







项目源码:https://download.csdn.net/download/zy_dreamer/88038658
项目内容截图:

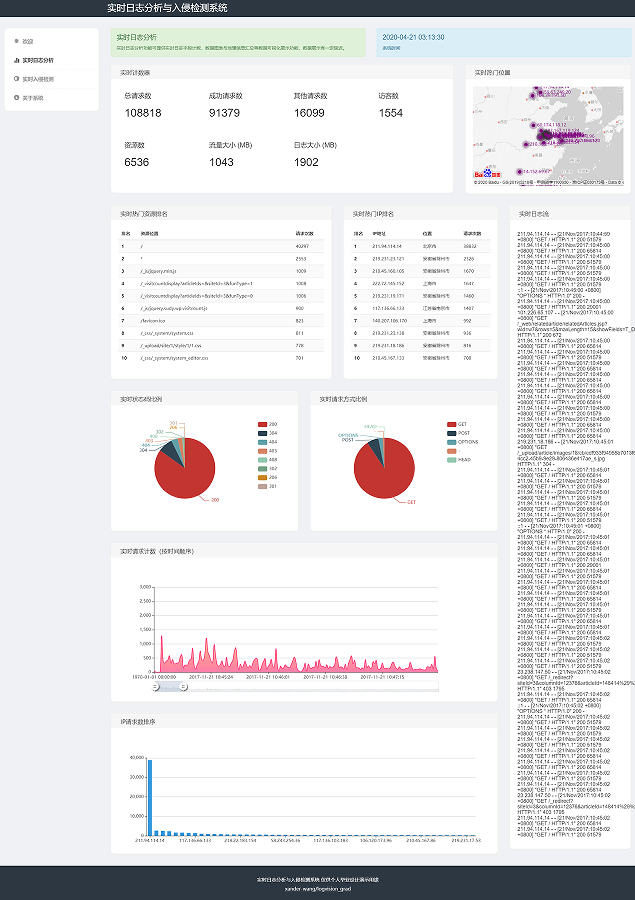
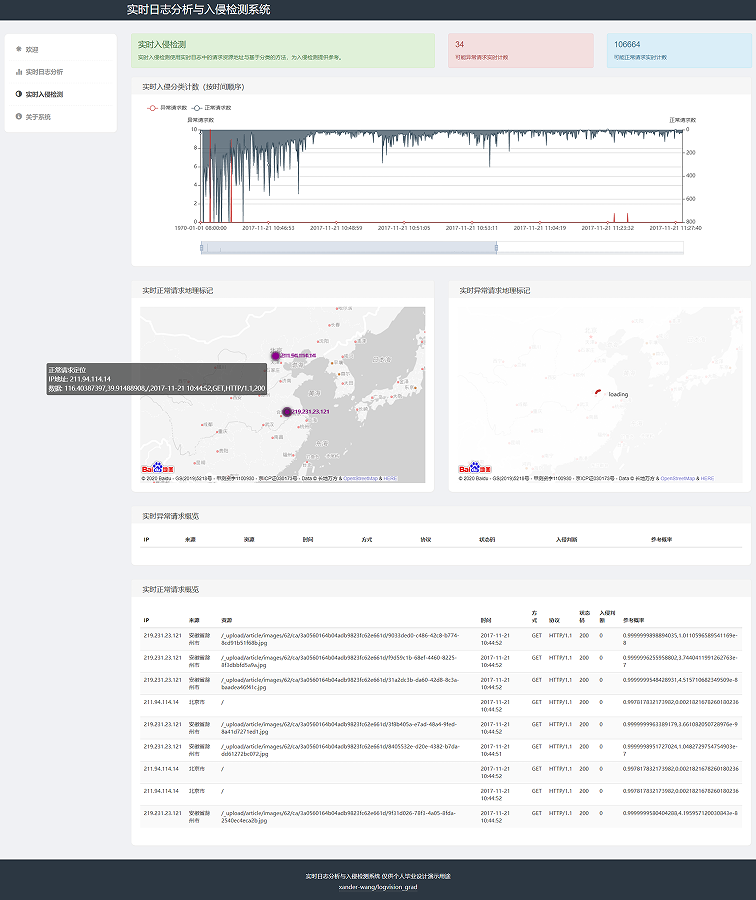
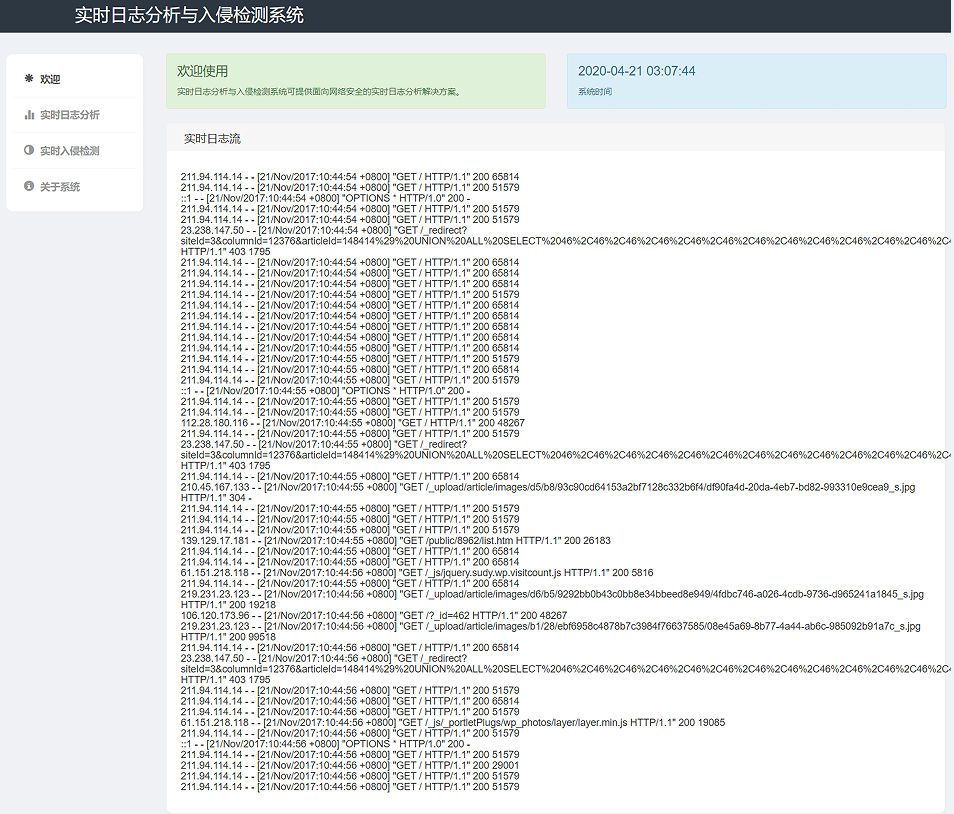
项目效果:
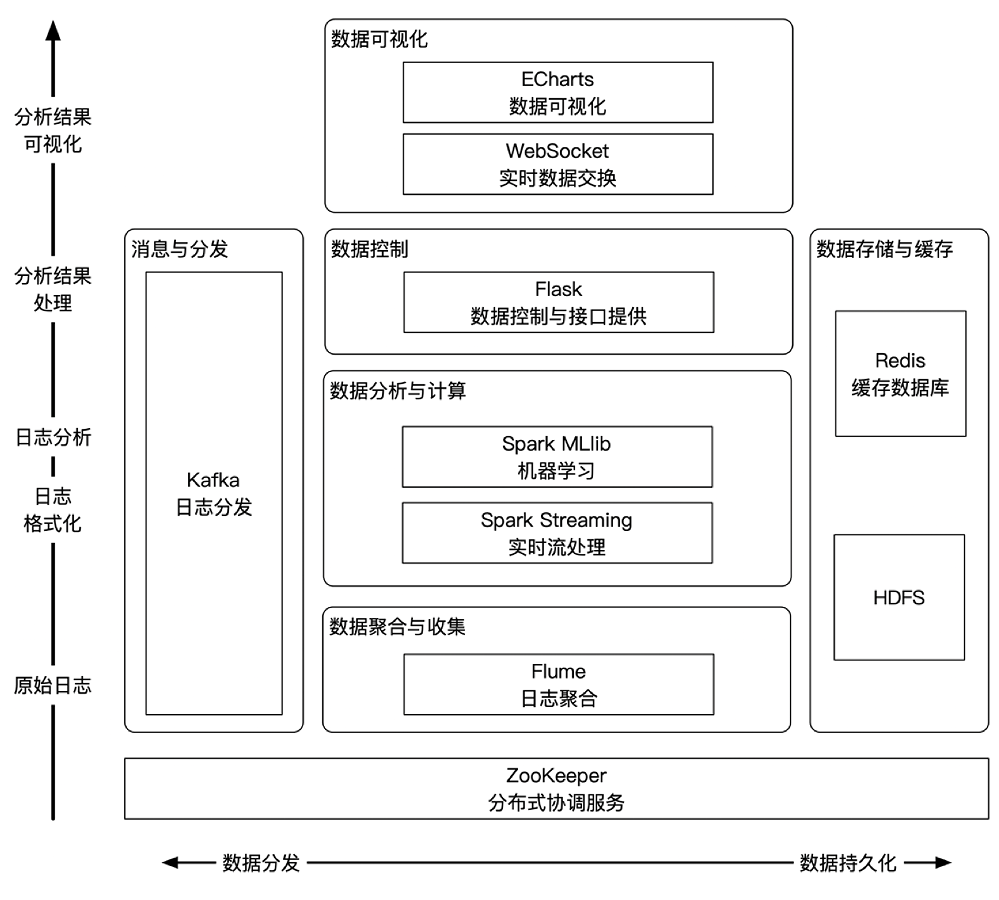
架构图:


简介
本项目是一个整合了web日志聚合、分发、实时分析、入侵检测、数据存储与可视化的日志分析解决方案。聚合采用Apache Flume,分发采用Apache Kafka,实时处理采用Spark Streaming,入侵检测采用Spark MLlib,数据存储使用HDFS与Redis,可视化采用Flask、SocketIO、Echarts、Bootstrap。
本文下述的使用方法均面向单机伪分布式环境,你可以根据需求进行配置上的调整以适应分布式部署。
本系统各模块由个人独立开发,期间参考了一些有价值的文献与资料。本系统还是个人的本科毕业设计。
获得的奖项:2019年全国大学生计算机设计大赛安徽省二等奖、2019年安徽省信息安全作品赛二等奖。
项目结构
-
flask:Flask Web后端
-
spark:日志分析与入侵检测的实现
-
flume:Flume配置文件
-
log_gen:模拟日志生成器
-
datasets:测试日志数据集
-
images:README的图片
依赖与版本
-
编译与Web端需要用到的:
-
Java 8, Scala 2.11.12, Python 3.8 (包依赖见requirements), sbt 1.3.8
-
-
计算环境中需要用到的:
-
Java 8, Apache Flume 1.9.0, Kafka 2.4, Spark 2.4.5, ZooKeeper 3.5.7, Hadoop 2.9.2, Redis 5.0.8
-
使用说明
在开始之前,你需要修改源码或配置文件中的IP为你自己的地址。具体涉及到flume配置文件、Spark主程序、Flask Web后端。
编译Spark应用
在安装好Java8与Scala11的前提下,在spark目录下,初始化sbt:
sbt
退出sbt shell并使用sbt-assembly对Spark项目进行编译打包:
sbt assembly
然后将生成的jar包重命名为logvision.jar。
环境准备
你需要一个伪分布式环境(测试环境为CentOS 7),并完成了所有对应版本组件依赖的配置与运行。 使用flume目录下的standalone.conf启动一个Flume Agent。 将datasets文件夹中的learning-datasets提交如下路径:
/home/logv/learning-datasets
将datasets文件夹中的access_log提交如下路径:
/home/logv/access_log
入侵检测模型训练与测试
提交jar包至Spark集群并执行入侵检测模型的生成与测试:
spark-submit --class learning logvision.jar
你将可以看到如下结果: 两个表格分别代表正常与异常数据集的入侵检测结果,下面四个表格可用于判断识别准确率。如图中所示250条正常测试数据被检测为250条正常,识别率100%;250条异常测试数据被检测为240条异常,10条正常,准确率96%。
启动可视化后端
在flask目录下执行如下命令,下载依赖包:
pip3 install -r requirements.txt
启动Flask Web:
python3 app.py
启动实时日志生成器
log_gen中的实时日志生成器可根据传入参数(每次写入行数、写入间隔时间)将样本日志中的特定行块追加至目标日志中,以模拟实时日志的生成过程,供后续实时处理。
java log_gen [日志源] [目标文件] [每次追加的行数] [时间间隔(秒)]
