







文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的动态,一起学习,共同进步。
相关文章:
第5章 分组聚合优化
示例SQL语句如下:
select
coupon_id,
count(*)
from dwd_trade_order_detail
where dt='2020-06-16'
group by coupon_id;5.1 优化前执行计划
5.2 优化思路
优化思路为map-side聚合。所谓map-side聚合,就是在map端维护一个hash table,利用其完成分区内的、部分的聚合,然后将部分聚合的结果,发送至reduce端,完成最终的聚合。map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率。
map-side 聚合相关的参数如下:
--启用map-side聚合
set hive.map.aggr=true;
--hash map占用map端内存的最大比例
set hive.map.aggr.hash.percentmemory=0.5;
--用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
--map-side聚合所用的HashTable,占用map任务堆内存的最大比例,若超出该值,则会对HashTable进行一次flush。
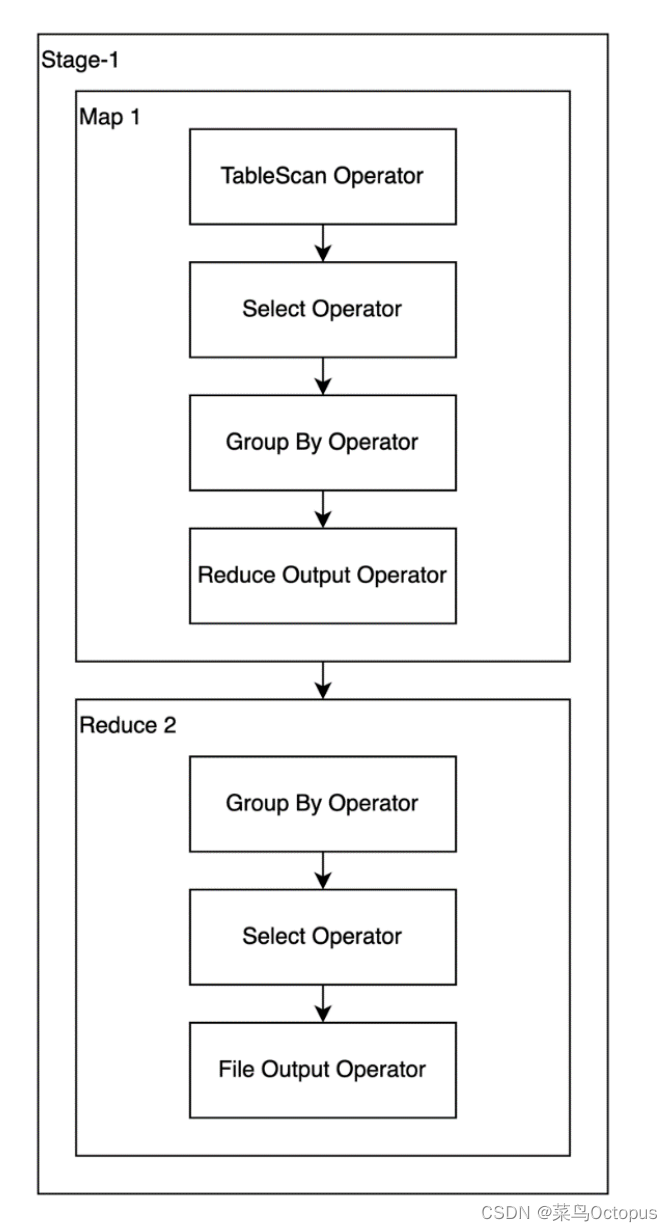
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;5.3 优化后执行计划















 2790
2790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









