







转自http://blog.csdn.net/shuzfan/article/details/52662384?locationNum=12
本次介绍人脸检测方法Faster R-CNN:
《2016 Arxiv: Face Detection with the Faster R-CNN》.
上面这篇文章,是对Faster R-CNN的人脸检测实现,原始的Faster R-CNN实现的是多目标检测,即下面这篇文章:
《2015 CVPR: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》.
核心导读:
RPN(Region Proposal Networks) + Fast R-CNN
RPN负责找到可能的目标窗口,R-CNN负责进一步判断目标。
因为讲解Faster R-CNN的文章已经很多了,所以我这里就快速的切入几个要点。
———————————— RPN ————————————
RPN负责从一副输入图像中选出一些候选目标窗口,它的作用和古老的“Sliding Window”(滑动窗口)类似,但后者通常会在一幅图像上产生数以万计的窗口。
下面给出RPN的示意图:
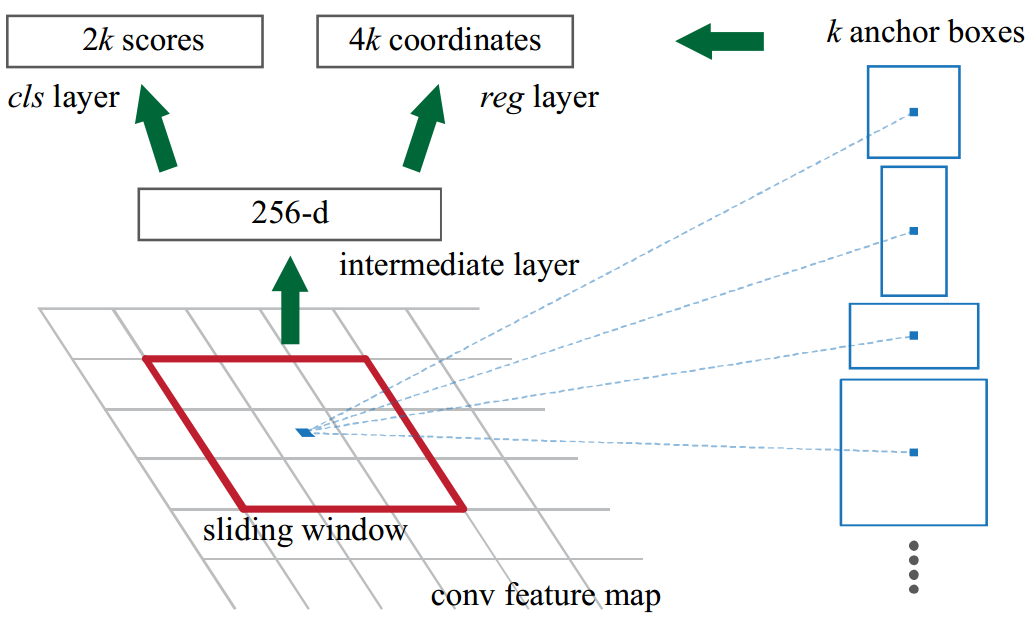
输入: 一幅图像,尺寸 M×600 , 即resize使得最短边为600.
中间输出: conv feature map,大小 m×n 。在该feature map上以 3×3 滑窗,为了检测不同形状的窗口,这里每一个滑动窗口代表了可能的k=9种实际窗口(分别是3种不同尺度和3种不同宽高比)。每一个实际窗口,我们都称之为anchor。
最终输出: 一是:classifier score map,大小为
m× n×2×k
,表示每一个窗口是或是不是目标的概率;
二是:regression map, 大小为
m× n×4×k
,表示每一个窗口所回归出来的四个坐标
[x,y,w,h]
Test的时候,我们可以根据score map以一定阈值选出候选窗口,然后以regression map来修正这些候选框。
显然,RPN的Loss包含了两个部分,分别是分类和回归:
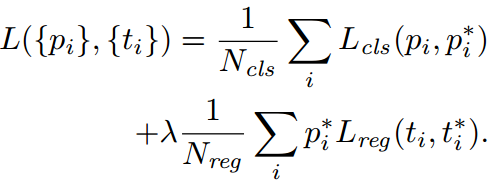
其中, pi 是第 i 个anchor属于目标的概率。
———————————— Faster R-CNN ————————————
现在给出整体的结构图:
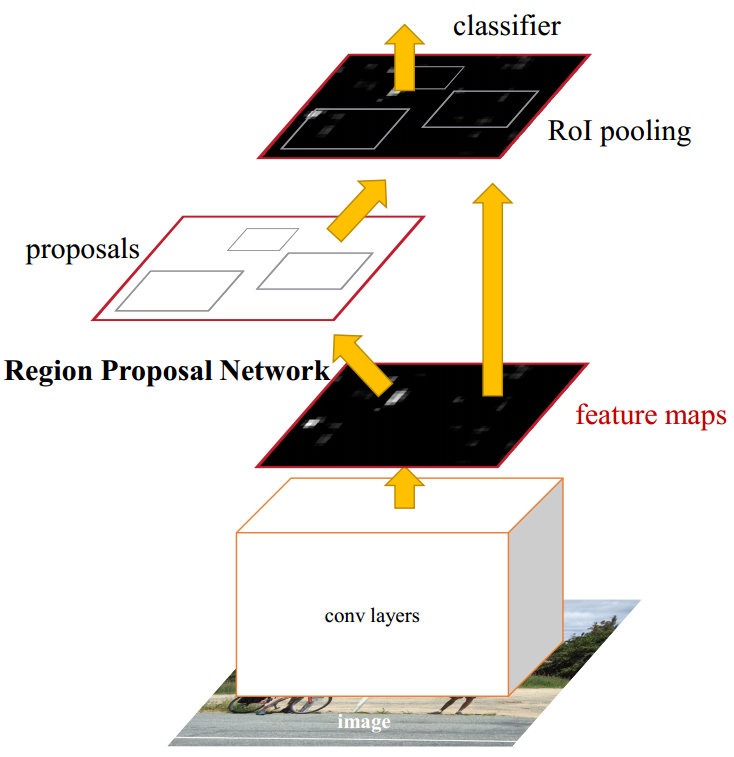
由上图可以看出,RPN负责提供候选窗口,R-CNN负责对这些窗口做进一步判断,一共是先后的两部分。
而且,两部分共用前面的所有的层,这样就通过参数共享大大减少了模型大小,从而提高了速度。
最后做目标确认的时候,使用了ROI-Pooling方法,即只pooling目标区域。
———————————— 训练策略 ————————————
另外还需要注意的就是训练策略了。
论文最终采用了“Alternating training”的训练策略,分为4阶段:
(1)训练RPN;
(2) 利用RPN产生的候选窗口来训练R-CNN;
(3)在(2)的基础上训练再次RPN,只不过保持共享层不训练;
(4)在(3)的基础上训练R-CNN分支,同时保持其它层不变。















 6688
6688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