提交至环境,编译并运行,每2秒将/home/logv/access_log文件中的5行追加至/home/logSrc中:
javac log_gen.java java log_gen /home/logv/access_log /home/logSrc 5 2
启动分析任务
提交jar包至Spark集群并执行实时分析任务:
spark-submit --class streaming logvision.jar
查看可视化结果
至此你已经完成了后端组件的配置,通过浏览器访问Web端主机的5000端口可以查看到实时日志分析的可视化结果
Flask-python依赖:
Flask_SocketIO==4.3.0
requests==2.23.0
kafka_python==2.0.1
redis==3.5.0
flask==1.1.2
部分代码演示:
import ast
import time
from kafka import KafkaConsumer
import redis
import requests
from threading import Lock, Thread
from flask import Flask, render_template, session, request
from flask_socketio import SocketIO, emit
async_mode = None
app = Flask(__name__)
app.config['SECRET_KEY'] = 'secret!'
socketio = SocketIO(app, async_mode=async_mode)
thread = None
thread_lock = Lock()
# 配置项目
time_interval = 1
kafka_bootstrap_servers = "10.0.0.222:9092"
redis_con_pool = redis.ConnectionPool(host='10.0.0.222', port=6379, decode_responses=True)
# 页面路由与对应页面的ws接口
# 系统时间
@socketio.on('connect', namespace='/sys_time')
def sys_time():
def loop():
while True:
socketio.sleep(time_interval)
current_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
socketio.emit('sys_time',
{'data': current_time},
namespace='/sys_time')
socketio.start_background_task(target=loop)
# 欢迎页面
@app.route('/')
@app.route('/welcome')
def welcome():
return render_template('index.html', async_mode=socketio.async_mode)
# 实时日志流
@socketio.on('connect', namespace='/log_stream')
def log_stream():
def loop():
socketio.sleep(time_interval)
consumer = KafkaConsumer("raw_log", bootstrap_servers=kafka_bootstrap_servers)
cache = ""
for msg in consumer:
cache += bytes.decode(msg.value) + "\n"
if len(cache.split("\n")) == 25:
socketio.emit('log_stream',
{'data': cache},
namespace='/log_stream')
cache = ""
