









缘由
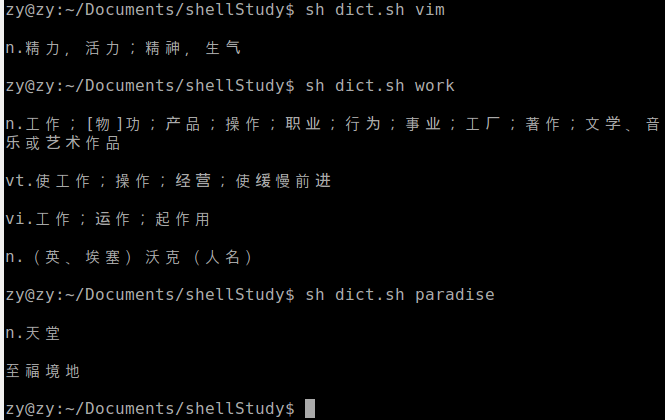
最近看了看linux shell 脚本攻略这本书,可以说是久仰大名,看了真是感慨万分。世间竟然有如此美妙的东西,我觉得前几天用了那么多java代码写出来的爬虫,如果用shell来写的,应该更不错!本人最难受的就是看了书之后那么好像会,其实不会的感觉。所以这次专门写了一个命令行的字典,用法非常简单,代码也不多。我们来看看效果,如下图:
shell代码
#!/bin/bash
#利用网易字典查询单词含义查询单词含义
curl http://dict.youdao.com/search?q=$1 --silent|\
awk 'NR==90,NR==120' |\
tr -d '\n '|\
sed 's:<\/li>:\n:g' |\
sed '/.*<li>\(.*\)/!d'|\
sed 's/.*<li>\(.*\).*/\n\1/g'
echo "\r"解释
- 我们用curl去把网页抓下来,为什么是:http://dict.youdao.com/search?q= ,仔细在浏览器上观察一下就知道了。后来的$1,就是我在运行这个脚本的第一个参数。
- --silent
表示不用输出下载的进度显示了。然后再用一个管道把内容传着走。 - wk 'NR==90,NR==120'
表示取文本中的90行到120.然后再用管道把这个90-120的内容传着走。 - tr -d '\n '
表示删除文本中的换行符和空格。这是由于sed每次都对一行一行的匹配的,所以我需要自己添加换行符,然后让我的模式去一行一行的匹配。 - sed 's:<\/li>:\n:g'
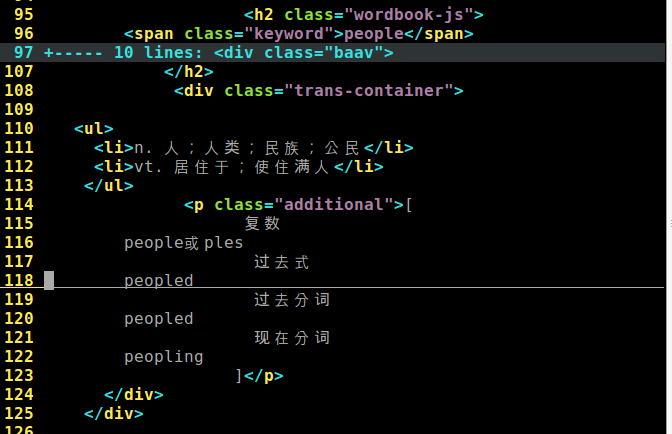
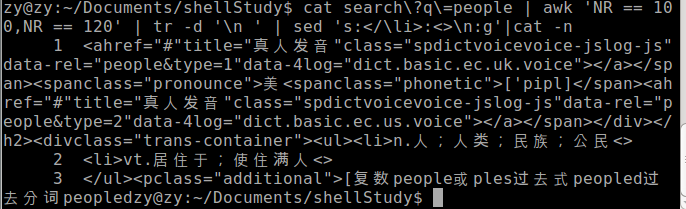
就是我自己添加的换行符,那么我把所有的</li>换成了换行符,如下图所示,我们可以在这个网页的源代码中发现其就这形式的。
- sed '/.*<li>\(.*\)/!d':
如下图所示,关键是要取出<li>和</li>之间的内容,所以如果没有<li>的这一行,我就删掉了。!d的意思就是删掉。也就是第三行
- sed 's/.*<li>\(.*\).*/\n\1/g':
对所有的行都作这个替换,()部分所匹配出子字符串,后面的\1就代码在()匹配出来的第一个子字符串,那么就是用<li>标记的内容替换了<li>和内容。所以能提取出我们需要的内容。 - echo "\r"
仅仅是为了看着舒服加了一个换行符而已。
进一步探索
用lynx
后来发现其实这个地方用curl并不是特别好,用lynx应该会更棒,因为这样会直接抓获所有的没有html标签的信息,如下图所示:我使用:
zy@zy:~/Documents/shellStudy$ lynx -dump http://dict.youdao.com/search?q=people >dict
zy@zy:~/Documents/shellStudy$ vim dict

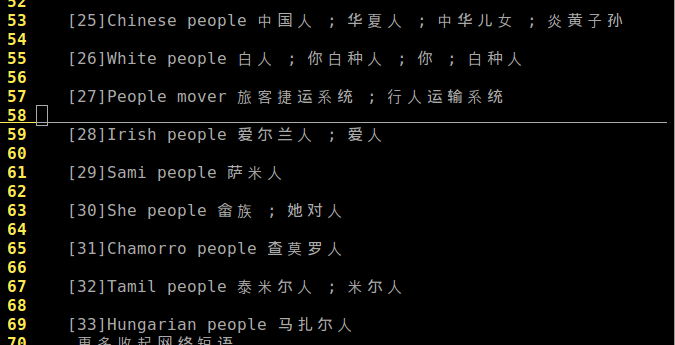
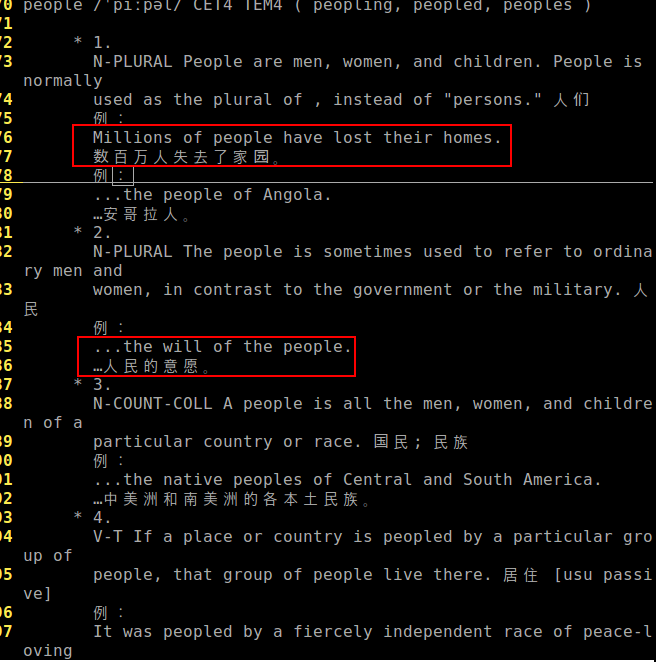
可以看到在获得例句和常用短语方面会更方便。















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









