







Spanner: Google’s Globally-Distributed Database
Spanner 是谷歌公司研发的、可扩展的、多版本、全球分布式、同步复制数据库。 它是第一个把数据分布在全球范围内的系统,并且支持外部一致性的分布式事务。本文描述 了 Spanner 的架构、特性、不同设计决策的背后机理和一个新的时间 API,这个 API 可以暴 露时钟的不确定性。这个 API 及其实现,对于支持外部一致性和许多强大特性而言,是非常 重要的,这些强大特性包括:非阻塞的读、不采用锁机制的只读事务、原子模式变更。
1 介绍
1)Spanner 就是一个数据库,把数据分片存储在许多 Paxos[21]状态机上,这 些机器位于遍布全球的数据中心内。
2)随着数据的变化和服务器的变化,Spanner 会自动把 数据进行重新分片,从而有效应对负载变化和处理失败。Spanner 被设计成可以扩展到几百 万个机器节点,跨越成百上千个数据中心,具备几万亿数据库行的规模。
3)Spanner 来实现高可用性
4)Spanner 的主要工作,就是管理跨越多个数据中心的数据副本。Spanner 已经从一个类 似 BigTable 的单一版本的键值存储,演化成为一个具有时间属性的多版本的数据库。数据被 存储到模式化的、半关系的表中,数据被版本化,每个版本都会自动以提交时间作为时间戳, 旧版本的数据会更容易被垃圾回收。应用可以读取旧版本的数据。Spanner支持通用的事务, 提供了基于 SQL 的查询语言
5)Spanner 提供了几个有趣的特性:第一,在数据的副本配置方面,应用可以在一个很细的粒度上进行动态控制。第二, Spanner 有两个重要的特性,很难在一个分布式数据库上实现,即 Spanner 提供了读和写操 作的外部一致性,以及在一个时间戳下面的跨越数据库的全球一致性的读操作
6)是因为 Spanner 可以为事务分配全球范围内有意义的提交时间戳,即使事务可能是分布式的。这些时间戳反映了事务序列化的顺序. 实现这种特性的关键技术就是一个新的 TrueTime API 及其实现。这个 API 可以直接暴露时钟不确定性,Spanner 时间戳的保证就是取决于这个 API 实现的界限
2 实现
一个 Spanner 部署称为一个 universe。假设 Spanner 在全球范围内管理数据,那么,将会只有可数的、运行中的 universe。我们当前正在运行一个测试用的 universe,一个部署/ 线上用的 universe 和一个只用于线上应用的 universe。
Spanner被组织成许多个zone的集合,每个zone都大概像一个BigTable服务器的部署。zone 是管理部署的基本单元。zone 的集合也是数据可以被复制到的位置的集合。当新的数 据中心加入服务,或者老的数据中心被关闭时,zone 可以被加入到一个运行的系统中,或 者从中移除。zone 也是物理隔离的单元,在一个数据中心中,可能有一个或者多个 zone, 例如,属于不同应用的数据可能必须被分区存储到同一个数据中心的不同服务器集合中。
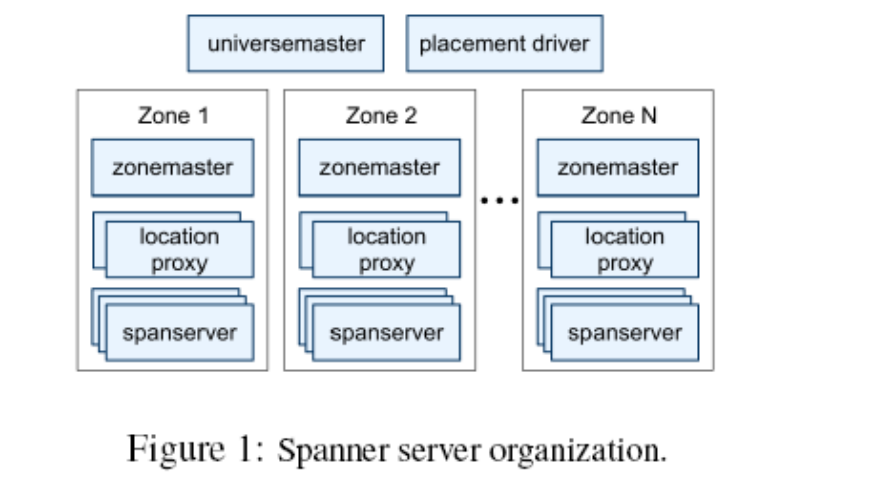
图 1 显示了在一个 Spanner 的 universe 中的服务器。一个 zone 包括一个 zonemaster,和一百至几千个 spanserver。Zonemaster 把数据分配给 spanserver,spanserver 把数据提供 给客户端。客户端使用每个 zone 上面的 location proxy 来定位可以为自己提供数据的spanserver。Universe master 和 placement driver,当前都只有一个。Universe master 主要是 一个控制台,它显示了关于 zone 的各种状态信息,可以用于相互之间的调试。Placement driver 会周期性地与 spanserver 进行交互,来发现那些需要被转移的数据,或者是为了满足 新的副本约束条件,或者是为了进行负载均衡