socketio.start_background_task(target=loop)
# 实时日志分析页面
@app.route('/analysis')
def analysis():
return render_template('analysis.html', async_mode=socketio.async_mode)
# 实时计数器
@socketio.on('connect', namespace='/count_board')
def count_board():
def loop():
while True:
socketio.sleep(time_interval)
redis_con = redis.Redis(connection_pool=redis_con_pool)
res = redis_con.zrange("statcode", 0, 40, withscores=True)
# 总请求数(日志行数)
host_count = redis_con.zscore("line", "count")
# 成功请求数(状态码属于normal的个数)
normal = ["200", "201", "202", "203", "204", "205", "206", "207"]
success_count = 0
for i in res:
if i[0] in normal:
success_count += int(i[1])
# 其他请求数(其他状态码个数)
other_count = 0
for i in res:
other_count += int(i[1])
other_count -= success_count
# 访客数(不同的IP个数)
visitor_count = redis_con.zcard("host")
# 资源数(不同的url个数)
url_count = redis_con.zcard("url")
# 流量大小(bytes的和,MB)
traffic_sum = int(redis_con.zscore("traffic", "sum"))
# 日志大小(MB)
log_size = int(redis_con.zscore("size", "sum"))
socketio.emit('count_board',
{'host_count': host_count,
'success_count': success_count,
'other_count': other_count,
'visitor_count': visitor_count,
'url_count': url_count,
'traffic_sum': traffic_sum,
'log_size': log_size},
namespace='/count_board')
socketio.start_background_task(target=loop)
# 实时热门位置
@socketio.on('connect', namespace='/hot_geo')
def hot_geo():
def loop():
while True:
socketio.sleep(2)
redis_con = redis.Redis(connection_pool=redis_con_pool)
res = redis_con.zrevrange("host", 0, 50, withscores=True)
data = []
for i in res:
# 调用接口获取地理坐标
req = requests.get("http://api.map.baidu.com/location/ip",
{'ak': '0jKbOcwqK7dGZiYIhSai5rsxTnQZ4UQt',
'ip': i[0],
'coor': 'bd09ll'})
body = eval(req.text)
# 仅显示境内定位
if body['status'] == 0:
coor_x = body['content']['point']['x']
