







缘由
这是 K&R书中121页的一个例子,它本身使用来说明的C语言的
自引用结构的,但是我认为其涉及一个更为重要的问题:
二叉数。
故想以此将二叉数的内容也一并总结了吧。
故想以此将二叉数的内容也一并总结了吧。
分析问题
统计所有单词出现的次数的背景是:给出一篇文章,统计所有单词的数量。
这表示事先并不知道这些有哪些单词,便无法排序,更不要说使用查找了。
这表示事先并不知道这些有哪些单词,便无法排序,更不要说使用查找了。
- 书中指出:也不能分别对输入中的每个单词都执行一次线性查找,看其是否已经出现过。(程序执行的时间将会与输入单词的数量的二次方成比例)
- 折半查找的话,必须要将排序放入一个数组内(因为需要对下标进行计算),那样的话,新来的单词,即使我们找到它该存在的位置而没有它,我们打算将其插入数组,由会涉及数组元素的挪动,说到挪动,肯定是又要增加时间
- 顺序查找:那顺序查找为什么不可以呢?顺序查找可以用使用链表了了吧,我们只要在查找时找到这个新单词该出现的位置,没有找到它的话,那么我们再插入它,对于列表来说插入一个单词是非常方便的。当然,即使如此,查找的时间复杂度为O(n)
- 二叉数:如果使用二叉数来完成这个问题,我们将会得到更好的时间复杂度O(lgn),n为节点个数。也可以说,所花费的时间将会和树的高度成正比。二叉数的所有操作的时间复杂度都是这么多,包括插入、删除、建立、查找(来自:算法导论 第三版 第12章)。所以,对于一个单词而言,如果已经存放在了树中,那么就是查找,将新单词放入的就是插入。然而,实际上这两个动作应该是结合起来的,因为在其该在的位置找不到的时候,我们已经得到新单词该在的位置,所以直接插入即可。具体请看下面代码的实现。
使用二叉数,我们以字典顺序排序,为了更好的理解,我们构建的二叉数的节点大概是这样的:
对于这样一句话:now is the time for all good men to come to the aid of their party
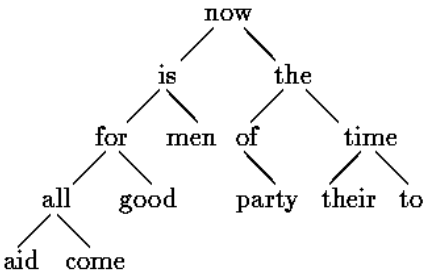
对于这样一句话:now is the time for all good men to come to the aid of their party
针对问题的数据结构
二叉数的数据结构中基本的有三个:
- 自身数据
- 左孩子
- 右孩子
我们该题中,自身数据就是单词,而且还需要多一个统计单词次数的数值。
code如下:
code如下:
struct tnode {
char *word;
int count;
struct tnode *left;
struct tnode *right;
};面对过程的流程以及代码
作为一般讲c语言的书,很显然是会用面向过程的思维方式来完成的,由下面的main函数可以具体的流程:
int main()
{
struct tnode *root;
char word[MAXWORD];
root = NULL;
while (getword(word, MAXWORD) != EOF)//读入一个单词
if (isalpha(word[0]))
root = addtree(root, word);//将单词加入到树中
treeprint(root);//打印树
return 0;
}struct tnode *addtree(struct tnode *p, char *w)
{
//判断是否是新节点
if (p == NULL) {
/* a new word has arrived */
p = talloc();
/* make a new node */
p->word = strdup1(w);//复制w的过程,如单纯的赋值,就会使p->word和w指向了一处。
p->count = 1;
p->left = p->right = NULL;
return p;
}
//不是新节点
int cond;
cond = strcmp(w, p->word);
if (cond== 0){
p->count++;/* repeated word */
}else if (cond < 0){//就到左子树去找
p->left = addtree(p->left, w);
}else{//就到右子树去找
p->right = addtree(p->right, w);
}
return p;
}
其中的两个函数的代码:
/* talloc: make a tnode */
/**
* 为新节点分配内存
*/
struct tnode *talloc(void)
{
return (struct tnode *) malloc(sizeof(struct tnode));
}
/**
* 完成对单词的复制,避免不同指针指向同一个单词,对单词产生干扰
*/
char *strdup1(char *s)
{
char *p;
/* make a duplicate of s */
p = (char *) malloc(strlen(s)+1); /* +1 for ’\0’ */
if (p != NULL)
strcpy(p, s);
return p;
}
读入单词
/* getword: get next word or character from input */
/**
* 没有调用高级的库函数使得这段代码略显复杂
* 但是这些基本的方式能够让我更深刻的体会了一些编程的高级技巧
*/
int getword(char *word, int lim)
{
int c, getch(void);
void ungetch(int);
char *w = word;
while (isspace(c = getch()))
;
if (c != EOF)
*w++ = c;
if (!isalpha(c)) {
*w = '\0';
return c;
}
for ( ; --lim > 0; w++){
if (!isalnum(*w = getch())) {
ungetch(*w);//读的最后一个要放回去,因为最后一个不是我们要要的,但是我们又已经读了
break;
