






最大熵原理
原理:在满足约束条件的模型集合中选取熵最大的模型。
思路:从训练数据T中抽取若干特征,这些特征在T上关于经验分布的期望与它们在模型中关于p(x,y)的数学期望相等,这样,一个特征就对应一个约束。
假设分类模型是一个条件概率分布 𝑃(𝑌|𝑋), 𝑋 ∈ 𝒳 ⊆ 𝑅𝑛表示输入,𝑌 ∈ 𝒴表条件概
率 𝑃(𝑌|𝑋)输出 𝑌。给定一个训练数据集𝑇 = {(𝑥1,𝑦1), (𝑥2,𝑦2), ⋯ , (𝑥𝑁,𝑦𝑁)}。
1.考虑模型满足的条件。
联合分布𝑃(𝑋,𝑌)的经验分布和边缘分布 𝑃(𝑋)的经验分布。
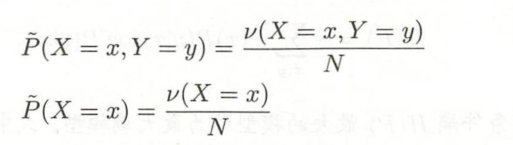
ν(𝑋 = 𝑥,𝑌 = 𝑦)表示训练数据中样本 (𝑥,𝑦) 出现的频数,
ν(𝑋 = 𝑥) 表示训练数据中输入 𝑥出现的频数,
𝑁 表示训练样本容量。
2.特征函数(feature function)𝑓(𝑥,𝑦)描述输入𝑥和输出𝑦之间的某一个事实。

3.特征函数𝑓(𝑥,𝑦) 关于经验分布𝑃̃(𝑋,𝑌)的期望值表示为:
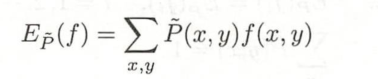
特征函数𝑓(𝑥, 𝑦)关于模型 𝑃(𝑌|𝑋)与经验分布𝑃̃(𝑋)的期望值表示为:
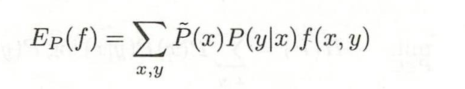
如果模型能够获取训练数据中的信息,那么就可以假设这两个期望值相等。即
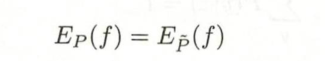
或
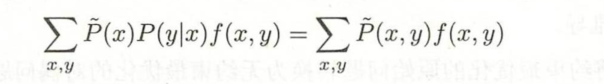
定义:假设满足所有约束条件的模型集合为
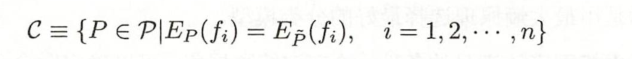
定义在条件概率分布 𝑃(𝑌|𝑋)上的条件熵为
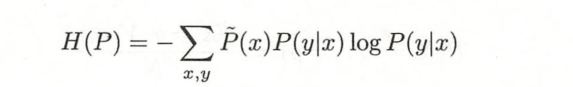
则模型集合C中条件嫡 H ( P ) H(P) H(P)最大的模型称为最大嫡模型。式中的对数为自然对数。
对于给定的训练数据集 𝑇 = {(𝑥1, 𝑦1), (𝑥2, 𝑦2), ⋯ , (𝑥𝑁, 𝑦𝑁)}以及特征函数𝑓𝑖(𝑥, 𝑦), 𝑖 = 1,2, ⋯ , 𝑛,
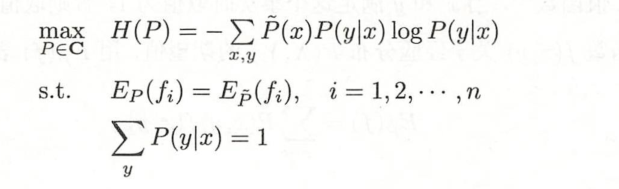
将求最大值问题改写为等价的求最小值问题:
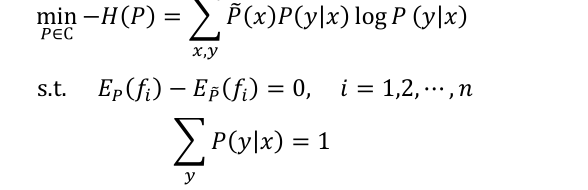
利用拉格朗日乘子法把最大熵模型由一个带约束的最优化问题转化为一个与之等价的无约束的最优化问题。通过求解对偶问题求解原始问题。
推导过程:
















 775
775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









