






 文章介绍了一种新型的多被试视觉神经信息解码方法,CLIP-MUSED,它利用CLIP表征空间的拓扑关系引导神经表征学习,克服了现有方法的局限性,特别是在处理个体差异和全局特征提取上。实验证明其在多个数据集上表现优于单被试和传统多被试解码模型。
文章介绍了一种新型的多被试视觉神经信息解码方法,CLIP-MUSED,它利用CLIP表征空间的拓扑关系引导神经表征学习,克服了现有方法的局限性,特别是在处理个体差异和全局特征提取上。实验证明其在多个数据集上表现优于单被试和传统多被试解码模型。

在视觉神经信息解码研究中,由于个体差异较大,单被试解码模型难以泛化到其他被试上去。此外,由于数据采集时长的限制,单个被试可获取的数据量有限。为了避免模型训练出现过拟合,模型的复杂度受到限制。现有的多被试解码方法往往难以提取神经响应的全局特征,并且模型参数量会随被试个数线性增长,同时也没有充分刻画不同被试在不同刺激下的神经响应的关系。
为了克服现有方法的局限性,中科院自动化所的周琼怡、杜长德等人提出了一种大模型引导的多被试视觉神经信息语义解码方法,该方法利用视觉刺激在CLIP表征空间的拓扑关系,引导多被试神经表征的学习。相关论文已被国际顶级会议ICLR 2024接受。结果表明,本文提出的模型的分类结果优于单被试解码模型和其他多被试解码模型。一系列可视化分析结果也解释了本方法的有效性。