coor_y = body['content']['point']['y']
data.append({"name": i[0], "value": [coor_x, coor_y, i[1]]})
socketio.emit('hot_geo',
{'data': data},
namespace='/hot_geo')
socketio.start_background_task(target=loop)
# 实时热门资源排名
@socketio.on('connect', namespace='/hot_url')
def hot_url():
def loop():
while True:
socketio.sleep(time_interval)
redis_con = redis.Redis(connection_pool=redis_con_pool)
res = redis_con.zrevrange("url", 0, 9, withscores=True)
data = []
no = 1
for i in res:
data.append({"no": no, "url": i[0], "count": i[1]})
no += 1
socketio.emit('hot_url',
{'data': data},
namespace='/hot_url')
socketio.start_background_task(target=loop)
# 实时热门IP排名
@socketio.on('connect', namespace='/hot_ip')
def hot_ip():
def loop():
while True:
socketio.sleep(time_interval)
redis_con = redis.Redis(connection_pool=redis_con_pool)
res = redis_con.zrevrange("host", 0, 13, withscores=True)
data = []
no = 1
for i in res:
# 调用接口获取地理坐标
req = requests.get("http://api.map.baidu.com/location/ip",
{'ak': '0jKbOcwqK7dGZiYIhSai5rsxTnQZ4UQt',
'ip': i[0],
'coor': 'bd09ll'})
body = eval(req.text)
# 仅显示境内定位
if body['status'] == 0:
address = body['content']['address']
data.append({"no": no, "ip": i[0], "address": address, "count": i[1]})
no += 1
socketio.emit('hot_ip',
{'data': data},
namespace='/hot_ip')
socketio.start_background_task(target=loop)
# 实时状态码比例
@socketio.on('connect', namespace='/status_code_pie')
def status_code_pie():
def loop():
while True:
socketio.sleep(time_interval)
redis_con = redis.Redis(connection_pool=redis_con_pool)
res = redis_con.zrevrange("statcode", 0, 100, withscores=True)
data = []
legend = []
for i in res:
if i[0] != 'foo':
data.append({"value": i[1], "name": i[0]})
legend.append(i[0])
socketio.emit('status_code_pie',
{'legend': legend, 'data': data},
