










Google Spanner是谷歌的全球级分布式数据库(Golbally-Distributed Database)。Spanner的扩展性达到了全球级,可以扩展到数百个数据中心,数百万台机器,上万亿行数据,除了夸张的可扩展性之外,他还能通过同步复制和多版本控制MVCC来满足外部一致性。支持垮数据中心的事务。是一个大规模分布式技术和传统关系型数据库技术的完美融合。
架构
Spanner的模型和MegaStore系统较为相似
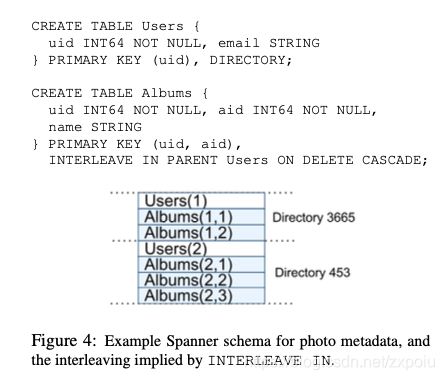
如图,Spanner的表示层次化的,最底层的表是目录表(Directory),可以通过INTERLEAVE IN PARENT来表示层次关系。相当于Megastore中的EG。同一个目录会分配到同一台机器(当然,同一个目录会复制多分以达到容错性)。因此,针对同一个目录的读写事务大部分情况下都不会设计跨机操作。
Spanner构建在Google下一代分布式文件系统Colossus上,由于其全球性的部署理念,它引入了很多其他分布式系统没有的概念:
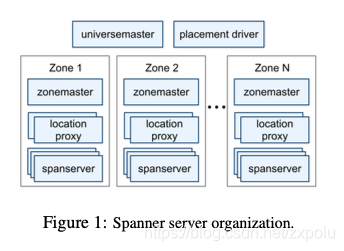
- Universe:一个spanner部署实例称为一个Universe。全世界只有三个Universe:一个开发,一个测试,一个线上
- Zones:每个zone属于一个数据中心,zone内部网路通信代价较低。每一个zone由一个zone master和100~1000个span server组成。zone master有一个热备。
Spanner包含以下组件:
Universe Master:监控Universe里Zone级别里的信息Placement Driver:提供跨Zone的数据迁移能力Location Proxy:提供获取数据位置信息的能力Spanserver:提供存储服务,功能上相当于Bigtable系统中的TabletServer- 每一个
Spanserver上有100-1000个tablet,和Bigtable中tablet类似,spanner中的tablet也包含时间戳
- 每一个
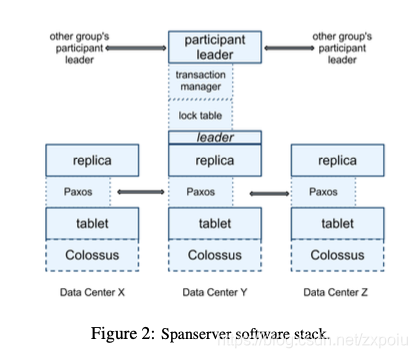
复制与一致性
每个zone都运行着一套Colossus提供存储服务。每个spanserver中的tablet都维护者自己的paxos state machine,通过paxos选出一个leader,leader有10秒钟的lease时间。
Spanner垮数据中心的一致性也是通过paxos来保证的。另外每个tablet的主副本可以通过表级锁的方式进行并发控制。锁表可以实现单个paxos组内事务,垮paxos组的事务需要通过在主副本上的事务管理器进行,用到了两阶段提交协议。有一个paxos组的主副本成为当前垮组事务的leader协调者(coordinator leader),其他成为参与者(participant leaders)。
TrueTime
为了实现并发控制,需要给事务分配全局唯一的事务ID,在spanner这么大规模的分布式系统中,使用全球时钟同步机制TrueTime。其实现的基础是GPS和原子钟。
由于在分布式系统中,各个节点的时钟不可避免的存在误差,因此多数系统会采用一个中心节点来进行授时(例如tidb的pd),但是对于谷歌这样让数据全球分布的需求而言,使用中心化节点从延时和性能上代价太大,因此谷歌开发了TrueTime API,它提供了下面三个接口。
| Method | Return |
|---|---|
TT.now() | 返回一个范围区间[𝑒𝑎𝑟𝑙𝑖𝑒𝑠𝑡, 𝑙𝑎𝑡𝑒𝑠𝑡], 当前的真实时间位于这个区间中 |
TT.after(t) | 如果确保当前真实时间已经超过t,则返回true |
TT.before(t) | 如果确保当前真实时间还未到t,则返回true |
事务
Spanner除支持快照读外,还支持ACID事务读写操作。所有的读操作都是非阻塞、无锁的。读操作使用了多版本技术,版本号就是时钟时间。
Spanner使用TrueTime来控制并发,实现外部一致性,支持以下几种事务:
- 读写事务
- 只读事务
- 快照读,客户端提供时间戳
- 快照读,客户端提供时间范围
使用TreuTime作为事务并发控制,其核心思想在于:考虑事务A的commit操作早于事务B,要将原子钟的误差考虑进去。Spanner使用了一种成为延时提交(Commit Wait)的手段,假设原子钟的误差是ε,则事务B要在事务A提交之后再过ε的时间才能提交,这意味着写事务的时延至少是2ε
引入TrueTime的难点在于:机器时间drift引起的多机时钟无法同步,从而使得,由于不同事务参与的集群和他们的时钟不同,则使全部数据库的commit时间戳混乱,无法与真实事件发生顺序一致。所以我们需要原子钟保证机器间的时间差不超过ε,并且Coordinator选完commit时间戳之后等待ε的时间才广播commit,这样保证所有参加此事务的participant的本地时钟已经超过commit时间戳的值。
我们可以看到:Spanner由于commit等待,ε越大,写的latency越高,单线程throughput越低。
在讨论过TrueTime后,我们后面的讨论在不考虑误差的情况下进行:
- 事务只涉及一个Paxos组
- 读写事务步骤:
- 获取当前时间戳
- 执行读写操作,并将时间戳一并提交
- 只读事务步骤:
- 获取当前时间戳
- 通过MVCC获取当前应该读取的版本
- 由于快照度会自带时间戳,因此会获取指定时间戳版本的数据,而不是当前时间戳版本
- 读写事务步骤:
- 事务设计多个Paxos组:
- 读写事务需要执行两阶段提交,步骤如下:
Prepare:客户端将数据发往多个paxos的主副本,协调者主副本发起prepare,其他participant需要锁住对应的资源Commit:协调者发起Commit,让每一个participant执行commit,该事物使用协调者本地当前时间戳作为事务版本ID
- 只读事务流程在单个Paxos组内的操作同上,需要注意的是,只读事务需要保证不会读到不完整的事务,假设读到一个事务只进行到prepare阶段,需要等一会,事务提交之后才能读到争取的数据。
- 读写事务需要执行两阶段提交,步骤如下:
数据迁移
spanner系统设计的重要目标就是垮数据中心的数据可用已经重新平衡数据的能力,所以这一点在spanner上很重要。
之前讲了Directory目录是数据分区的基本单位,目录可以在paxos组之间移动,有下面几种情况会涉及目录迁移:
- 负载均衡
- 将目录迁移到和用户更近的地方,降低时延
- 把经常一起访问的目录放在同一个Paxos组(多个directory可以放在同一个paxos组中)















 1310
1310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