2.1 Spanserver 软件栈
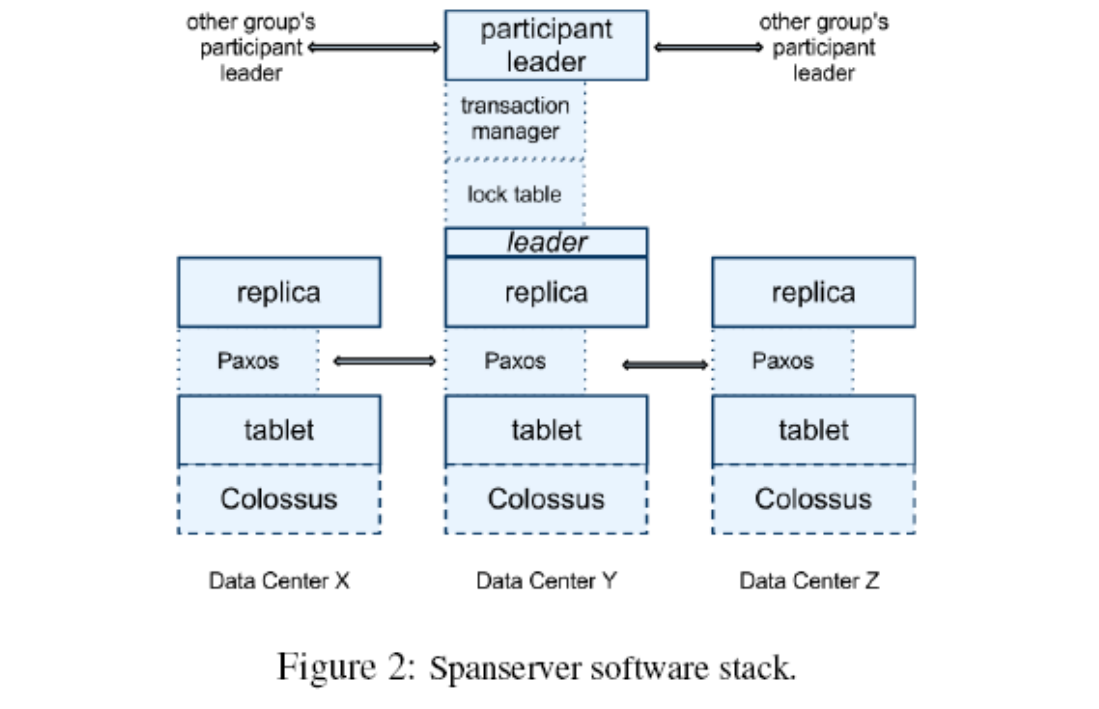
图 2 显示了软件栈。在底部,每个 spanserver 负载管理 100-1000 个称为 tablet 的数据结构的实例。一个 tablet 就类似于 BigTable 中的 tablet,也实现了下面 的映射: (key:string, timestamp:int64)->string.
与 BigTable 不同的是,Spanner 会把时间戳分配给数据,这种非常重要的方式,使得Spanner 更像一个多版本数据库,而不是一个键值存储。一个 tablet 的状态是存储在类似于 B-树的文件集合和写前(write-ahead)的日志中,所有这些都会被保存到一个分布式的文件系 统中,这个分布式文件系统被称为 Colossus,它继承自Google File System。
为了支持复制,每个 spanserver 会在每个 tablet 上面实现一个单个的 Paxos 状态机。一个之前实现的 Spanner 可以支持在每个 tablet 上面实现多个 Paxos 状态机器,它可以允许更 加灵活的复制配置,但是,这种设计过于复杂,被我们舍弃了。每个状态机器都会在相应的 tablet 中保存自己的元数据和日志。我们的 Paxos 实现支持采用基于时间的领导者租约的长 寿命的领导者,时间通常在 0 到 10 秒之间。当前的 Spanner 实现中,会对每个 Paxos 写操 作进行两次记录:一次是写入到 tablet 日志中,一次是写入到 Paxos 日志中。这种做法只是 权宜之计,我们以后会进行完善。我们在 Paxos 实现上采用了管道化的方式,从而可以在存 在广域网延迟时改进 Spanner 的吞吐量,但是,Paxos 会把写操作按照顺序的方式执行。
对于每个是领导者的副本而言,每个 spanserver 会实现一个锁表来实现并发控制。这个锁表包含了两阶段锁机制的状态:它把键的值域映射到锁状态上面。注意,采用一个长寿命 的 Paxos 领导者,对于有效管理锁表而言是非常关键的。在 BigTable 和 Spanner 中,我们都 专门为长事务做了设计,比如,对于报表操作,可能要持续几分钟,当存在冲突时,采用乐 观并发控制机制会表现出很差的性能。对于那些需要同步的操作,比如事务型的读操作,需 要获得锁表中的锁,而其他类型的操作则可以不理会锁表。
2.2 目录和放置
在一系列键值映射的上层,Spanner 实现支持一个被称为“目录”的桶抽象,也就是包含公共前缀的连续键的集合。一个目录是数据放置的基本单元。属于一个目录的所有数据,都具有相同的副本配置。当数据在不同的Paxos 组之间进行移动时,会一个目录一个目录地转移
一个 Paxos 组可以包含多个目录,这意味着一个 Spanner tablet 是不同于一个 BigTabletablet 的。一个 Spanner tablet 没有必要是一个行空间内按照词典顺序连续的分区,相反, 它可以是行空间内的多个分区。我们做出这个决定,是因为这样做可以让多个被频繁一起访 问的目录被整合到一起。
2.3 数据模型
基于模式化的半关系表的数据模型,查询语言和通用事务。支持这些特性的动机,是受到许多因素驱动的。需要支持模式化的半关 系表是由 Megastore[5]的普及来支持的.