namespace='/status_code_pie')
socketio.start_background_task(target=loop)
# 实时请求方式比例
@socketio.on('connect', namespace='/req_method_pie')
def req_method_pie():
def loop():
while True:
socketio.sleep(time_interval)
redis_con = redis.Redis(connection_pool=redis_con_pool)
res = redis_con.zrevrange("reqmt", 0, 100, withscores=True)
data = []
legend = []
for i in res:
if i[0] != 'foo':
data.append({"value": i[1], "name": i[0]})
legend.append(i[0])
socketio.emit('req_method_pie',
{'legend': legend, 'data': data},
namespace='/req_method_pie')
socketio.start_background_task(target=loop)
# 实时请求计数(按时间顺序)
@socketio.on('connect', namespace='/req_count_timeline')
def req_count_timeline():
def loop():
while True:
socketio.sleep(time_interval)
redis_con = redis.Redis(connection_pool=redis_con_pool)
res = dict(redis_con.zrange("datetime", 0, 10000000, withscores=True))
data = []
date = []
# 按时间排序
for i in sorted(res):
datetime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(int(i) / 1000))
data.append(res[i])
date.append(datetime)
socketio.emit('req_count_timeline',
{"data": data, "date": date},
namespace='/req_count_timeline')
socketio.start_background_task(target=loop)
# IP请求数排序
@socketio.on('connect', namespace='/ip_ranking')
def timestamp_count_timeline():
def loop():
while True:
socketio.sleep(time_interval)
redis_con = redis.Redis(connection_pool=redis_con_pool)
res = redis_con.zrevrange("host", 0, 50, withscores=True)
ip = []
count = []
for i in res:
ip.append(i[0])
count.append(i[1])
socketio.emit('ip_ranking',
{"ip": ip, "count": count},
namespace='/ip_ranking')
socketio.start_background_task(target=loop)
@app.route('/id')
def id():
return render_template("id.html", async_mode=socketio.async_mode)