}
}
*w = '\0';
return word[0];
}
#define BUFSIZE 100
char buf[BUFSIZE];
int bufp = 0;
/* buffer for ungetch */
/* next free position in buf */
int getch(void) /* get a (possibly pushed-back) character */
{
return (bufp > 0) ? buf[--bufp] : getchar();
}
void ungetch(int c)
/* push character back on input */
{
if (bufp >= BUFSIZE)
printf("ungetch: too many characters\n");
else
buf[bufp++] = c;
}打印结果
都快忘了
- 先序遍历:先根,再左,后右
- 中序遍历:先左,再根,后右
- 后序遍历:先左,再右,后中
/* treeprint: in-order print of tree p */
/**
* 递归打印,采用了中序遍历。
*/
void treeprint(struct tnode *p)
{
if (p != NULL) {
treeprint(p->left);
printf("%4d %s\n", p->count, p->word);
treeprint(p->right);
}
}
打印实例
就拿我们编写的代码作一个测试,结果如下,不能给中文做这样测试,因为中文里面的字都没有空格
zy@zy:~/Documents/eclipseWorkSpace/test/src$ ./a.out
1 EOF
3 MAXWORD
1 NULL
2 addtree
4 char
1 count
1 ctype
1 define
2 getword
4 h
1 if
4 include
4 int
1 isalpha
1 left
1 main
1 return
1 right
5 root
1 stdio
1 stdlib
1 string
7 struct
7 tnode
2 treeprint
1 void
1 while
5 word
zy@zy:~/Documents/eclipseWorkSpace/test/src$ 源代码
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#include <stdlib.h>
#define MAXWORD 100
struct tnode *addtree(struct tnode *, char *);
void treeprint(struct tnode *);
int getword(char *, int);
struct tnode {
char *word;
int count;
struct tnode *left;
struct tnode *right;
};
int main()
{
struct tnode *root;
char word[MAXWORD];
root = NULL;
while (getword(word, MAXWORD) != EOF)//读入一个单词
if (isalpha(word[0]))
root = addtree(root, word);//将单词加入到树中
treeprint(root);//打印树
return 0;
}
struct tnode *talloc(void);
char *strdup1(char *s);
struct tnode *addtree(struct tnode *p, char *w)
{
//判断是否是新节点
if (p == NULL) {
/* a new word has arrived */
p = talloc();
/* make a new node */
p->word = strdup1(w);//复制w的过程,如单纯的赋值,就会使p->word和w指向了一处。
p->count = 1;
p->left = p->right = NULL;
return p;
}
//不是新节点
int cond;
cond = strcmp(w, p->word);
if (cond== 0){
p->count++;/* repeated word */
}else if (cond < 0){//就到左子树去找
p->left = addtree(p->left, w);
}else{//就到右子树去找
p->right = addtree(p->right, w);
}
return p;
}
/* treeprint: in-order print of tree p */
/**
* 递归打印,采用了中序遍历。
*/
void treeprint(struct tnode *p)
{
if (p != NULL) {
treeprint(p->left);
printf("%4d %s\n", p->count, p->word);
treeprint(p->right);
}
}
/* talloc: make a tnode */
/**
* 为新节点分配内存
*/
struct tnode *talloc(void)
{
return (struct tnode *) malloc(sizeof(struct tnode));
}
/**
* 完成对单词的复制,避免不同指针指向同一个单词,对单词产生干扰
*/
char *strdup1(char *s)
{
char *p;
/* make a duplicate of s */
p = (char *) malloc(strlen(s)+1); /* +1 for ’\0’ */
if (p != NULL)
strcpy(p, s);
return p;
}
/* getword: get next word or character from input */
/**
* 没有调用高级的库函数使得这段代码略显复杂