论文地址:https://openreview.net/forum?id=lKxL5zkssv
代码地址:https://github.com/CLIP-MUSED/CLIP-MUSED
01
研究背景
与单被试解码方法不同,多被试解码方法在训练阶段能够通过聚合多被试的数据起到数据增广的效果,不仅能够缓解过拟合问题,而且可以增加模型复杂度以提升模型的表达能力。在不同被试上测试时,多被试解码方法均能取得较好的性能。因此,研究多被试神经信息解码方法具有重要价值。
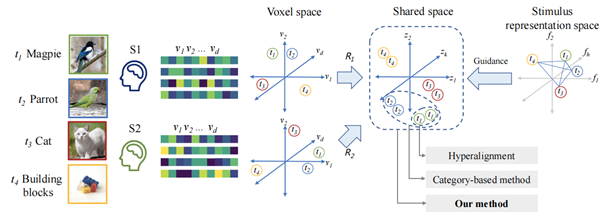
多被试解码研究需要考虑个体差异,主要包括解剖差异和功能差异。解剖对齐是 fMRI 数据预处理流程中必不可少的环节。解剖对齐之后,被试间仍然存在功能拓扑的差异,即不同被试的功能区的大小、形状和在皮层上的位置存在差异。在经过解剖对齐预处理的fMRI 数据集上,功能拓扑差异是导致单被试解码方法难以泛化到其他被试上去的主要原因。因此,多被试解码研究中的关键问题是不同被试的功能拓扑对齐。
已有的多被试解码研究大多是基于超对齐(Hyperalignment)方法进行被试间的功能拓扑对齐。超对齐方法将神经响应从体素空间映射到共享空间,并在该空间通过拉近不同被试在相同刺激下或者同类刺激下的神经响应表征。
然而,这些方法仍然存在三方面的局限性:
1、已有研究对体素空间到共享空间的映射函数进行优化,包括线性变换、多层感知器(MLP) 和 CNN等。但这些映射函数均存在各自的局限性:线性变换的表达能力十分有限;线性变换和MLP 都不能很好地适用于体素个数非常多的情况;CNN 只建模局部信息,难以提取神经响应的全局特征。
2、已有研究需要为每个被试学习映射函数,当被试数量增多时,模型参数量会随之线性增长,计算开支也将大幅上升。
3、已有研究均没有对不同被试在相似刺激下的神经响应的关系进行充分的刻画。事实上,不同被试在语义相近的视觉刺激下会产生相似的神经响应。例如上图中,猫和积木虽然都不属于鸟类,但在语义空间上,鸟和猫同属于动物,是相关的概念,而积木是非生命物体,与猫和鸟的关联性较弱。在共享空间中,不同被试在不同刺激下的神经响应表征的相似关系应该能够反映不同刺激间的语义相似关系。
针对以上问题,本文创新性地提出CLIP-MUSED多被试解码方法。相比线性变换、MLP 和 CNN,Transformer 模型能够借助自注意力操作,建立起所有数据切块之间的关联,具有很强的全局特性。因此,本方法设计Transformer 模型作为从体素空间到共享空间的映射函数。其次,本方法通过在 Transformer 中引入被试独有的 Token,来编码个体差异。除此之外,模型的其他参数被所有被试共享。当被试个数增多时,模型只需要为新被试学习新的 Token。另外,本方法用视觉刺激在 CLIP表征空间的拓扑关系引导被试共享空间的表征学习。
02
CLIP-MUSED
CLIP引导的多被试视觉神经信息语义解码模型
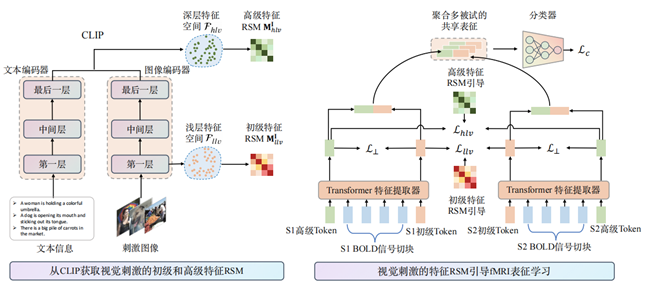
如图所示,首先从预训练的CLIP模型中获取视觉刺激的初级和高级特征,并计算表征相似性矩阵(RSM)。其次,用基于Transformer的特征提取器提取被试的BOLD信号特征。Transformer 模型能够非常灵活地添加 Token,在此本方法为每个被试学习一个初级Token和一个高级Token,以编码个体差异。当被试个数增多时,模型只需要为新被试学习新的 Token。初级和高级Token经过Transformer特征提取后得到初级和高级神经表征。通过表征相似性分析(RSA),将视觉刺激在CLIP特征空间和神经响应表征空间中的拓扑关系对齐。为了鼓励编码不同信息,本方法在初级和高级神经表征上施加了正交约束。最终,CLIP-MUSED模型的损失函数是多被试视觉语义分类损失、RSA损失和正交约束的加权组合。
03
实验结果
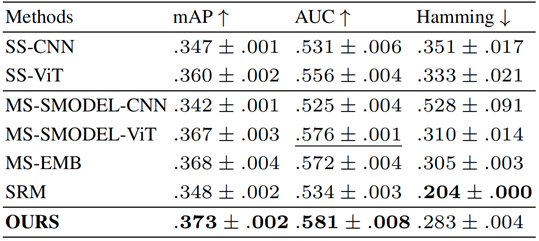
本文用两个大脑 fMRI 数据集HCP和NSD来验证本方法的有效性。结果如下表所示,其中前缀为SS和MS的方法分别是单被试和多被试解码方法,SRM是较为传统的超对齐方法。可见,在两个数据集上,CLIP-MUSED方法相比于单被试解码方法和多被试解码方法均存在优势。
HCP数据集:
NSD数据集:
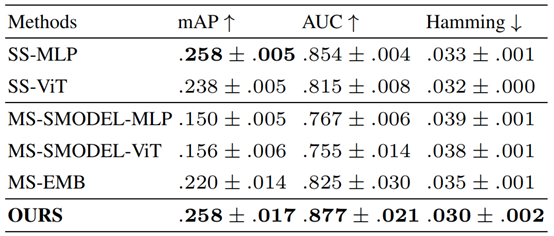
本文还对比了视觉刺激在不同的 DNN 表征空间中的拓扑关系做引导时的模型性能,对照组包括ViT、AlexNet、CLIP图像编码器、CLIP文本编码器。结果如下表所示。可见, CLIP 提取的表征做引导能够取得比 单模态的CLIP 图像表征、文本表征和普通 DNN 特征更好的效果,体现了图文多模态特征的优势。