应用的数据模型是架构在被目录桶装的键值映射层之上。一个应用会在一个 universe中创建一个或者多个数据库。每个数据库可以包含无限数量的模式化的表。每个表都和关系 数据库表类似,具备行、列和版本值.
S panner 的数据模型不是纯粹关系型的,它的行必须有名称。更准确地说,每个表都需要有包含一个或多个主键列的排序集合。这种需求,让 Spanner 看起来仍然有点像键值存储: 主键形成了一个行的名称,每个表都定义了从主键列到非主键列的映射。当一个行存在时, 必须要求已经给行的一些键定义了一些值(即使是NULL)。采用这种结构是很有用的,因为 这可以让应用通过选择键来控制数据的局部性。
4 并发控制
把 Spanner 客户端的写操作和 Paxos 看到的写操作这二者进行区分,是非常重要的,我们把 Paxos 看到的写操作称为 Paxos 写操作。例如,两阶段提交会为准备提交阶 段生成一个 Paxos 写操作,这时不会有相应的客户端写操作。
4.1 时间戳管理
Spanner 可以支持读写事务、只读事务(预先声明的快照隔离事务)和快照读。独立写操作,会被当成读写事务来执行。非快照独立读操 作,会被当成只读事务来执行。二者都是在内部进行 retry,客户端不用进行这种 retry loop。
1)一个只读事务具备快照隔离的性能优势
2)一个快照读操作,是针对历史数据的读取,执行过程中,不需要锁机制
3)对于只读事务和快照读而言,一旦已经选定一个时间戳,那么,提交就是不可避免的,除非在那个时间点的数据已经被垃圾回收了
4.1.1 Paxos 领导者租约
Spanner 的 Paxos 实现中使用了时间化的租约,来实现长时间的领导者地位(默认是 10秒)。一个潜在的领导者会发起请求,请求时间化的租约投票,在收到指定数量的投票后, 这个领导者就可以确定自己拥有了一个租约。一个副本在成功完成一个写操作后,会隐式地 延期自己的租约。对于一个领导者而言,如果它的租约快要到期了,就要显示地请求租约延 期.另一个领导者的租约有个时间区间,这个时间区间的起点就是这个领导者获得指定数量 的投票那一刻,时间区间的终点就是这个领导者失去指定数量的投票的那一刻(因为有些投 票已经过期了)。
Spanner 实现允许一个 Paxos 领导者通过把 slave 从租约投票中释放出来这种方式,实现 领导者的退位。为了保持这种彼此隔离的不连贯性,Spanner 会对什么时候退位做出限制。
4.1.2 为读写事务分配时间戳
事务读和写采用两段锁协议。当所有的锁都已经获得以后,在任何锁被释放之前,就可
以给事务分配时间戳。对于一个给定的事务,Spanner 会为事务分配时间戳,这个时间戳是 Paxos 分配给 Paxos 写操作的,它代表了事务提交的时间。
4.1.4 为只读事务分配时间戳
一个只读事务分成两个阶段执行:分配一个时间戳 sread[8],然后当成 sread时刻的快照读来执行事务读操作。快照读可以在任何足够新的副本上面执行。
5. 实验分析
我们对 Spanner 性能进行了测试,包括复制、事务和可用性。然后,我们提供了一些关
于 TrueTime 的实验数据,并且提供了我们的第一个用例——F1。 5.1 微测试基准 表 3 给出了一用于 Spanner 的微测试基准(microbenchmark)。这些测试是在分时机器上
实现的:每个 spanserver 采用 4GB内存和四核CPU(AMD Barcelona 2200MHz)。客户端运 行在单独的机器上。每个 zone 都包含一个 spanserver。客户端和 zone 都放在一个数据中心 集合内,它们之间的网络距离不会超过 1ms。这种布局是很普通的,许多数据并不需要把数 据分散存储到全球各地)。测试数据库具有 50 个 Paxos 组和 2500 个目录。操作都是独立的 4KB 大小的读和写。All reads were served out of memory after a compaction,从而使得我们只 需要衡量 Spanner 调用栈的开销。此外,还会进行一轮读操作,来预热任何位置的缓存。

















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