* 但是这些基本的方式能够让我更深刻的体会了一些编程的高级技巧
*/
int getword(char *word, int lim)
{
int c, getch(void);
void ungetch(int);
char *w = word;
while (isspace(c = getch()))
;
if (c != EOF)
*w++ = c;
if (!isalpha(c)) {
*w = '\0';
return c;
}
for ( ; --lim > 0; w++){
if (!isalnum(*w = getch())) {
ungetch(*w);//读的最后一个要放回去,因为最后一个不是我们要要的,但是我们又已经读了
break;
}
}
*w = '\0';
return word[0];
}
#define BUFSIZE 100
char buf[BUFSIZE];
int bufp = 0;
/* buffer for ungetch */
/* next free position in buf */
int getch(void) /* get a (possibly pushed-back) character */
{
return (bufp > 0) ? buf[--bufp] : getchar();
}
void ungetch(int c)
/* push character back on input */
{
if (bufp >= BUFSIZE)
printf("ungetch: too many characters\n");
else
buf[bufp++] = c;
}
二叉数的删除问题
今天为此我又顺带复习了一下二叉数的一些问题,二叉树的几个基本的操作部分,我认为比较难的就是删除。
想不到算法导论还将其描述的有点复杂,所以我主要看了我考研时候一本书,个人觉得非常好: 2014版数据结构高分笔记(第2版),里面对此的描述比较清楚。
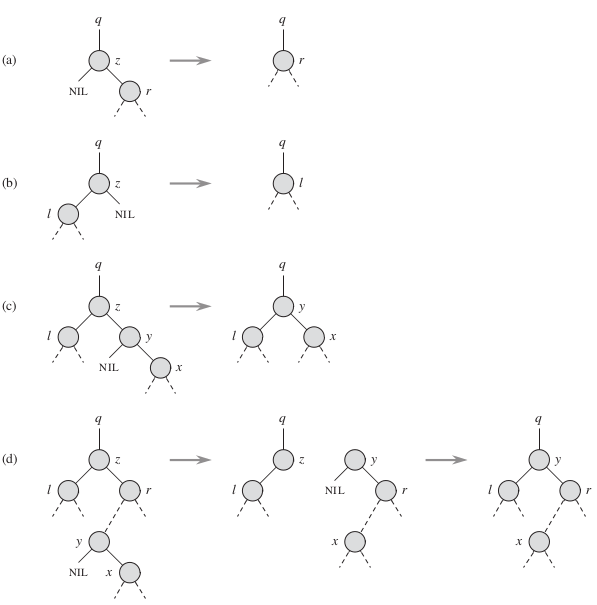
其中最复杂的就是情况(D):
假如要删除z,那么我们就先找到与z数值上最接近的节点,也就是从其右孩子一直往左走,就是上图中的y,然后将y与z对换,再删除对换后的z即可,x很容易判断该放在r的哪里。( 2014年6月10日:复习时,发现上面的说法和图中的画法不符合,图中的应该是实际上应该让Y成为r的父节点,然后再删除Z节点,再让Z子节点的左孩子成为Y的左孩子,Z节点的父节点成为Y的父节点即可)
想不到算法导论还将其描述的有点复杂,所以我主要看了我考研时候一本书,个人觉得非常好: 2014版数据结构高分笔记(第2版),里面对此的描述比较清楚。
其中最复杂的就是情况(D):
假如要删除z,那么我们就先找到与z数值上最接近的节点,也就是从其右孩子一直往左走,就是上图中的y,然后将y与z对换,再删除对换后的z即可,x很容易判断该放在r的哪里。( 2014年6月10日:复习时,发现上面的说法和图中的画法不符合,图中的应该是实际上应该让Y成为r的父节点,然后再删除Z节点,再让Z子节点的左孩子成为Y的左孩子,Z节点的父节点成为Y的父节点即可)
关于二叉树更深入的内容
- 虽然二叉树的各项操作的时间复杂度为O(lgN),但是在最坏的情况下还是O(n),那么可以进一步了解红黑树,它保证了在最坏的情况下的时间复杂是O(lgN)
- 此外还有B树,适用于二级磁盘储存器上的数据库维护
关于本题进一步扩展
刚买了unix环境高级编程,想看的慌,这三道题就留着以后做把
Exercise 6-2. Write a program that reads a C program and prints in alphabetical order each group of variable names that are identical in the first 6 characters, but different somewhere thereafter. Don’t count words within strings and comments. Make 6 a parameter that can be set from the command line.
Exercise 6-3. Write a cross-referencer that prints a list of all words in a document, and for each word, a list of the line numbers on which it occurs. Remove noise words like ‘‘the,’’ ‘‘and,’’ and so on.
Exercise 6-4. Write a program that prints the distinct words in its input sorted into decreasing order of frequency of occurrence. Precede each word by its count.
Exercise 6-3. Write a cross-referencer that prints a list of all words in a document, and for each word, a list of the line numbers on which it occurs. Remove noise words like ‘‘the,’’ ‘‘and,’’ and so on.
Exercise 6-4. Write a program that prints the distinct words in its input sorted into decreasing order of frequency of occurrence. Precede each word by its count.















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









