







好用的教程
整体架构
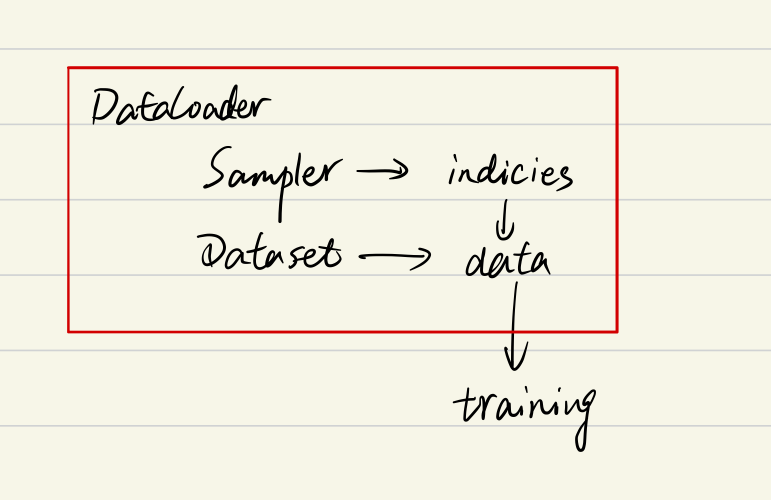
下文还有更加详细的流程,按执行顺序用数字进行了编号,使用debug进行了验证。
定义dataset
train_data = S3DIS(split='train', data_root=args.data_root,
test_area=args.test_area,
voxel_size=args.voxel_size, voxel_max=args.voxel_max,
transform=train_transform, shuffle_index=True, loop=args.loop)因为dataset是取一个sample的,这里的shuffle_index实际上是针对一个sample里的点是否需要打乱的。
loop是决定一个样本在一个epoch中重复多少次,比如loop为30的话,假如有一个样本a,他下标为3,共有50个样本,他会以3,53,103。。。的下标出现50个,这50个下标都是调用的该样本,因为idx%50都是得到3。
2.data sampler
根据dataset生成采样的下标,传给BatchSampler
DataLoader里的参数为shuffle,在使用默认data sampler时使用这个可以将index打乱
比如我有一个dataset,里面有10个点云场景。
那么data sampler先根据len(dataset)生成下标,比如我10个点云场景,loop为2(就是1个epoch所有样本重复两次),那么生成20个下标。
然后看看这20个是否需要打乱,如果要就打乱。
__iter__返回值为iter(indices) ,应该是每个第一层for也就是epoch都调用一次data sampler生成新的下标们。
DistributedSampler(data sampler可以指定为DistributedSampler,用于多个为进程分发数据)
我有两个进程,num_replicas=2,20条数据,每个进程10条数据,如果是21条数据,droplast每个进程10条数据(多的一个idx就不要了),不drop每个进程11条数据(随机补上一个idx)
切分数据是确定下标多少个之后进行的,比如我们21条数据不drop那就填充1条,之后
0,2,4,6个位置的下标进程0取到(按进程rank进行偏移)
1,3,5,7个位置的下标进程1取到(按进程rank进行偏移)
indices = indices[self.rank:self.total_size:self.num_replicas]
之后交给BatchSampler处理
3.BatchSampler
将data sampler得到的20个下标按batch_size进行分batch
DataLoader里的参数batch_size, drop_last作用与BatchSampler
drop_last的作用是在index无法被batch_size除尽时我应该如何操作,如果我batch为3,那么20个数据肯定没法均分,drop_last就砍成18个,就能均分,不drop就最后一个batch小一点

1个iter返回一个batch,比如这里就是(如果是灰度图像的话)[5,7,10]可以准备去取数据了
4.dataset的get item()
根据idx去寻找对应的样本,使用loop可能会超下标,所以要%样本总数
这里也可以进行数据的准备,因为可能一个样本我们肯定是要再处理一下才能使用的,也就是进行data_prepare
return coord, feat, label
返回各个数据
dataloader
返回迭代器,在一个epoch中,被第二层for调用,迭代器应该就是返回切分好的下标,每次返回一个batch(使用BatchSampler实现)。
此处写法
train_loader = torch.utils.data.DataLoader(train_data,
batch_size=args.batch_size, shuffle=(train_sampler is None),
num_workers=args.workers, pin_memory=False, sampler=train_sampler,
drop_last=True,
collate_fn=collate_fn)需要注意如果制定了data sampler,那么因为index给出和是否打乱是由data sampler决定的,我们这里shuffle就只能写false了。
drop_last是设置BatchSampler的参数,表示是否去掉最后的一个batch,因为最后batch可能内的样本数比其他的要少。 一般训练集为true
5.collate_fn
是对一次batch中所有数据进行加工,生成real_batch,是真实返回的值,也就是对该batch提取完后再进行一些统一的处理,输入的是1个或多个数组,取决于get item()的返回值
比如上面就是coord元组,batch为3的话coord就是大小为3的元组 ,collate_fn最终的返回数据可以自定,到时候for循环迭代的时候根据collate_fn接受就好了
默认collate_fn
batch:
[array([0.56998216, 0.72663738, 0.3706266 ]),
array([0.3403586 , 0.13931333, 0.71030221])]
返回real_batch要是
tensor([[0.5700, 0.7266, 0.3706],
[0.3404, 0.1393, 0.7103]], dtype=torch.float64)
这也说明了为什么每次dataloader得到的都是 tensor,在默认情况下collate_fn就是只有一个将batch转换为tensor的一个功能
6.for循环接收
第一层for是epoch,第二层才是batch的获取,底层就是对BatchSampler切分的下标进行迭代,生成数据。
__iter__返回值为iter(indices) ,应该是每个第一层for也就是epoch都调用一次data sampler生成新的下标们。
train和val的数据集的参数设置差异
dataset
train集可以设置loop,打乱内部点云,进行数据增强
val 集要保证数据和原始数据尽量一致,这样的统一标准才能用来评价性能好坏,和其他的方案比效果如何。
DistributedSampler都使用默认值,即打乱和不droplast,这里使用默认值即可(并行计算这里都使用默认值就行,对最终结果不影响)
DataLoader
trainloader droplast,
balloader 不droplast
我的理解是val集打乱随意(尽量不打乱)
原因是:1.train必须打乱,因为不打乱永远重复一个顺序,很容易过拟合并且泛化能力会很差
2.val集是否打乱并不会影响最终的结果
3.val集也不参加权重更新,所以不打乱也不会影响模型的参数,自然循序进行验证也是可以的。
但droplast必须加上
参考了
https://discuss.pytorch.org/t/shuffle-true-or-shuffle-false-for-val-and-test-dataloaders/143720















 4259
4259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









