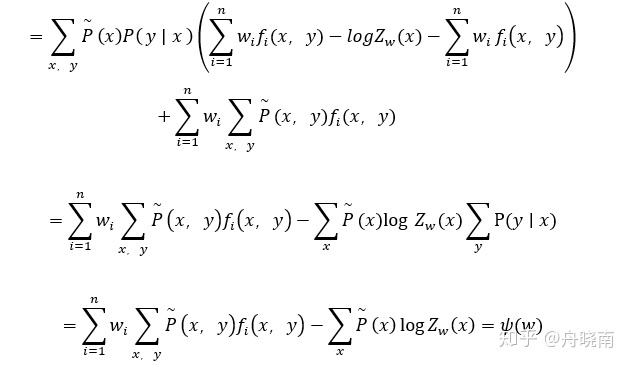
现在对每一个w求偏导,并使偏导数等于0,最终将得到非显式的解。
最后再将w的非显示解代入到之前求得的: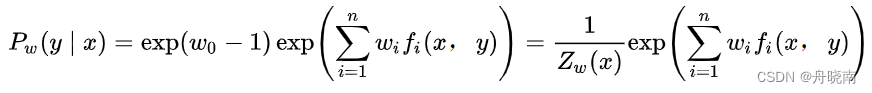
中,即可得到概率分布,也就习得了模型。
可在《统计学习方法》中查看具体的最大熵模型的解题例子。
同名公众号和知乎:舟晓南
对机器学习,深度学习,python感兴趣,欢迎关注专栏,学习笔记已原创70+篇,持续更新中~ ^_^
学习笔记:数据分析,机器学习,深度学习![]() https://www.zhihu.com/column/c_1274454587772915712
https://www.zhihu.com/column/c_1274454587772915712
专栏文章举例:
【机器学习】关于逻辑斯蒂回归,看这一篇就够了!解答绝大部分关于逻辑斯蒂回归的常见问题,以及代码实现 - 知乎 (zhihu.com)
关于 python 二三事![]() https://www.zhihu.com/column/c_1484952401395941377
https://www.zhihu.com/column/c_1484952401395941377
专栏文章举例:
记录一下工作中用到的少有人知的pandas骚操作,提升工作效率 - 知乎 (zhihu.com)
关于切片时不考虑最后一个元素以及为什么从0开始计数的问题 - 知乎 (zhihu.com)
关于转行:
舟晓南:如何转行和学习数据分析 | 工科生三个月成功转行数据分析心得浅谈
舟晓南:求职数据分析师岗位,简历应该如何写?|工科生三个月成功转行数据分析心得浅谈
我建了个数据分析,机器学习,深度学习的群~ 需要学习资料,想要加入社群均可私信~
在群里我会不定期分享各种数据分析相关资源,技能学习技巧和经验等等~
详情私信,一起进步吧!















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