# 异常请求计数
@socketio.on('connect', namespace='/bad_count')
def bad_count():
def loop():
while True:
socketio.sleep(time_interval)
redis_con = redis.Redis(connection_pool=redis_con_pool)
res = int(redis_con.zscore("bad", "bad"))
socketio.emit('bad_count',
{"data": res},
namespace='/bad_count')
socketio.start_background_task(target=loop)
# 正常请求计数
@socketio.on('connect', namespace='/good_count')
def bad_count():
def loop():
while True:
socketio.sleep(time_interval)
redis_con = redis.Redis(connection_pool=redis_con_pool)
res = int(redis_con.zscore("good", "good"))
socketio.emit('good_count',
{"data": res},
namespace='/good_count')
socketio.start_background_task(target=loop)
# 正常请求地理标记
@socketio.on('connect', namespace='/good_geo')
def good_geo():
def loop():
while True:
socketio.sleep(time_interval)
consumer = KafkaConsumer("good_result", bootstrap_servers=kafka_bootstrap_servers)
data = []
for msg in consumer:
result = ast.literal_eval(bytes.decode(msg.value))
for record in result:
if record['host'] != "foo":
# 调用接口获取地理坐标
req = requests.get("http://api.map.baidu.com/location/ip",
{'ak': '0jKbOcwqK7dGZiYIhSai5rsxTnQZ4UQt',
'ip': record['host'],
'coor': 'bd09ll'})
body = eval(req.text)
# 仅显示境内定位
if body['status'] == 0:
coor_x = body['content']['point']['x']
coor_y = body['content']['point']['y']
datetime = time.strftime("%Y-%m-%d %H:%M:%S",
time.localtime(int(record['timestamp']) / 1000))
data.append({"name": record['host'], "value": [coor_x, coor_y,
record['url'],
datetime,
record['req_method'],
record['protocol'],
record['status_code']]})
socketio.emit('good_geo',
{"data": data},
namespace='/good_geo')
socketio.start_background_task(target=loop)
说明:当前文章或代码如侵犯了您的权益,请私信作者删除!















 1105
1105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