在 Transformer 模型中,指定查询 Token,可获取该 Token 在所有 Token 上的注意力分布,即注意力图。在本应用中,指定查询 Token 为初级或高级 Token,注意力图反映了 Token 在表征学习过程中重点关注了哪些脑区。本文可视化了模型最后一层的自注意力层上,初级和高级 Token 的注意力图。下图是HCP数据集上,随机抽取的四个被试上,初级Token(a)和高级Token(b)的注意力图。
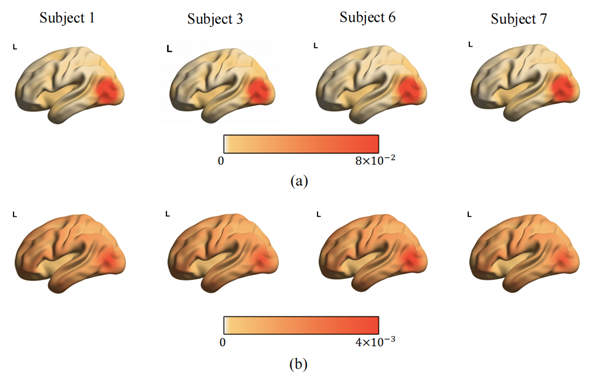
与初级 Token 相比,高级Token 的注意力在皮层上的分布则更为分散,在额叶、顶叶区域均分配了较强的注意力。已有研究表明,视觉刺激的初级特征加工过程集中在视皮层完成,而高级语义特征的加工涉及颞叶、顶叶和额叶。由此可见,本方法的初级 Token和高级 Token 较好地编码了被试对视觉刺激的初级特征和高级特征的响应模式,与本研究最初的预期一致。
综上,针对不同被试个体差异较大的问题,本文提出了一种CLIP引导的多被试语义解码方法。本方法设计了基于 Transformer 的 fMRI 特征提取器,通过自注意力机制捕获不同脑区的 fMRI 信号间的联系,从而提取神经响应的全局特征。此外,方法为模型引入被试特异的初级和高级 Token,分别用来表征该被试对视觉刺激的初级和高级特征的响应模式。方法所引入的 Token 提升了训练模型的可用数据量,将 Transformer 模型的强大表征能力得到充分发挥。初级Token 和高级 Token 在自注意力网络中与不同脑区的神经信号进行交互,得到对应的表征,该表征最终被用于多被试语义解码。基于表征相似性分析,本方法用视觉刺激在图文预训练模型表征空间的拓扑关系引导 Token 的表征学习。在两个大脑视皮层 fMRI 数据集上,本方法能够适用于多个被试的语义解码,且性能优于单被试解码和多被试解码方法。
本方法在实际应用中有两点优势:首先,除了需要为每个被试学习两个 Token 之外,本方法的其他参数被所有被试共享,因此本方法可以拓展到被试数更多的应用场景中去。其次,本方法适用于多被试刺激不相同的情况,在不同被试的刺激图像完全互斥的情况下,模型的性能依然优于单被试解码模型。因此,在未来,本方法可以用于聚合多个数据集进行模型训练。
本论文第一作者是中科院自动化所周琼怡博士,第二作者是杜长德副研究员,汪胜佩副研究员也参与了研究,何晖光研究员为通讯作者。研究工作得到了科技部生物与信息融合(BT与IT融合)重点专项、基金委项目、以及CAAI-华为MindSpore学术奖励基金及智能基座等项目的支持。
—— End ——
仅用于学术分享,若侵权请留言,即时删侵!

投稿请点击 脑机接口社区学术新闻投稿指南
加入社群
欢迎加入脑机接口社区交流群,
探讨脑机接口领域话题,实时跟踪脑机接口前沿。
加微信群:
添加微信:RoseBrain【备注:姓名+行业/专业】。
加QQ群:913607986
欢迎来稿
1.欢迎来稿。投稿咨询,请联系微信:RoseBrain
投稿请点击 脑机接口社区学术新闻投稿指南
2.加入社区成为兼职创作者,请联系微信:RoseBrain



一键三连「分享」、「点赞」和「在看」
不错每一条脑机前沿进展 ~


















 1692
1692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











